







一、前言
阅读该文前请先看认识要从线性回归和逻辑回归说起,因为本质上来说线性回归和逻辑回归是一种最简单的神经网络,从线性回归和逻辑回归开始理解,会相对容易一些!
神经网络网络也被称为端到端的学习,为什么这么说呢?
是因为有别于传统的机器学习的一点是:
传统的机器学习在学习之前基本上要经过一个特征工程,简单地理解就是人为地提取算法所需要的的特征,而这个工程也是机器学习最重要的一环,神经网络则不同,我们可以省略特征工程这个环节(理论上),直接把数据喂给神经网络,理解和学习数据是神经网络应该做的,毕竟他已经是一个更成熟一点的宝宝了,不能再事事依靠工程师妈妈了
需要说明的一点是,神经网络其实也是机器学习的一个分支,不能将机器学习和神经网络放在同一级别来理解,另外神经网络中虽然有很多公式,但都是基本的加减乘除法,不要想着会因为公式造成加成伤害!
二、基础理论
1、网络由来
神经网络主要是从生物神经元那里得到灵感,但并非仿生了人类的大脑,我们的大脑在处理信息作出决策时,可以将多个输入信息进行处理,最后得出一个结论,假设我们的大脑有三个情报人员,每一次的决策都是根据三个情报人员的信息进行判断,如下图:

至于怎么得出的,我们并不关心,人类需要的仅仅是结果!
端到端也可以这么理解,我们给神经网络数据,让他自己学习,最后给我个结果就行,能不麻烦人类是最好的!
然而理想总是很丰满,现实总是穷到连个脑子都没有,咋办呢?
科学家就给神经网络简单粗暴地造了一个脑子出来:
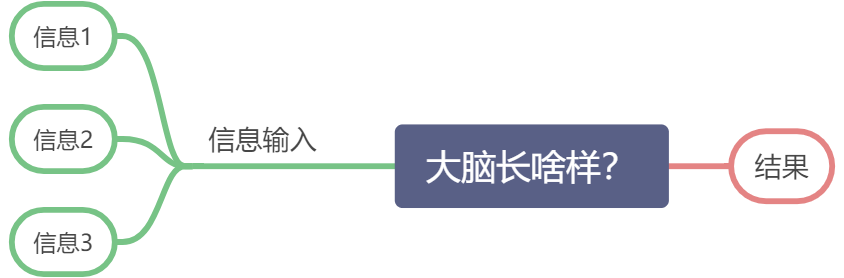
人类比较擅长的就是假设和归纳总结,于是乎,就假设这个大脑对于各个信息是有放大和屏蔽作用的,这也很符合人类的双标甚至多标。
比如这个大脑觉得信息1这个情报靠谱,事情干得不错,那权重就加大一点,设置个2吧,于是乎:
大 脑 接 收 的 信 息 1 = 2 ∗ 信 息 1 大脑接收的信息1=2*信息1 大脑接收的信息1=2∗信息1
这个大脑觉得信息2这个情报有时候不太靠谱,所以他的话不可全信,那权重就设置小一点,设置个0.5吧,于是乎:
大 脑 接 收 的 信 息 2 = 0.5 ∗ 信 息 2 大脑接收的信息2=0.5∗信息2 大脑接收的信息2=0.5∗信息2
大脑觉得信息3这个情报更不靠谱:
大 脑 接 收 的 信 息 3 = 0.1 ∗ 信 息 3 大脑接收的信息3=0.1∗信息3 大脑接收的信息3=0.1∗信息3
需要明确的是:以上权重是为了说明原理,随意设置的,真实过程中是根据数据学习而来的
设置完了权重,大脑就需要汇总信息,于是:
大
脑
接
收
的
信
息
=
2
∗
信
息
1
+
0.5
∗
信
息
2
+
0.1
∗
信
息
3
大脑接收的信息=2∗信息1+0.5∗信息2+0.1∗信息3
大脑接收的信息=2∗信息1+0.5∗信息2+0.1∗信息3
当然,有时候发现这样还不够准确,需要微调一下,再加上一个偏置b
大 脑 接 收 的 信 息 = 2 ∗ 信 息 1 + 0.5 ∗ 信 息 2 + 0.1 ∗ 信 息 3 + b 大脑接收的信息=2∗信息1+0.5∗信息2+0.1∗信息3+b 大脑接收的信息=2∗信息1+0.5∗信息2+0.1∗信息3+b
以上就是神经网络的信息处理过程,处理完信息,下一步就是根据信息进行决策了,如何决策呢?
