







前置条件,先把hadoop学会
创建普通的maven项目
pom
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.0</version>
</dependency>
流式处理
就是一条数据一条数据的处理
分词统计案例
有界流-读文件
创建aa.txt,按照空格区分
aa bb cc dd ee ff aa bb dd ee cc dd
package com.example.demoscala.controller;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 读文件 有界流(程序直接结束)
* 来一条读取一条
*/
public class Test {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//读取数据: 从文件读
DataStreamSource<String> dataStreamSource = exec.readTextFile("wenjian/aa.txt");
//处理数据: 切分 转换 分组 聚合
//切分转换
SingleOutputStreamOperator<Tuple2<String, Integer>> aa = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
//匿名内部类 实现切分转换 返回元组
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
//按照空格 切分
String[]sp=s.split(" ");
for (String x : sp) {
//转换成2元组(word,1) 第一个是单词,第二个是1
Tuple2<String, Integer> tp = Tuple2.of(x, 1);
//通过采集器 向下游发送数据
collector.collect(tp);
}
}
});
//分组
KeyedStream<Tuple2<String, Integer>, String> bb = aa.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> v) throws Exception {
//按照单词进行分组
return v.f0;
}
});
//聚合 对单词进行求和
SingleOutputStreamOperator<Tuple2<String, Integer>> cc = bb.sum(1);
//输出数据
cc.print();
//执行
exec.execute();
}
}

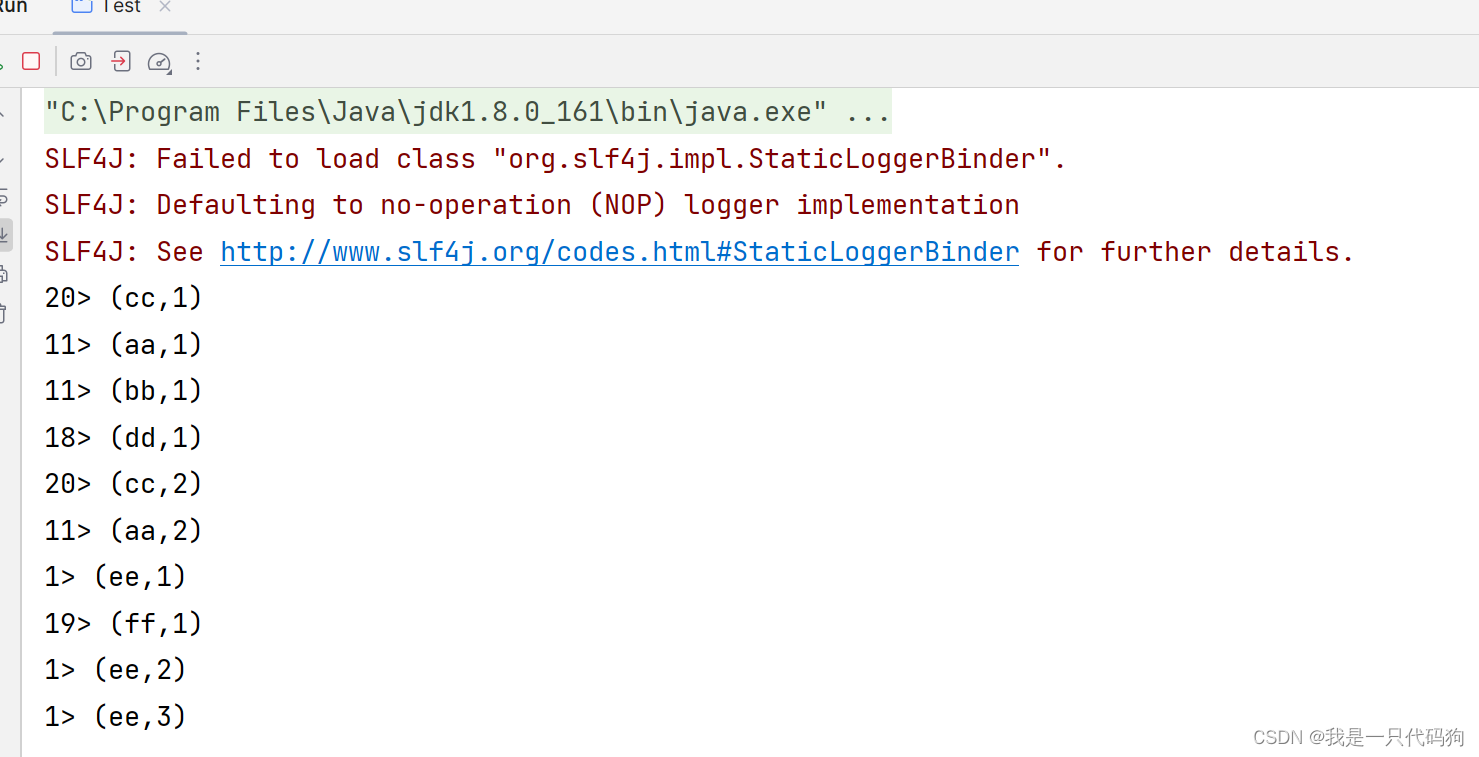
无界流-读socket
package com.example.demoscala.controller;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 读socket 无界流(长连接 不停止程序)
*
*/
public class Test {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//读取数据 socket
DataStreamSource<String> dataStreamSource = exec.socketTextStream("192.168.10.102", 9999);
//处理数据 切分 转换 分组 聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> aa = dataStreamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
//按照空格切分
String[] sp = s.split(" ");
for (String x : sp) {
//转换成二元组
Tuple2<String, Integer> y = Tuple2.of(x, 1);
collector.collect(y);
}
}
});
//分组
KeyedStream<Tuple2<String, Integer>, String> bb = aa.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
});
//聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> cc = bb.sum(1);
//输出
cc.print();
//执行
exec.execute();
}
}
在102的服务器上,输入nc -lk 9999端口号
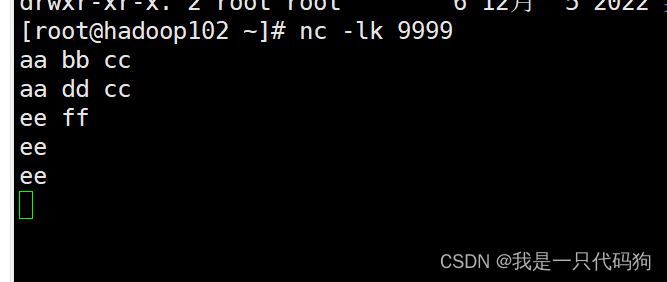
在idea的控制台就能看到处理的数据,并且程序不会关闭
集群角色
客户端:Java代码,提交给JobManager
JobManager: 对作业进行调度,获取要执行的作业,进一步转换,分发任务给TaskManager
