







 本文对比了TensorFlow2与PaddlePaddle在数据加载、模型定义、训练配置及过程上的差异,通过具体代码示例展示了两种框架在实现相同任务时的不同之处。
本文对比了TensorFlow2与PaddlePaddle在数据加载、模型定义、训练配置及过程上的差异,通过具体代码示例展示了两种框架在实现相同任务时的不同之处。
引言
前面写了一篇Tensorflow2与PaddlePaddle小白入门级写法对比的
今天来看一下所谓的专家入门写法对比(这里的专家不是本人说的,出自Tensorflow官网,求生欲满满:https://tensorflow.google.cn/overview?hl=en)
数据加载器
- Tensorflow2
import tensorflow as tf
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = \
tf.keras.datasets.mnist.load_data()
train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(60000).batch(32)
test_ds = tf.data.Dataset.from_tensor_slices((test_images, test_labels)).batch(32)
- PaddlePaddle
import paddle
# 加载数据集
train_dataset,test_dataset = paddle.vision.datasets.MNIST(mode='train'), \
paddle.vision.datasets.MNIST(mode='test')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = paddle.io.DataLoader(train_dataset, batch_size=32,)
数据加载器的使用上差距并不是很大,不过发现TF2的使用过程提供了一个map函数,可以自定义数据的预处理
# 预处理
def preprocess(x,y):
x = tf.cast(x,dtype = tf.float32)/255
y = tf.cast(y,dtype = tf.int32)
return x,y
db = tf.data.Dataset.from_tensor_slices((x, y)).map(preprocess).batch(32)
模型定义
在模型的定义上,两者都支持自定义模型,套路如出一辙
- Tensorflow2
class MnistModel(tf.keras.Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = tf.keras.layers.Flatten()
self.middle = tf.keras.layers.Dense(128, activation='relu')
self.out = tf.keras.layers.Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.middle(x)
x = self.out(x)
return x
- PaddlePaddle
class MnistModel(paddle.nn.Layer):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = paddle.nn.Flatten()
self.middle = paddle.nn.Linear(784,128)
