







 本文详细介绍requests库和urllib库在网络数据采集中的应用,包括请求发送、响应处理、高级功能如headers和IP代理设置,以及常见异常处理。
本文详细介绍requests库和urllib库在网络数据采集中的应用,包括请求发送、响应处理、高级功能如headers和IP代理设置,以及常见异常处理。
网络数据采集(抓取页面)存在两种方式,一种是主流的requests库(必须要掌握的),还有一种是python内置的HTTP请求库urllib(了解)。
1. 网络数据采集之requests库
requests 官方网址:https://requests.readthedocs.io/en/master/
requests 常用方法:
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支撑以下各个方法的基础方法 |
| requests.get() | 获取 HTML 网页的主要方法,对应于 HTTP 的 GET |
| requests.head() | 获取 HTML 网页头信息的主要方法,对应于 HTTP 的 HEAD |
| requests.post() | 向 HTML 网页提交 POST 请求的方法,对应于 HTTP 的 POST |
| requests.put() | 向 HTML 网页提交 PUT 请求的方法,对应于 HTTP 的 PUT |
| requests.patch() | 向 HTML 网页提交局部修改请求,对应于 HTTP 的 PATH |
| requests.delete() | 向 HTML 网页提交删除请求,对应于 HTTP 的 DELETE |
requests 常用属性:r = requests.get('https://api.github.com/events')
| 属性 | 说明 |
|---|---|
| r.status_code | HTTP 请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即 URL 对应的页面内容 |
| r.encoding | 从 HTTP header中猜想的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析的响应内容的编码方式(备选编码方式) |
| r.content | HTTP 响应内容的二进制形式 |
1.1 requests应用实例
为更加深刻的理解requests库的方法和属性,自行编写基于Flask框架的简易web应用程序,通过对该web应用的数据采集模拟其他环境下requests模块的工作原理,代码如下所示:
from urllib.error import HTTPError
import requests
def get():
url = "http://127.0.0.1:5000"
try:
# 以字典的形式自定义参数
params = {
"username": "admin",
"page": 1,
"per_page": 5
}
response = requests.get(url, params=params)
print("Response:", response)
print("Text:", response.text)
print("URL:", response.url)
print("Status_code:", response.status_code)
print("Content:", response.content)
print("Encoding:", response.encoding)
except HTTPError as e:
print("爬虫爬取%s失败:%s" % (url, e.reason))
def post():
url = "http://127.0.0.1:5000/post/"
try:
data = {
"username": "admin",
"password": "123"
}
# 如果此处post、get混乱,也会返回405 Method Not Allowed错误 requests.post<-->requests.get
response = requests.post(url, data=data)
print("Text:", response.text)
print("URL:", response.url)
except HTTPError as e:
print("爬虫爬取%s失败:%s" % (url, e.reason))
if __name__ == '__main__':
get()
print("分割线".center(50, "-"))
post()
自行编写基于Flask框架的简易web应用程序,代码如下:
"""
from flask import Flask, request
app = Flask(__name__)
@app.route('/')
def index():
# 获取 get 方法提交的参数
print(request.args)
# 默认的用户代理:python-requests/2.23.0
print("用户代理 user-agent:", request.user_agent)
return "index: %s" % request.args
@app.route('/post/', methods=['POST'])
def post():
# 获取用户 post 提交的信息
print(request.form)
username = request.form.get('username')
password = request.form.get('password')
if username == 'admin' and password == '123':