TaskManager: 数据的处理操作都是他来做
| ip/域名 | 角色 |
| 192.168.10.102(hadoop102) | JobManager TaskManager |
| 192.168.10.103(hadoop103) | TaskManager |
| 192.168.10.104(hadoop104) | TaskManager |
安装部署
下载包
https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
然后放入3台机器中的/opt/module目录下,并解决
tar -zxvf flink-1.17.1-bin-scala_2.12.tgz
修改集群配置
cd /opt/module/flink-1.17.1/conf
vi flink-conf.yaml
在102机器的配置
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
在103机器的配置
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop103
在104机器的配置
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop104
配置workers,3台机器都配置
vi workers
hadoop102
hadoop103
hadoop104
在3台机器上配置主节点端口号
vi masters
hadoop102:8081
在102机器上启动flink集群
cd /opt/module/flink-1.17.1/bin
./start-cluster.sh
访问ui界面
向集群提交作业
添加pom打包插件
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>上传jar包到这里

点击详情,输入Test的路径,点击提交
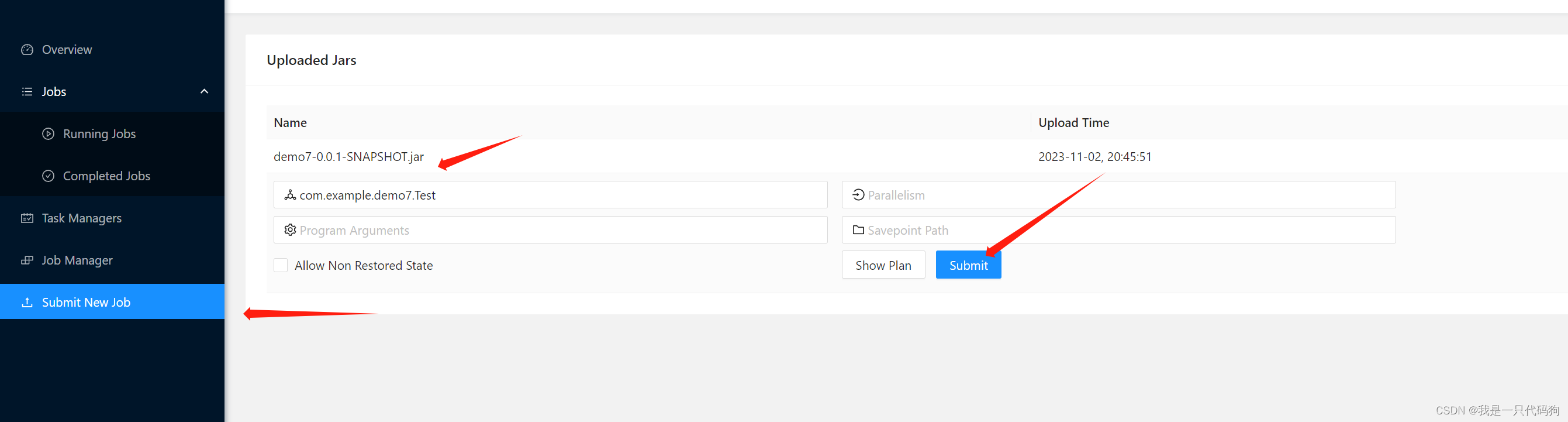
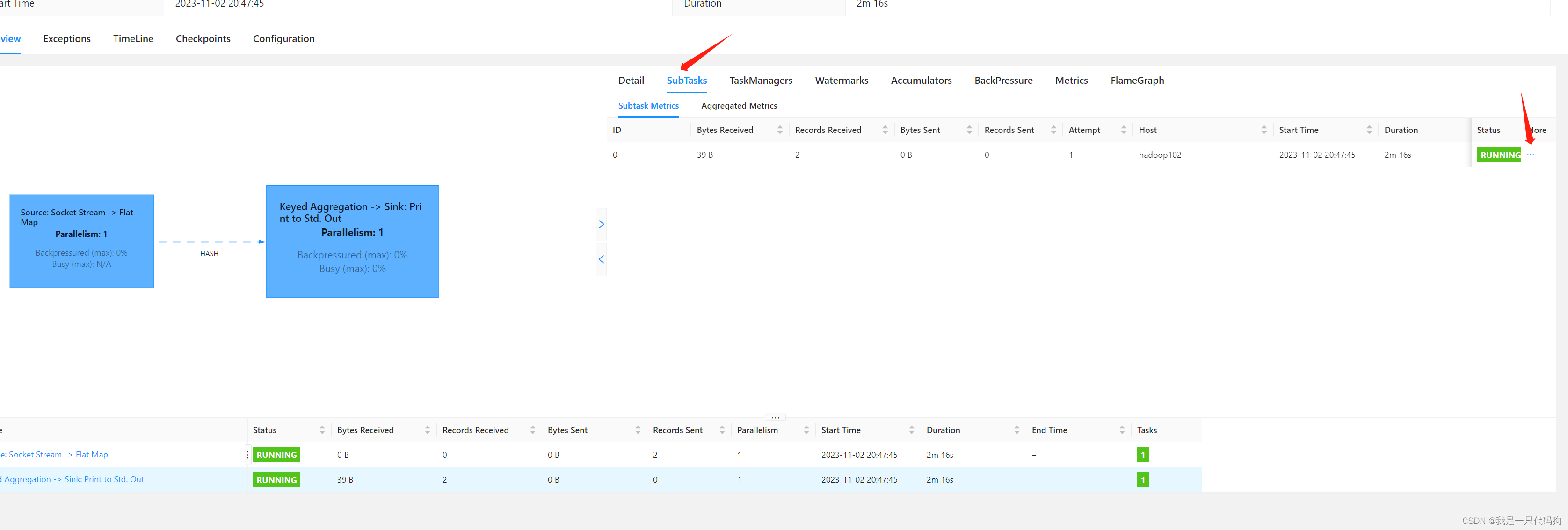
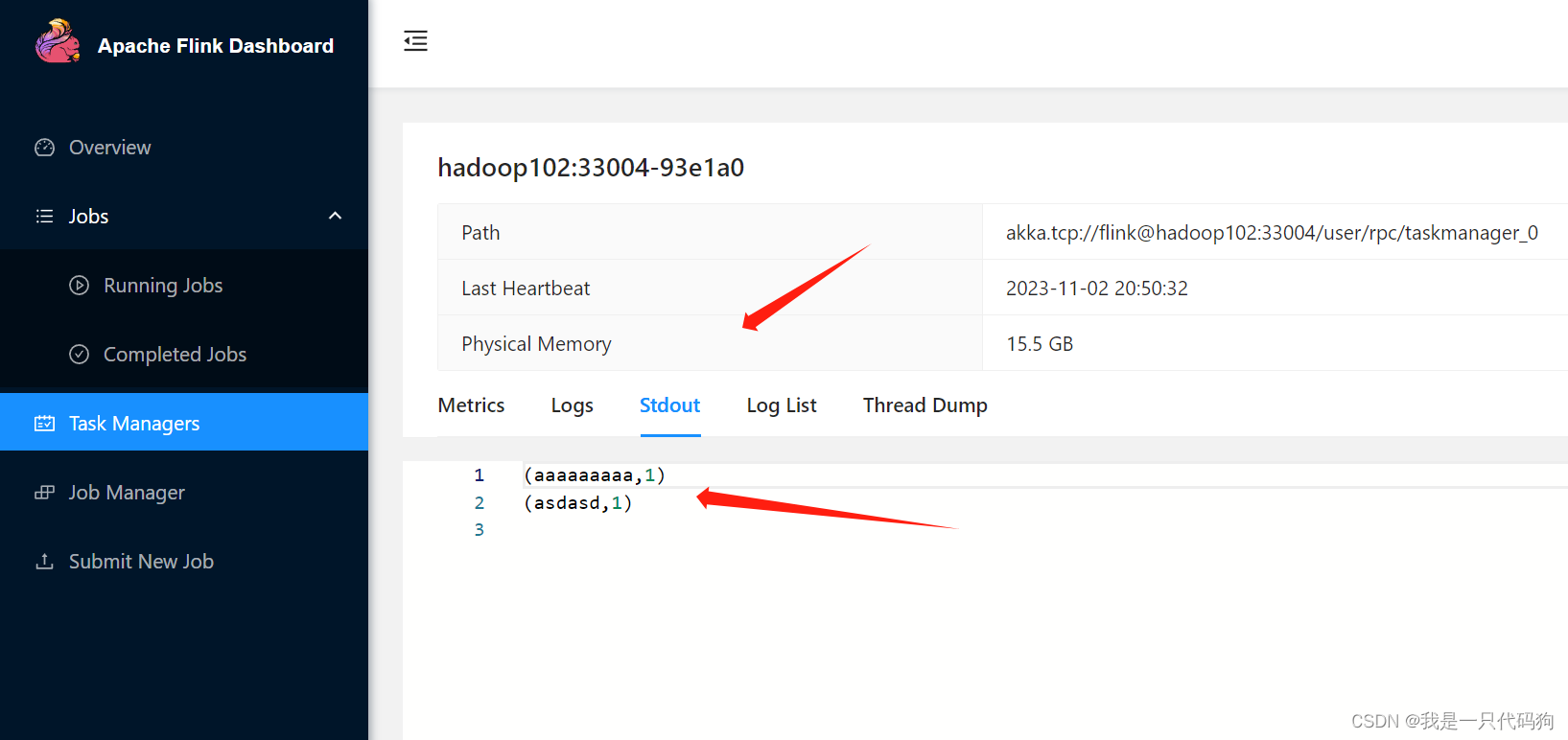
 在102的机器上发送消息,在ui界面的stdout,就能看到计算的结果,点刷新按钮
在102的机器上发送消息,在ui界面的stdout,就能看到计算的结果,点刷新按钮
部署模式
会话模式:先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业
单作业模式:为了更好的隔离资源,可以为每个提交的作业启动一个集群,这就是单作业模式
应用模式: 不需要客户端,直接把应用提交到jobmanager上运行,为每一个提交的应用单独启动一个jobmanager,也就是创建一个集群,执行结束后,jobmanager也就关闭了
历史服务器
当8081的端口挂掉之后,可以在8082的端口看到历史的任务信息
先在hdfs中创建logs目录
然后再3台机器上面修改配置
cd /opt/module/flink-1.17.1/conf
vi flink-conf.yaml
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs
historyserver.archive.fs.refresh-interval: 5000
然后进入flink的bin目录下启动历史服务器
./historyserver.sh start
关闭历史服务器可以使用
./historyserver.sh stop
当8081挂掉之后,就会在hdfs中存储历史的信息
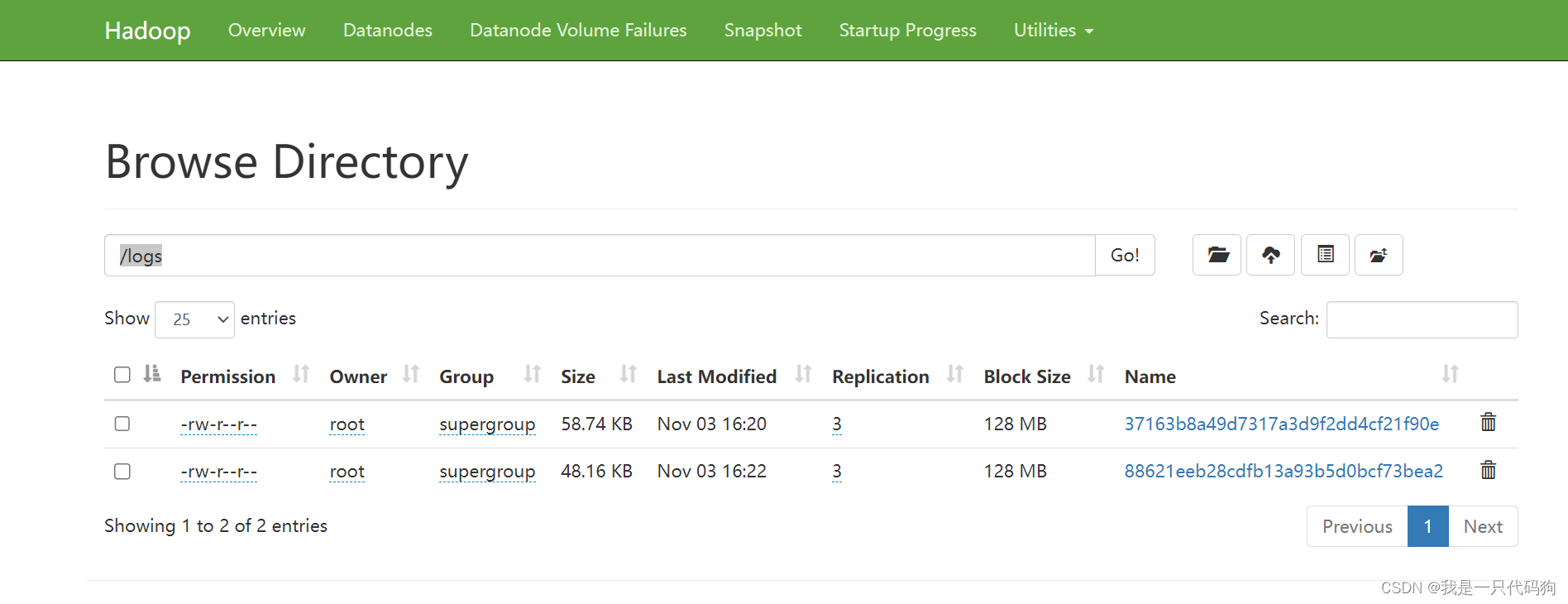
访问8082就可以看到历史的信息
http://hadoop102:8082

DataStream Api
DataStream Api是Flink的核心层Api,一个flink程序,就是对dataStream 的各种转换,由这几步构成:执行环境,读取数据源,转换操作,输出,执行
源算子
从集合中读取数据
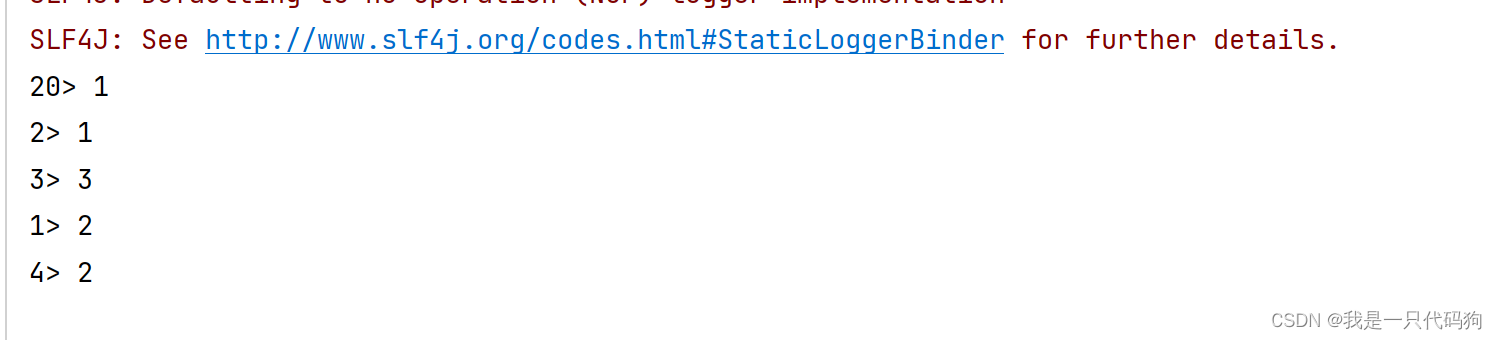
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
List<Integer> list= Arrays.asList(1,2,1,3,2);
//从集合中读取数据
DataStreamSource<Integer>ds=exec.fromCollection(list);
//输出
ds.print();
//执行
exec.execute();
}
}
从文件中读取数据
之前text已经过时了,需要先引入pom
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.17.0</version>
</dependency>
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从文件中读取数据
