







引言
文本从PaddlePadle和Tensorflow2的入门项目Mnist识别开始,对比一下两者在写法的不同
安装
安装方面都是基于pip或者conda的安装,没有可比性!
PaddlePaddle的安装直接参考PaddlePaddle安装
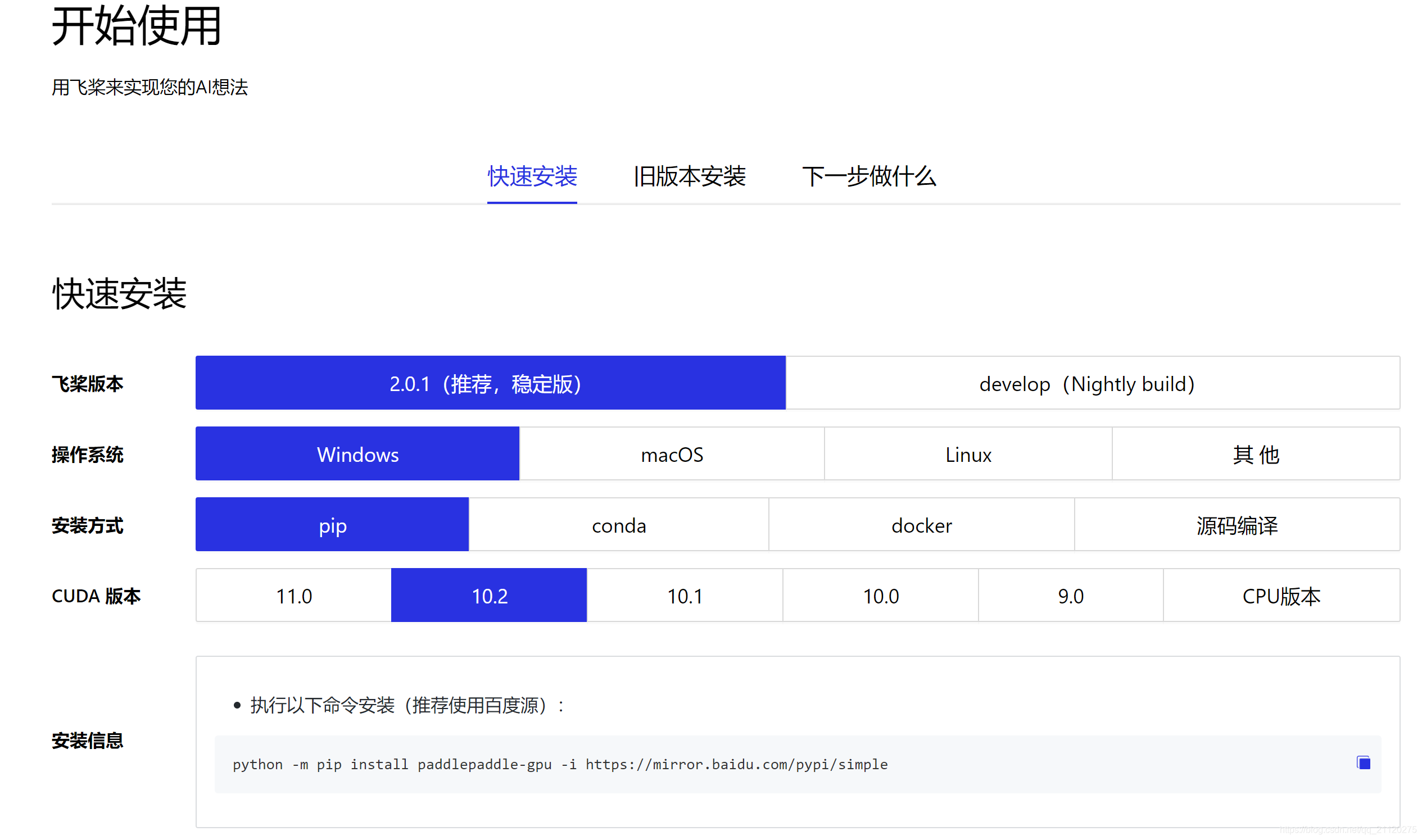
Tensorflow的安装直接在命令行输入即可
pip install tensorflow
相比之下,两者的安装都比较轻便,不过PaddlePaddle做了一个比较人性化的可选页面,这里点一个赞
数据集加载
两者对于Mnist数据集的加载都有简洁的接口,没什么可比性
- Tensorflow2
import tensorflow as tf
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data()
- PaddlePaddle
import paddle
# 加载数据集
train_dataset,test_dataset = paddle.vision.datasets.MNIST(mode='train'), paddle.vision.datasets.MNIST(mode='test')
模型定义
两者都支持Sequential方式定义面模型
- Tensorflow2
model = tf.keras.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
- PaddlePaddle
model = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 128),paddle.nn.ReLU(),
paddle.nn.Linear(128, 10),
)
模型配置
两者的配置大同小异,如果有人非要让我说出区别,那就是:方法名不同!!!