return 'login success'
else:
return 'login failed'
if __name__ == '__main__':
app.run(debug=True)
服务端执行结果:
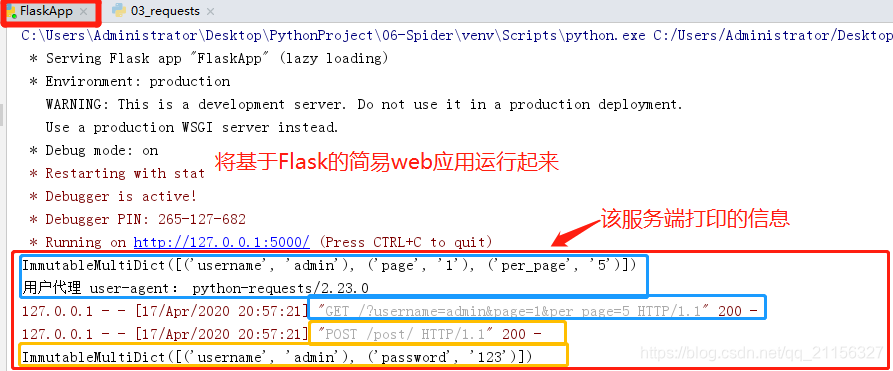
客户端执行结果:
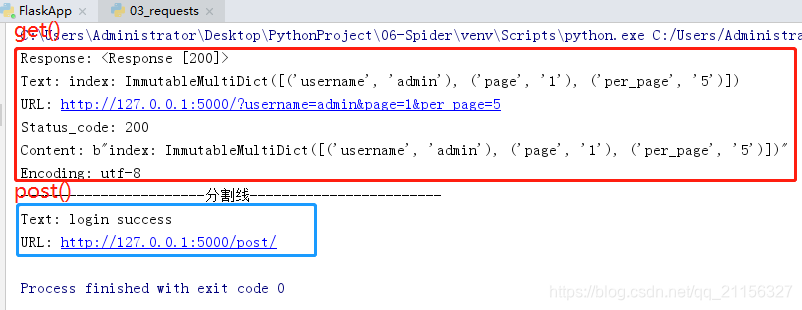
1.2 requests 高级应用——添加 headers
因为,正如在上面服务端执行结果图中用户代理 user-agent:python-requests、2.23.0,无疑在告诉网站我是来爬虫的,就是来爬你们家,像猫眼电影爬的次数多,服务器压力就会变大,就不得不制定相应的反爬机制,不让你轻轻松松获取到数据。
所以,user.agent:作为识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换 UserAgent 可以避免触发相应的反爬机制。
import requests
# fake-useragent.UserAgent 对频繁更换UserAgent提供了很好的支持,可谓防反扒利器。
from fake_useragent import UserAgent
def add_headers():
url = "http://127.0.0.1:5000"
# 默认的用户代理:python-requests/2.23.0
# 从页面开发者选型-网络-消息头 中找到的user-agent信息
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
# https://fake-useragent.herokuapp.com/browsers/0.1.11 查看用户代理,json格式
ua = UserAgent() # 实例化对象
response = requests.get(url, headers={"User-Agent": ua.random}) # 添加headers 信息
print(response)
if __name__ == '__main__':
add_headers()
add_headers()
执行结果:
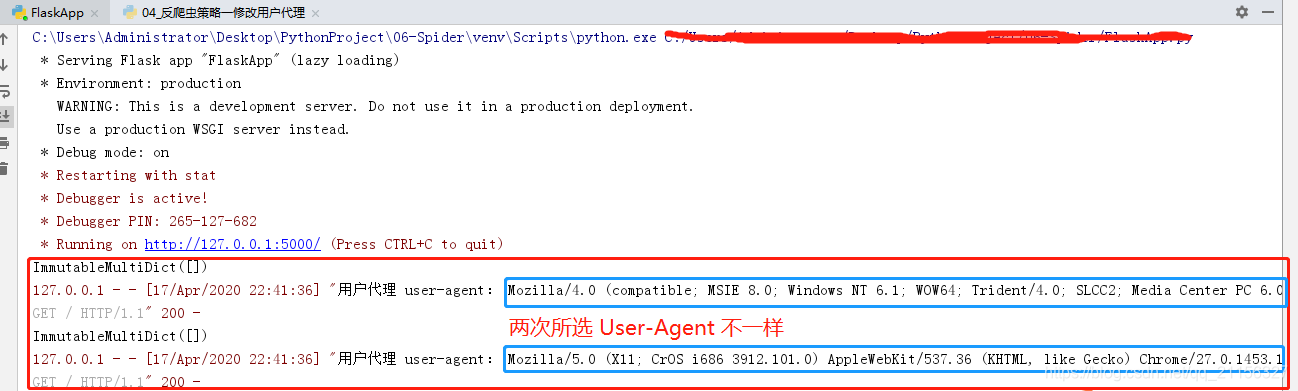
1.2 requests 高级应用——IP代理设置
IP 代理设置与 User-Agent 设置原理相同,也是应对反爬机制的一种,在进行爬虫爬取时,有时候爬虫会被服务器给屏蔽掉,这时采用的方法主要有降低访问时间,通过代理IP访问。IP 可以从网上抓取,或者某宝购买。免费IP代理:西刺IP
"""
import requests
from fake_useragent import UserAgent
url = "http://xx.xx.xx.xx:8000" # 一个云服务器的公网IP,部署有一个简易web服务器
ua = UserAgent()
# IP 代理
proxies = {
'http': 'http://117.88.176.119:3000',
'https': 'https://182.92.220.212:8080'
}
# IP代理的设置方法
response = requests.get(url, headers={"User-Agent": ua.random},
proxies=proxies)
print(response)
# 这是因为服务器端会返回数据: get提交的数据和请求的客户端IP
# 如何判断是否成功? 返回的客户端IP刚好是代理IP, 代表成功。
print(response.text)
2. 网络数据采集之urllib库
官方文档地址:https://docs.python.org/3/library/urllib.html
urllib 库是 python 的内置 HTTP 请求库,包含以下各个模块内容:
- urllib.request:请求模块
- urllib.error:异常处理模块
- urllib.parse:解析模块
- urllib.robotparser:robots.txt解析模块
- urllib.urlopen:进行简单的网站请求,不支持复杂功能如验证、cookie和其他HTTP高级功能,若要支持这些功能必须使用 build_opener() 函数返回的 OpenerDirector 对象。
一个 urllib 使用的范例:
from urllib.request import urlopen, Request
# 方法一: 通过 get 方法请求url
with urlopen('http://www.python.org/') as f:
# 默认返回的页面信息是bytes类型, bytes类型转换成字符串,decode方法。
print(f.read(300).decode('utf-8'))
# 方法二: Request 对象发起请求
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0'
# 封装请求头部信息, 模拟浏览器向服务器发起请求
request = Request('http://www.python.org/', headers={'User-Agent': user_agent})
with urlopen(request) as f:
# 默认返回的页面信息是 bytes 类型, bytes 类型转换成字符串,用 decode 方法。
print(f.read(300).decode('utf-8'))
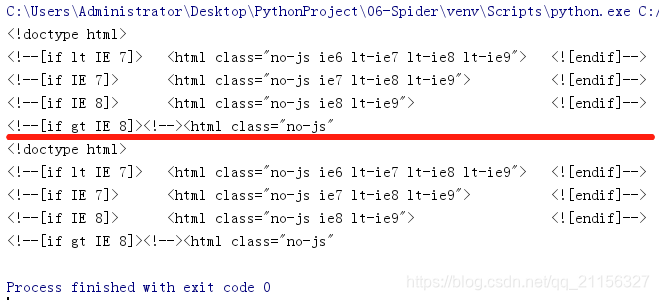
执行结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