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat()
, new Path("wenjian/aa.txt"))
.build();
//输出
exec.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"资源名称")
.print();
//执行
exec.execute();
}
}

从kafka读取
引入pom,并提前创建好topic
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
kafka一定要提前安装好
package com.example.demo7;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
//kafka的ip和端口号
.setBootstrapServers("192.168.10.102:9092")
//主题的名称 提前创建好
.setTopics("zhuti")
//组id
.setGroupId("zuid")
.setStartingOffsets(OffsetsInitializer.latest())
//反序列化 字符串
.setValueOnlyDeserializer(new SimpleStringSchema())
//建造对象
.build();
//读取资源 并输出
exec.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"资源名称")
.print();
//执行
exec.execute();
}
}
kafka生产者发送消息
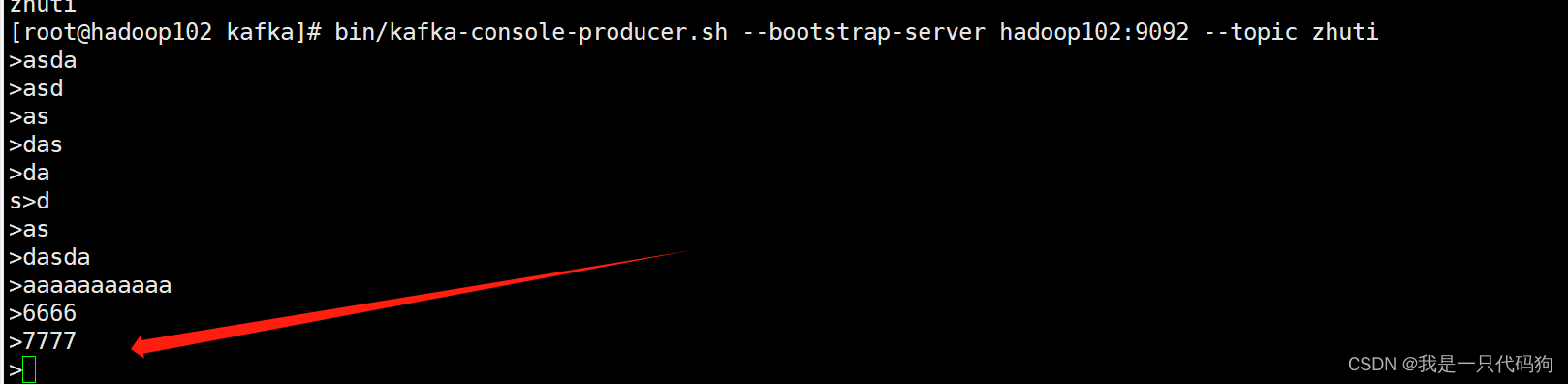
idea控制台接收消息
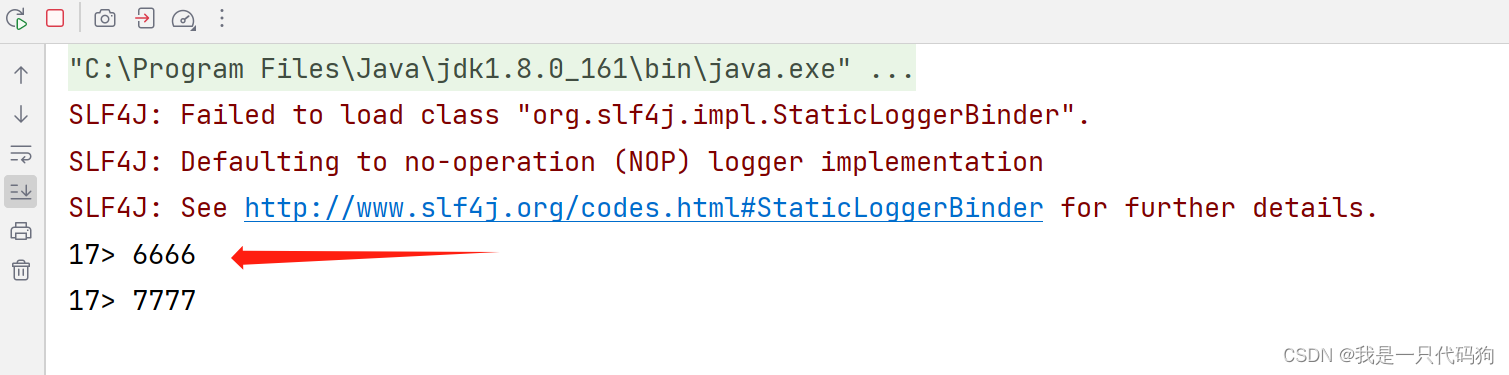
从数据生成器读取数据
引入pom
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-datagen</artifactId>
<version>1.17.0</version>
</dependency>
package com.example.demo7;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
import org.apache.flink.connector.datagen.source.DataGeneratorSource;
import org.apache.flink.connector.datagen.source.GeneratorFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行1 单线程
exec.setParallelism(1);
DataGeneratorSource<String> dataGeneratorSource=new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {
@Override
public String map(Long aLong) throws Exception {
return "内容:"+aLong;
}
},
//最多到10,可以设置无限大
10,
//限流策略 每秒有多少个许可 可以进入
RateLimiterStrategy.perSecond(1),
Types.STRING);
//读取资源数据 并打印
exec.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(),"资源名称").print();
//执行
exec.execute();
}
}

基本转换算子
map
主要用于将数据进行转换,生成新的数据 ,只能返回一条数据
package com.example.demo7;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(new User("1","张三"),
new User("2","李四"));
//只返回id
SingleOutputStreamOperator<String> mp = s.map(x -> x.getId());
mp.print();
exec.execute();
}
}

flatMap
可以返回多条数据,也可以把一行数据拆分
package com.example.demo7;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(new User("1","张三"),
new User("2","李四"));
SingleOutputStreamOperator<String> mp = s.flatMap(new FlatMapFunction<User, String>() {
@Override