也就是在认识要从线性回归和逻辑回归说起一文中所说过的激活函数,二分类可以使用sigmoid,多分类使用softmax(当然,还有很多其他激活函数),此处不做多余赘述,直接上结果:
大 脑 做 出 的 决 定 = 激 活 函 数 ( 2 ∗ 信 息 1 + 0.5 ∗ 信 息 2 + 0.1 ∗ 信 息 3 + b ) 大脑做出的决定=激活函数(2∗信息1+0.5∗信息2+0.1∗信息3+b) 大脑做出的决定=激活函数(2∗信息1+0.5∗信息2+0.1∗信息3+b)
到此为止,就是整个神经网络的决策过程,上述公式也就是给神经网络人为造的一个大脑!是不是觉得很简单,不要慌,难的还没说!
2、神经网络的学习过程
(1)梯度下降法
定义完了神经网络的决策过程,现在来说说学习过程,在决策过程中,我们提到了很多权重,这些权重是怎么来的呢?
是通过学习而来的,神经网络的学习说到底也就是通过数据学习这些权重,具体如何学习呢?
还是之前提过的定义损失函数,采用梯度下降法来进行优化,这已经是一个常态,详情请参考认识要从线性回归和逻辑回归说起和梯度下降法是个什么东东
(2)多层神经网络
在网络的由来一节中,我们假设了该网络公有三个信息输入通道,计算的时候是分开计算在进行汇总,其实我们可以再抽象一下网络结构:
大
脑
做
出
的
决
定
(
y
)
=
激
活
函
数
(
σ
)
(
权
重
(
W
)
∗
信
息
输
入
(
x
)
+
b
)
大脑做出的决定(y)=激活函数(σ)(权重(W)∗信息输入(x)+b)
大脑做出的决定(y)=激活函数(σ)(权重(W)∗信息输入(x)+b)
上述的过程仅仅是一层一个神经元的简单神经网络,实际情况中,任务往往比较复杂,需要进行多层甚至深度的神经网络进行学习,其原理是把上一层的结果当成输入,继续上一层的方式进行计算,这个时候我们的网络层就是:
y = σ n . . . ( σ 2 ( W 2 ∗ σ 1 ( W 1 ∗ x 1 + b 1 ) + b 2 ) + . . . b n ) y=\sigma_n...(\sigma_2(W_2*\sigma_1(W_1*x_1+b_1)+b_2)+...b_n) y=σn...(σ2(W2∗σ1(W1∗x1+b1)+b2)+...bn)
在这个网络中,中间的计算层称之为隐藏层,具体需要几层根据实际情况调整
(3)矩阵运算与数据形态
由于输入的数据有三个维度,也就是三个特征,可以采用一个一行三列的数据表示,此输入需要能和权重相乘,那权重就可以用一个三行一列的数据表示,如:
大 脑 接 收 的 信 息 = 2 ∗ 信 息 1 + 0.5 ∗ 信 息 2 + 0.1 ∗ 信 息 3 = [ 信 息 1 信 息 2 信 息 3 ] ∗ [ 2 0.5 0.1 ] 大脑接收的信息=2*信息1+0.5*信息2+0.1*信息3=\begin{bmatrix} 信息1&信息2&信息3 \end{bmatrix} * \begin{bmatrix} 2\\ 0.5\\ 0.1\\ \end{bmatrix} 大脑接收的信息=2∗信息1+0.5∗信息2+0.1∗信息3=[信息1信息2信息3]∗⎣⎡20.50.1⎦⎤
如此我们定义权重的维度就要和输入维度保持相关性才能进行计算,不能违背矩阵的乘法规则,如输入数据为一1个,这个数据的特征有100个,最后需要输出的结果为10个,神经网络有2层(不包括输入和输出),那各个层数据维度为:
( 1 , 100 ) ∗ ( 100 , m ) ∗ ( m , n ) ∗ ( n , 10 ) = ( 1 , 10 ) (1,100)*(100,m)*(m,n)*(n,10)=(1,10) (1,100)∗(100,m)∗(m,n)∗(n,10)=(1,10)
在网络结果固定有,根据矩阵的运算规则,理论上输入多少个数据已经不是问题了,只要计算资源撑得出,比如同时预测1000个数据的结果:
( 1000 , 100 ) ∗ ( 100 , m ) ∗ ( m , n ) ∗ ( n , 10 ) = ( 1000 , 10 ) (1000,100)*(100,m)*(m,n)*(n,10)=(1000,10) (1000,100)∗(100,m)∗(m,n)∗(n,10)=(1000,10)
(4)反向传播
预测的过程在神经网络中被称为前向传播(或者叫前馈),而反向传播主要用于学习过程中梯度的高效计算,为什么前面的逻辑回归中没有提到它呢?
