







 本文介绍了SparkUI界面的工作原理,强调了事件监听机制在大型分布式系统中的重要性,避免了同步调用导致的线程阻塞问题。SparkUI通过DAGScheduler产生事件,经listenerBus分发到各个监听器进行异步处理,更新监控数据并在界面展示。此外,文章详细讲解了SparkUI的配置参数、组件结构和初始化过程。
本文介绍了SparkUI界面的工作原理,强调了事件监听机制在大型分布式系统中的重要性,避免了同步调用导致的线程阻塞问题。SparkUI通过DAGScheduler产生事件,经listenerBus分发到各个监听器进行异步处理,更新监控数据并在界面展示。此外,文章详细讲解了SparkUI的配置参数、组件结构和初始化过程。
1.美图

前言
在大型分布式系统中,采用事件监听机制是最常见的。为什么要使用事件监听机制?假如SparkUI采用Scala的函数调用方式,那么随着整个集群规模的增加,对函数的调用会越来越多,最终会受到Driver所在JVM的线程数量限制而影响监控数据的更新,甚至出现监控数据无法及时显示给用户的情况。由于函数调用多数情况下是同步调用,这就导致线程被阻塞,在分布式环境中,还可能因为网络问题,导致线程被长时间占用。将函数调用更换为发送事件,事件的处理是异步的,当前线程可以继续执行后续逻辑,线程池中的线程还可以被重用,这样整个系统的并发度会大大增加。发送的事件会存入缓存,由定时调度器取出后,分配给监听此事件的监听器对监控数据进行更新。
##总体介绍
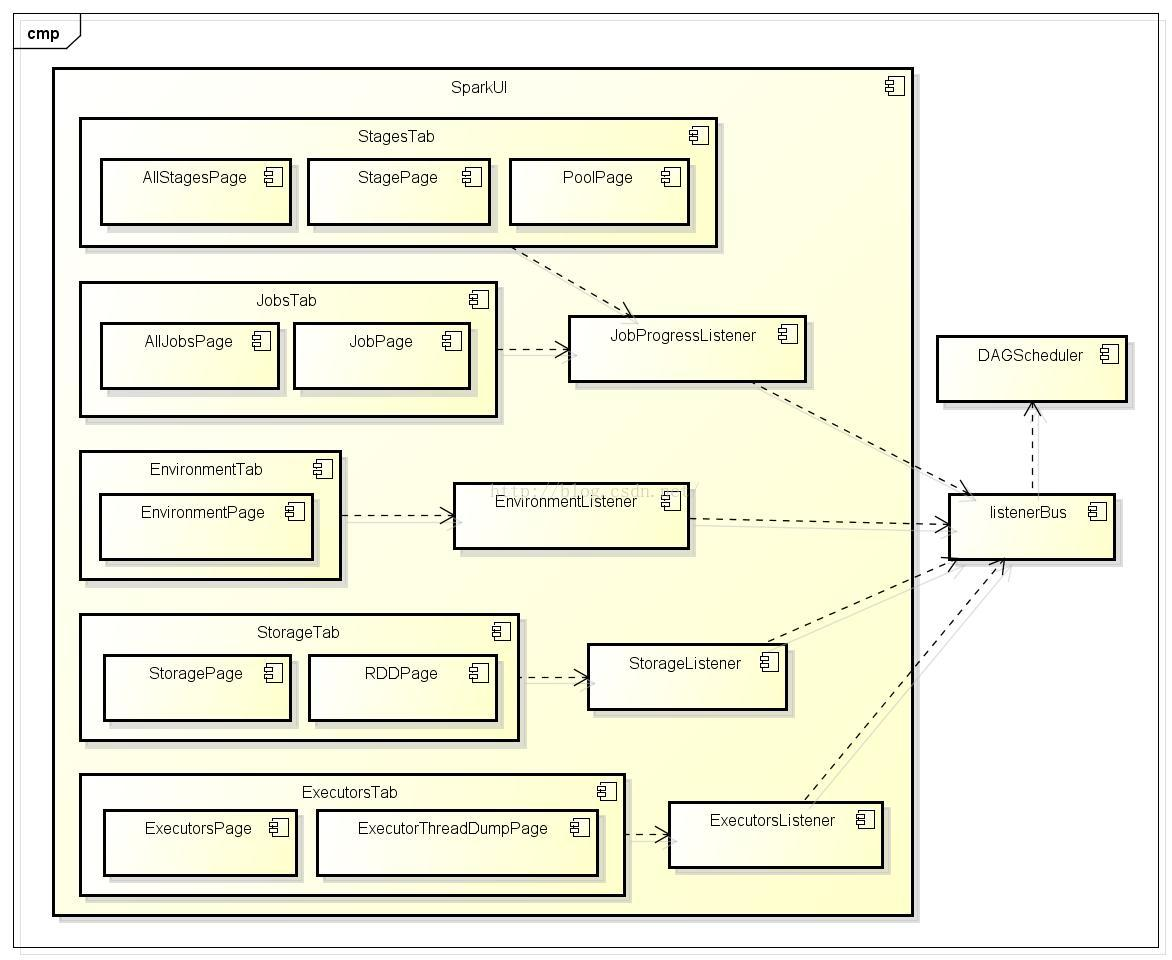
各个组件作简单介绍:DAGScheduler是主要的产生各类SparkListenerEvent的源头,它将各种SparkListenerEvent发送到listenerBus的事件队列中,listenerBus通过定时器将SparkListenerEvent事件匹配到具体的SparkListen

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 7299
7299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