public void flatMap(User user, Collector<String> collector) throws Exception {
collector.collect(user.getId());
collector.collect("可以输出多条信息");
}
});
mp.print();
exec.execute();
}
}
filter
数据过滤,只要等于true的 都打印出来
package com.example.demo7;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(new User("1","张三"),
new User("2","李四"));
//id=2的打印出来
SingleOutputStreamOperator<User> filter = s.filter(x -> "2".equals(x.getId()));
filter.print();
exec.execute();
}
}package com.example.demo7;
public class User {
private String id;
private String name;
public User(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
'}';
}
}
聚合算子
聚合算子必须和keyby一起使用
sum
package com.example.demo7;
public class User {
private String id;
private Integer age;
public User(){}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public User(String id, Integer age) {
this.id = id;
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id='" + id + '\'' +
", age=" + age +
'}';
}
}
package com.example.demo7;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(
new User("1",10),
new User("2",2),
new User("1",20),
new User("2",3));
//按照id 分组 相当于mysql的group by
KeyedStream<User, String> userStringKeyedStream = s.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User user) throws Exception {
return user.getId();
}
});
//对age进行累加求和
SingleOutputStreamOperator<User> aa = userStringKeyedStream.sum("age");
//打印
aa.print();
exec.execute();
}
}
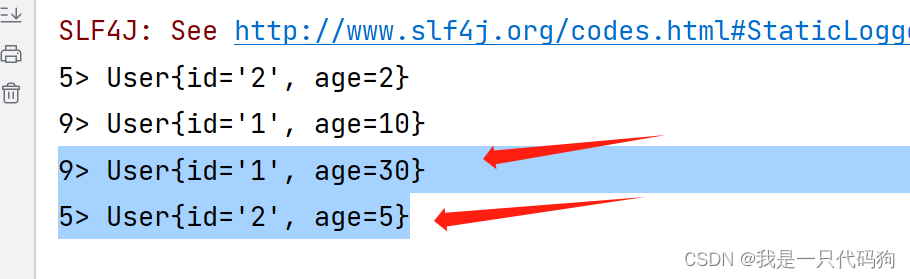
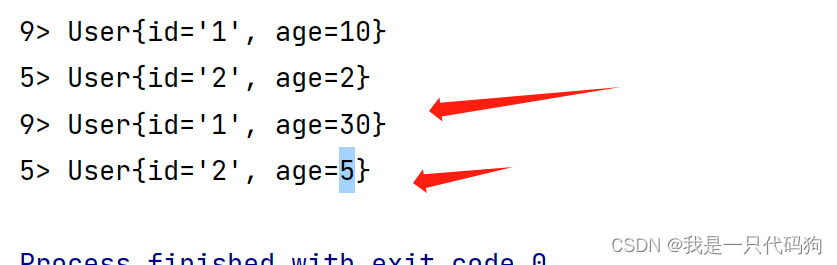
reduce
package com.example.demo7;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(
new User("1",10),
new User("2",2),
new User("1",20),
new User("2",3));
//按照id 分组 相当于mysql的group by
KeyedStream<User, String> userStringKeyedStream = s.keyBy(new KeySelector<User, String>() {
@Override
public String getKey(User user) throws Exception {
return user.getId();
}
});
//对age进行累加求和
SingleOutputStreamOperator<User> reduce = userStringKeyedStream.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User user, User t1) throws Exception {
//累加 求和 组成新的对象
return new User(user.getId(), user.getAge() + t1.getAge());
}
});
//打印
reduce.print();
exec.execute();
}
} 
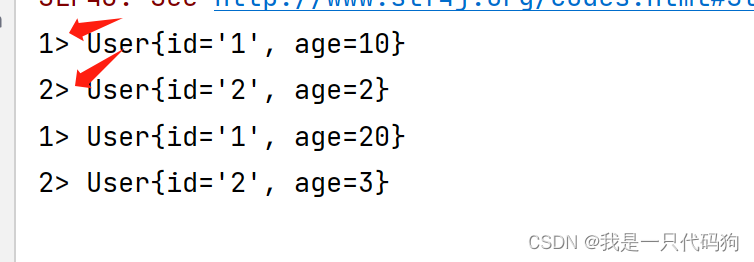
随机分区