因为那么个小鸡不足以使用这把牛刀!
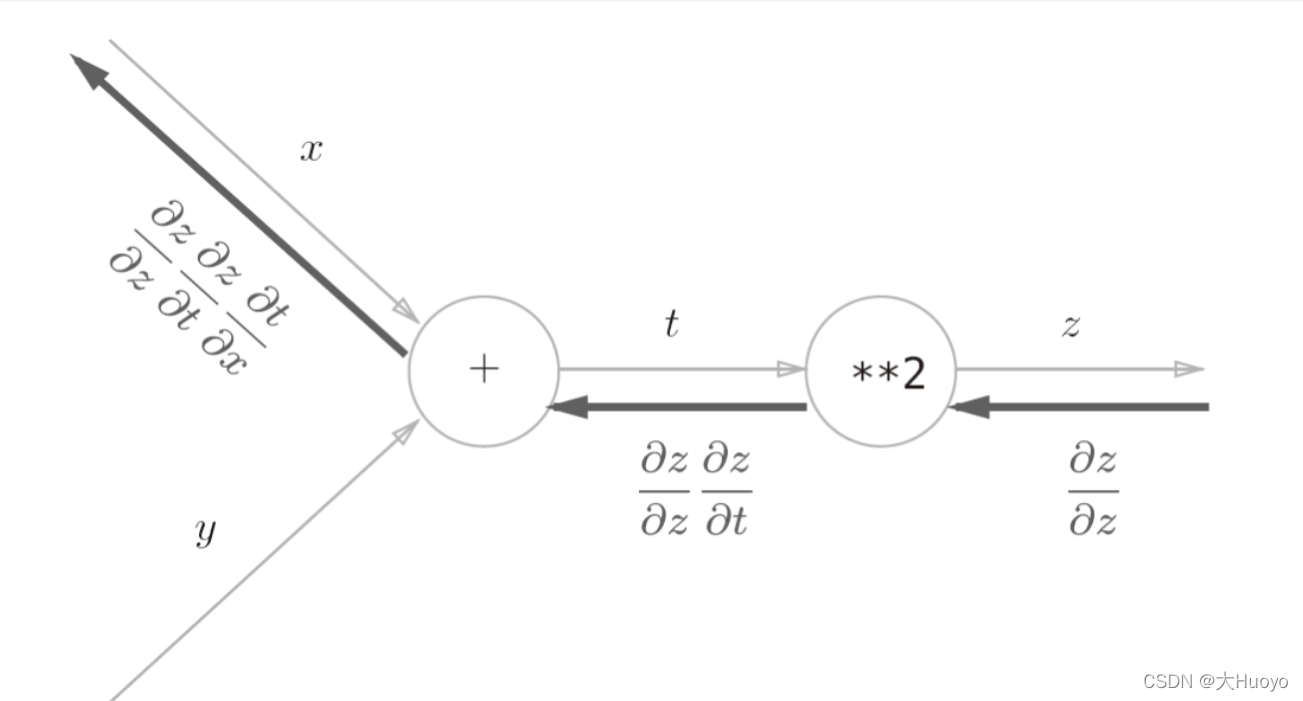
正常情况下,我们计算梯度只需要把函数的偏导数求出分别计算即可,但是当函数比较复杂的时候,求导仿佛就是在开玩笑,这个时候就可以采用求导链式法则,即复合函数的导数可以用构成复合函数的各个函数在响应变量点的导数的乘积表示。
这么说有点抽象,举个例子:假设有如何函数:
y = ( x + z ) 2 y=(x+z)^2 y=(x+z)2
要求y对x的偏导数,可以两先令 t = x + z t=x+z t=x+z
,那么y对x的偏导数等于y对于t的倒数乘上t对x的倒数:
∂ y ∂ x = ∂ y ∂ t ∗ ∂ t ∂ x = 2 t ∗ 1 = 2 ( x + z ) \frac{\partial y}{\partial x} =\frac{\partial y}{\partial t} * \frac{\partial t}{\partial x}=2t*1=2(x+z) ∂x∂y=∂t∂y∗∂x∂t=2t∗1=2(x+z)
通过这种方式,就可以把神经网络的函数求导进行拆解,从末尾开始,将各个层级的梯度求出以后,一层层传播回来计算,大大提高了计算效率!
好了,我要干饭去了,再见!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