- Tensorflow2
model.compile(optimizer=tf.optimizers.Adam(),
loss=tf.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
- PaddlePaddle
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
模型训练
模型的训练上,都采用fit方法,这好像已经默认的统一标准了
- Tensorflow2
model.fit(train_images, train_labels, validation_data=(test_images, test_labels), epochs=5)
- PaddlePaddle
model.fit(train_dataset, eval_data=test_dataset, epochs=5, batch_size=64, verbose=1)
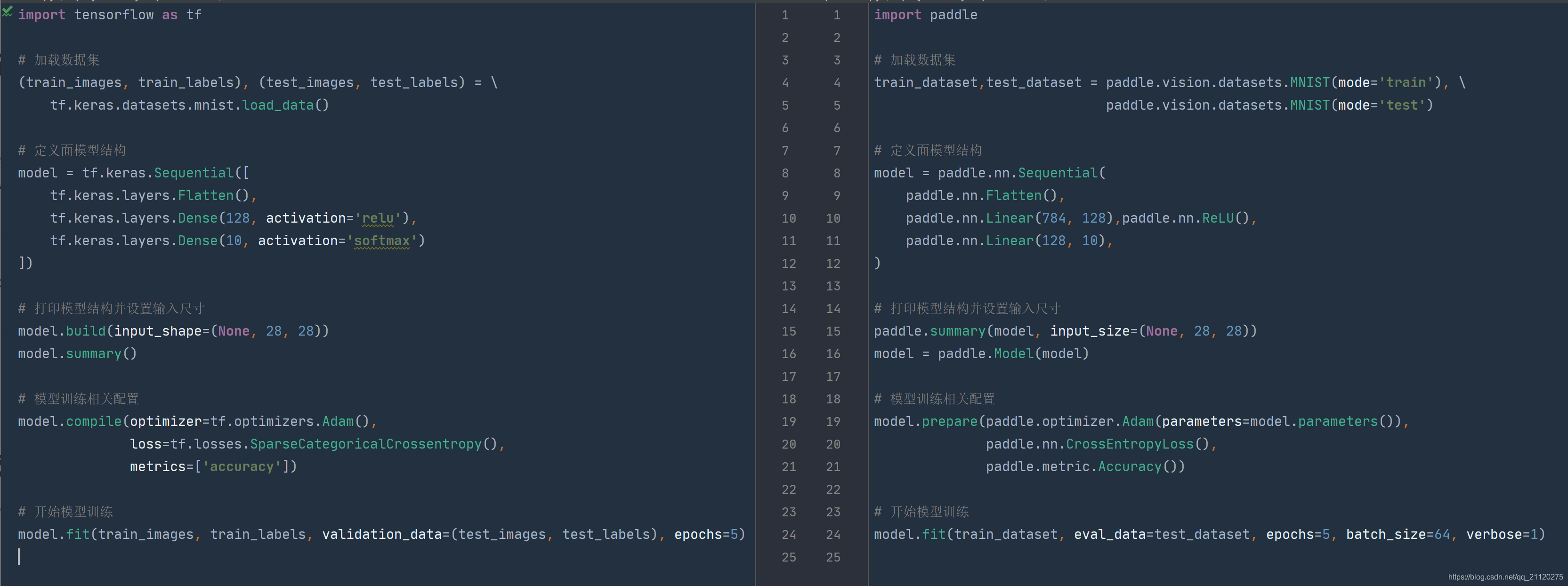
总体代码对比
看完了分段情况,下面来看看总体的对比情况
结语
从上述代码来看,两者的入门写法差距不大,基本上掌握了一个,可以很快掌握另外一个,个人可以根据喜好、团队选择等方面进行选择
另外值得一提的是百度的开发文档相对来说更加良心一些,api说明到demo的实现都有比较好的案例PaddlePaddle开发文档,后面有机会再看看进一步的写法对比!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