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度 2个线程
exec.setParallelism(2);
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(
new User("1",10),
new User("2",2),
new User("1",20),
new User("2",3));
//随机分区
s.shuffle().print();
exec.execute();
}
} 
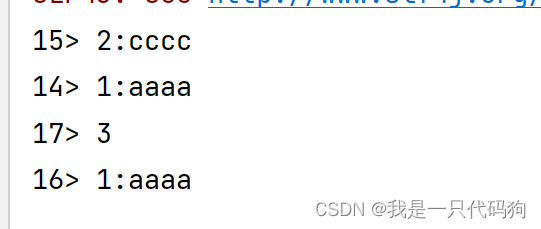
分流
就是把一条河流中的数据,开一个口子,让其中一部分的数据,分开走
package com.example.demo7;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SideOutputDataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//从对象中读取数据
DataStreamSource<User> s = exec.fromElements(
new User("1",10),
new User("2",2),
new User("1",20),
new User("3",3));
SingleOutputStreamOperator<String> mp = s.map(new MapFunction<User, String>() {
@Override
public String map(User user) throws Exception {
return user.getId();
}
});
OutputTag<String>s1=new OutputTag<>("1", Types.STRING);
OutputTag<String>s2=new OutputTag<>("2", Types.STRING);
SingleOutputStreamOperator<String> p = mp.process(new ProcessFunction<String, String>() {
@Override
public void processElement(String s, ProcessFunction<String, String>.Context context, Collector<String> collector) throws Exception {
if(s.equals("1")){
//放入1流
context.output(s1,s+":aaaa");
}else if(s.equals("2")){
//放入2流
context.output(s2,s+":cccc");
}else {
//放入主流
collector.collect(s);
}
}
});
//获取测流
SideOutputDataStream<String> a = p.getSideOutput(s1);
SideOutputDataStream<String> c = p.getSideOutput(s2);
//打印主流
p.print();
//打印测流
a.print();
c.print();
exec.execute();
}
}
合流
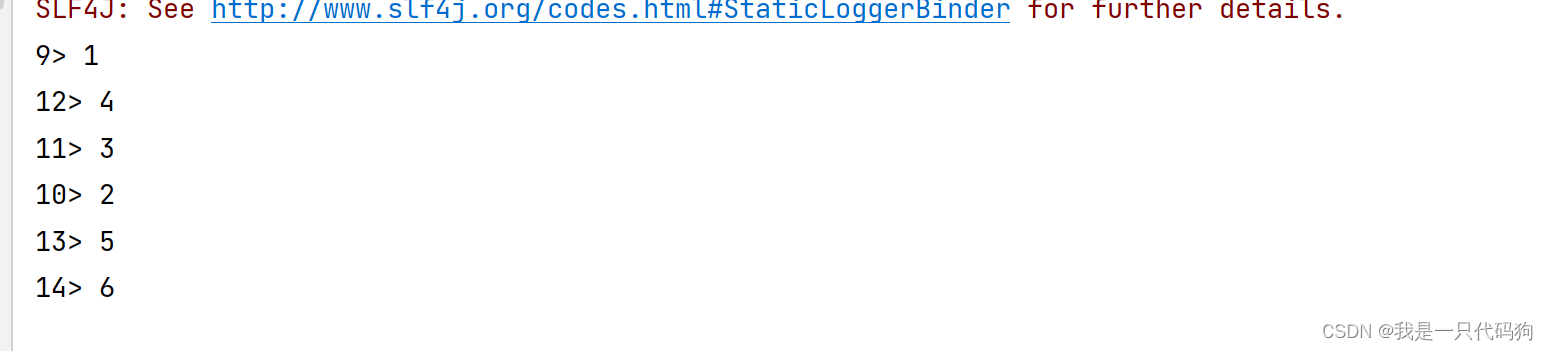
union
合并2个流的数据成一条流
package com.example.demo7;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> aa = exec.fromElements(1, 2, 3);
DataStreamSource<Integer> bb = exec.fromElements(4, 5, 6);
//合并流
aa.union(bb).print();
exec.execute();
}
}
connect
合并2个不同类型的流
package com.example.demo7;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> aa = exec.fromElements(1, 2, 3);
DataStreamSource<String> bb = exec.fromElements("a", "b", "c");
//合并流
ConnectedStreams<Integer, String> connect = aa.connect(bb);
//把2个流转换成string输出
SingleOutputStreamOperator<String> process = connect.process(new CoProcessFunction<Integer, String, String>() {
@Override