self.middle_act = paddle.nn.ReLU()
self.out = paddle.nn.Linear(128,10)
def forward(self, x):
x = self.flatten(x)
x = self.middle(x)
x = self.middle_act(x)
x = self.out(x)
return x
训练指标的配置
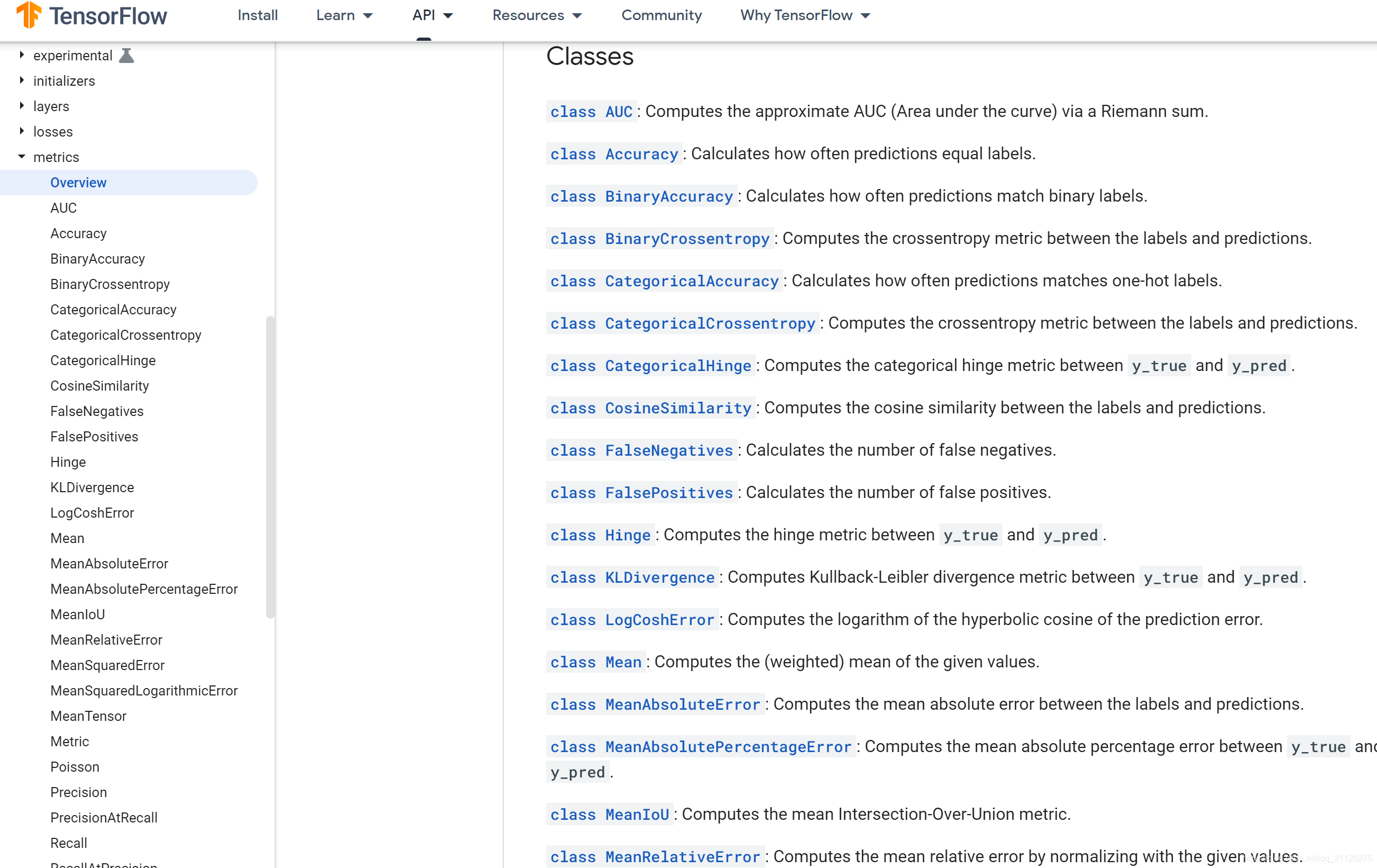
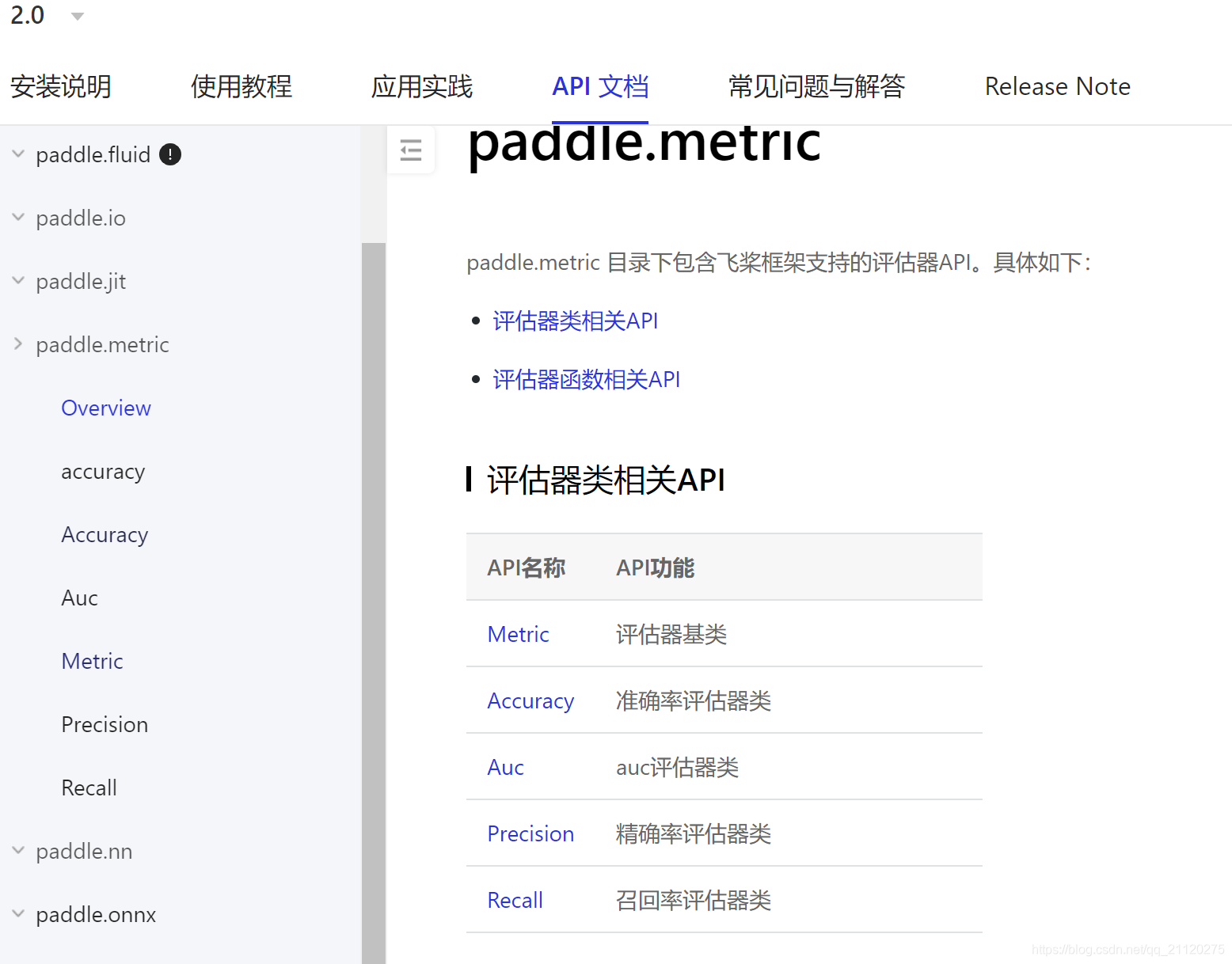
两者都或多或少提供了一些可以现成使用的对象,不过这一关TF2以多胜出,Paddle虽寡不敌众,然常用指标都有
-
Tensorflow2
-
PaddlePaddle
训练过程
训练过程的差异主要体现在函数的使用方式上
- Tensorflow2
EPOCHS = 5
for epoch in range(EPOCHS):
for images, labels in train_ds:
with tf.GradientTape() as tape:
# 前向传播
predictions = model(images/255)
# 计算本批次loss
loss = loss_object(labels, predictions)
# 梯度更新
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 汇总loss和acc
train_loss(loss)
train_accuracy(labels, predictions)
- PaddlePaddle
EPOCHS = 5
for epoch in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