public void processElement1(Integer integer, CoProcessFunction<Integer, String, String>.Context context, Collector<String> collector) throws Exception {
collector.collect(integer.toString());
}
@Override
public void processElement2(String s, CoProcessFunction<Integer, String, String>.Context context, Collector<String> collector) throws Exception {
collector.collect(s);
}
});
process.print();
exec.execute();
}
}

输出算子
输出到文件
package com.example.demo7;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.resourcemanager.WorkerResourceSpecFactory;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import java.time.ZoneId;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> aa = exec.fromElements("aa", "vb", "cc");
//必须开启
exec.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
//输出到文件系统
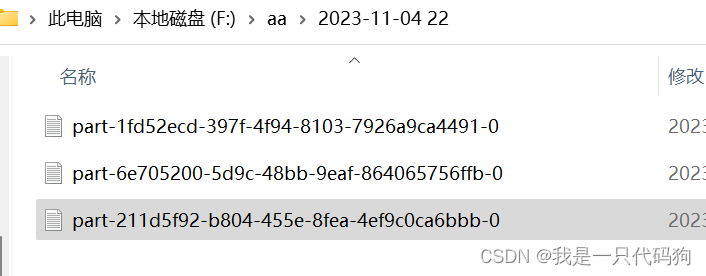
FileSink<String> f = FileSink.<String>forRowFormat(new Path("f:/aa"), new SimpleStringEncoder<>("UTF-8"))
//设置生成文件的后缀
.withOutputFileConfig(OutputFileConfig.builder().withPartSuffix(".txt").build())
//按照目录分桶 每个小时一个目录
.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))
.build();
aa.sinkTo(f);
exec.execute();
}
}
输出到kafka
package com.example.demo7;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.resourcemanager.WorkerResourceSpecFactory;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.time.ZoneId;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//必须开启
exec.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SingleOutputStreamOperator<String> aa = exec.socketTextStream("192.168.10.102",9999);
//指定kafka的ip和端口
KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("192.168.10.102:9092")
//指定序列化器 指定topic名称 具体的序列化
.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder()
.setTopic("zhuti")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
//写到kafka的一致性级别:精准一次 至少一次
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
//如果是精准一次 必须设置 事务的前缀
.setTransactionalIdPrefix("aaaaaa-")
//如果是精准一次 必须设置事务的超时时间 大于Checkpoint间隔 小于max 15分钟
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
aa.sinkTo(kafkaSink);
exec.execute();
}
}
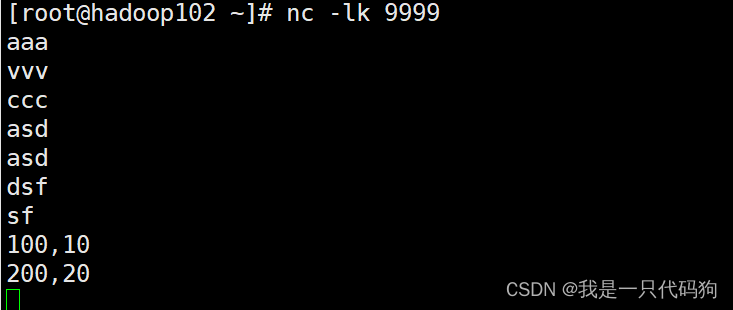
通过socket发送数据,kafka消费者接收数据


输出到mysql
创建表
CREATE TABLE `user1` (
`id` int NOT NULL,
`name` varchar(2) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`age` int NOT NULL,
`asd` tinyint DEFAULT NULL,
KEY `asd` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
package com.example.demo7;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.resourcemanager.WorkerResourceSpecFactory;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.time.ZoneId;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
//必须开启
exec.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
SingleOutputStreamOperator<User> aa = exec.socketTextStream("192.168.10.102",9999)
.map(new MapFunction<String, User>() {
@Override
public User map(String s) throws Exception {
String []sp=s.split(",");
return new User(sp[0],Integer.parseInt(sp[1]));
}
});
//INSERT INTO `dmg1`.`user1` (`id`, `name`, `age`, `asd`) VALUES (1, '张三', 100, 127);
SinkFunction<User> jdbcSink = JdbcSink.sink(
"insert into user1 values(?,?,?,?)",
new JdbcStatementBuilder<User>() {
@Override
public void accept(PreparedStatement preparedStatement, User user) throws SQLException {
//每收到一条WaterSensor,如何去填充占位符
preparedStatement.setString(1, user.getId());
preparedStatement.setString(2, "张三");
preparedStatement.setInt(3, user.getAge());
preparedStatement.setInt(4, 1);
}
},
JdbcExecutionOptions.builder()
// 重试次数
.withMaxRetries(3)
// 批次的大小:条数
.withBatchSize(100)
// 批次的时间
.withBatchIntervalMs(3000)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3306/dmg1?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
.withUsername("root")
.withPassword("123456")
.withConnectionCheckTimeoutSeconds(60) // 重试的超时时间
.build()
);
aa.addSink(jdbcSink);
exec.execute();
}
}
引入pom
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.27</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-jdbc</artifactId> <version>1.17-SNAPSHOT</version> </dependency><repositories> <repository> <id>apache-snapshots</id> <name>apache snapshots</name> <url>https://repository.apache.org/content/repositories/snapshots/</url> </repository> </repositories>
maven仓库设置 添加!apache-snapshots
从socket输入数据,添加到mysql中

窗口
增量聚合函数
package com.example.demo7;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<User> aa = exec.socketTextStream("192.168.10.102",9999)
.map(new MapFunction<String, User>() {
@Override
public User map(String s) throws Exception {