images,labels = data[0].astype('float32')/255,data[1].astype('int64')
# 前向传播
predicts = model(images)
# 计算本批次loss
loss = paddle.nn.functional.cross_entropy(predicts, labels)
train_loss = paddle.mean(loss)
# 梯度更新
train_loss.backward()
optimizer.step()
optimizer.clear_grad()
# 汇总loss和acc
acc = train_accuracy.compute(predicts, labels)
train_accuracy.update(acc)
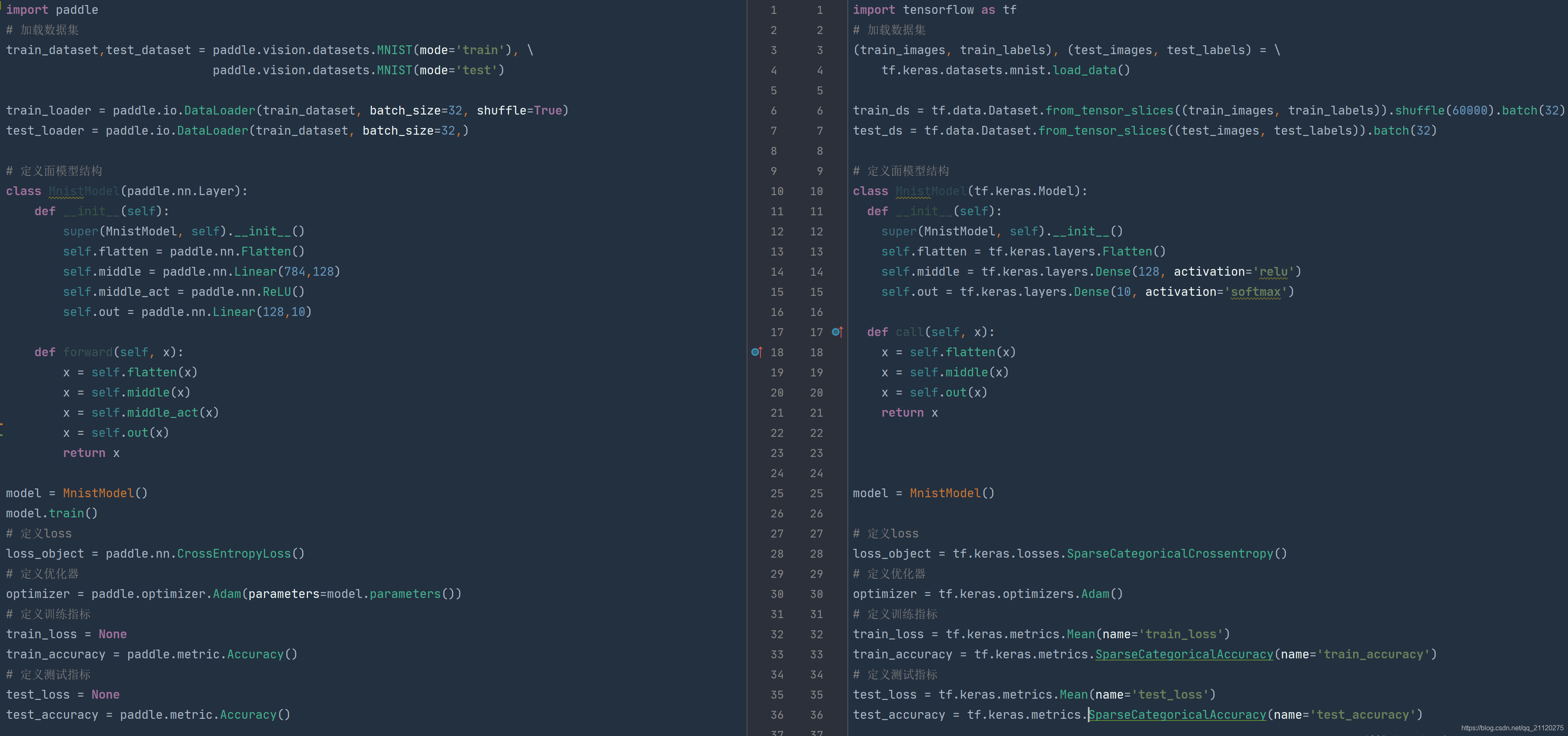
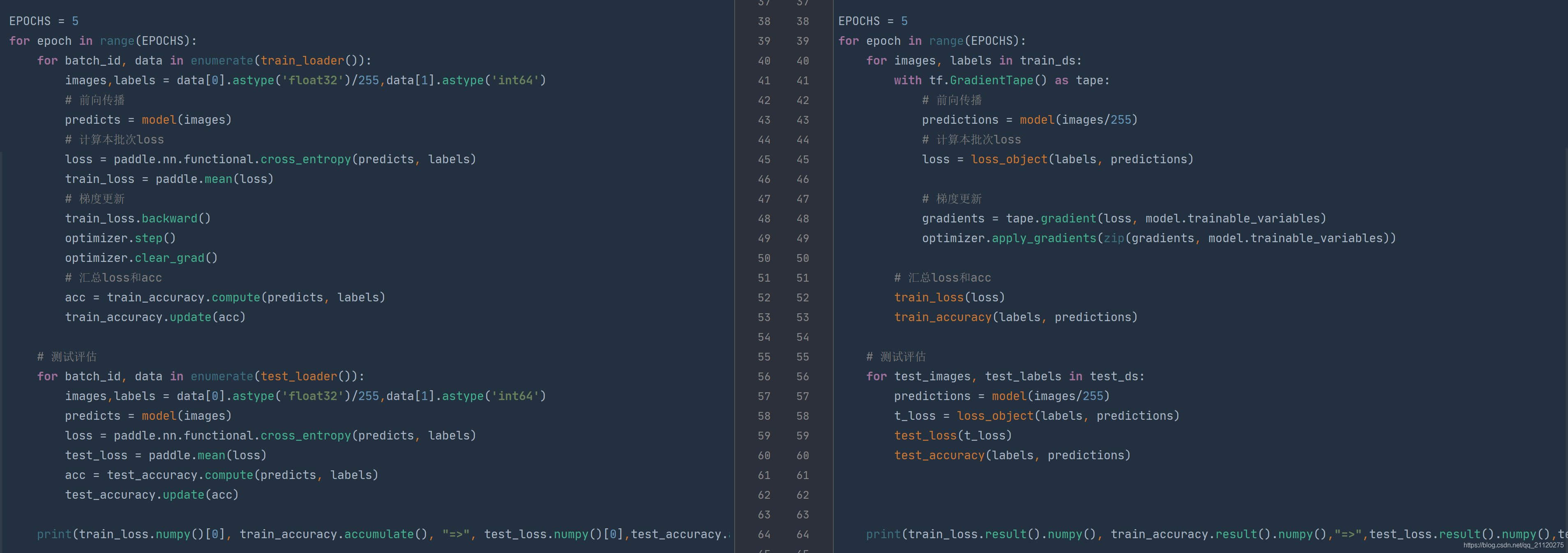
总体代码横向对比
看完了纵向对比,再来横向对比看看二者的写法
结语
从上面的写法上,不难看出,两者的总体流程还是比较相似,暂时并未发现逻辑上比较诡异的地方(比如糟糕的TF1,神一样的代码)
为什么Tensorflow的文档上说是专家入门呢?看起来明显比小白入门方式复杂了很多!
本人的理解是:
算法模型在使用过程中是千变万化的,一个既定的壳子(小白写法)由于封装太多,在应对复杂的场景时会显得不那么灵活,带来调试和计算过程拆解的不便,而要对算法模型进行灵活开发,就需要牢固的算法基础作为支撑,也就是所谓的专家!


















 194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