String []sp=s.split(",");
return new User(sp[0],Integer.parseInt(sp[1]));
}
});
//安装id 分组
aa.keyBy(x->x.getId())
//设置滚动事件 时间窗口 5秒
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
//增量聚合
.reduce(new ReduceFunction<User>() {
@Override
public User reduce(User user, User t1) throws Exception {
//2个age相加 组成新的对象
return new User(user.getId(),user.getAge()+t1.getAge());
}
})
.print();
exec.execute();
}
}5秒打印一次数据,累加之前的数据

全窗口函数
全窗口函数需要先收集窗口中的数据,并在内部缓存起来,等到窗口要输出结果的时候,在取出来进行计算
package com.example.demo7;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment exec = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<User> aa = exec.socketTextStream("192.168.10.102",9999)
.map(new MapFunction<String, User>() {
@Override
public User map(String s) throws Exception {
String []sp=s.split(",");
return new User(sp[0],Integer.parseInt(sp[1]));
}
});
//安装id 分组
aa.keyBy(x->x.getId())
//设置滚动事件 时间窗口 5秒
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
//全窗口函数
.process(new ProcessWindowFunction<User, Object, String, TimeWindow>() {
@Override
public void process(String s, ProcessWindowFunction<User, Object, String, TimeWindow>.Context context, Iterable<User> iterable, Collector<Object> collector) throws Exception {
long count=iterable.spliterator().estimateSize();
long start=context.window().getStart();
long end=context.window().getEnd();
String kaishi= DateFormatUtils.format(start,"yyyy-MM-dd HH:mm:ss");
String jieshu= DateFormatUtils.format(end,"yyyy-MM-dd HH:mm:ss");
collector.collect("当前key:"+s+",开始时间:"+kaishi+",结束时间:"+jieshu+",总数:"+count);
}
}).print();
exec.execute();
}
}
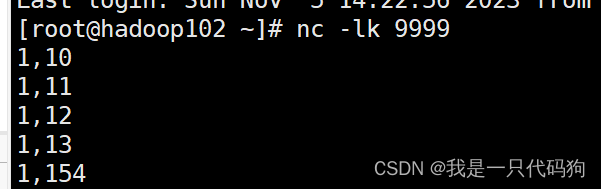
只统计这5秒内的数据,之前的数据 不会累计

Flink Sql
在102机器的flink的bin目录下 启动客户端
./sql-client.sh
创建数据库
create database dmg;
进入数据库
use dmg;
创建表
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);创建数据源生成器
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='10',
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='1000000',
'fields.vc.kind'='random',
'fields.vc.min'='1',
'fields.vc.max'='100'
);设置显示模式
SET sql-client.execution.result-mode=tableau;
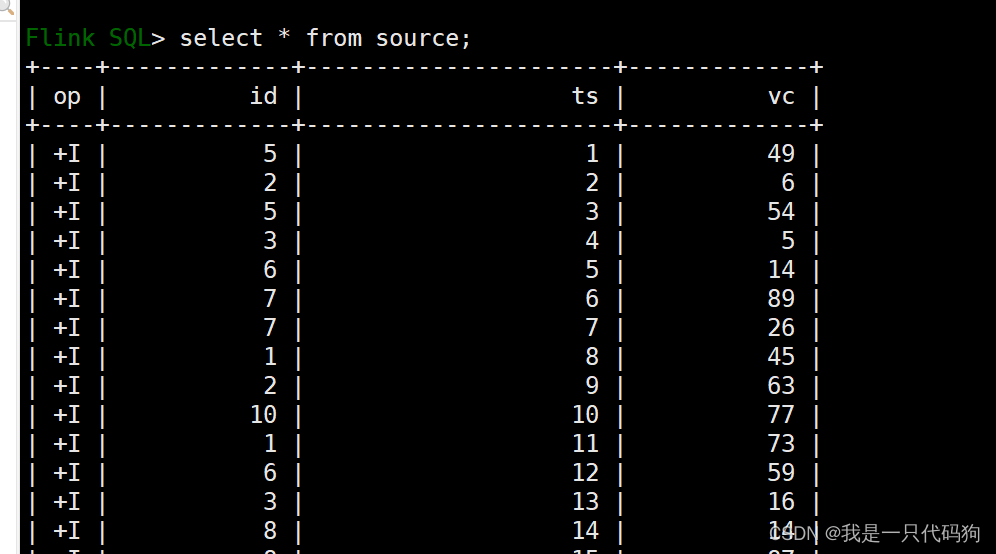
查看数据源生成器

















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









