







 文章介绍了吴恩达的机器学习课程,涵盖了监督学习,包括回归和分类,无监督学习,如聚类算法和降维,以及强化学习的基本概念。同时,讨论了线性回归模型的误差和成本函数,并详细阐述了梯度下降法在优化参数中的应用。
文章介绍了吴恩达的机器学习课程,涵盖了监督学习,包括回归和分类,无监督学习,如聚类算法和降维,以及强化学习的基本概念。同时,讨论了线性回归模型的误差和成本函数,并详细阐述了梯度下降法在优化参数中的应用。
吴恩达机器学习视频链接第一周
Week1
导入
机器学习包括:
- 监督学习 Supervised Learning
- 无监督学习 Unsupervised Learning
- 强化学习 Reinforce Learning
监督学习
- 训练:给数据集x和标签y
- 期待:仅仅给出x,预测出y
监督学习分类:
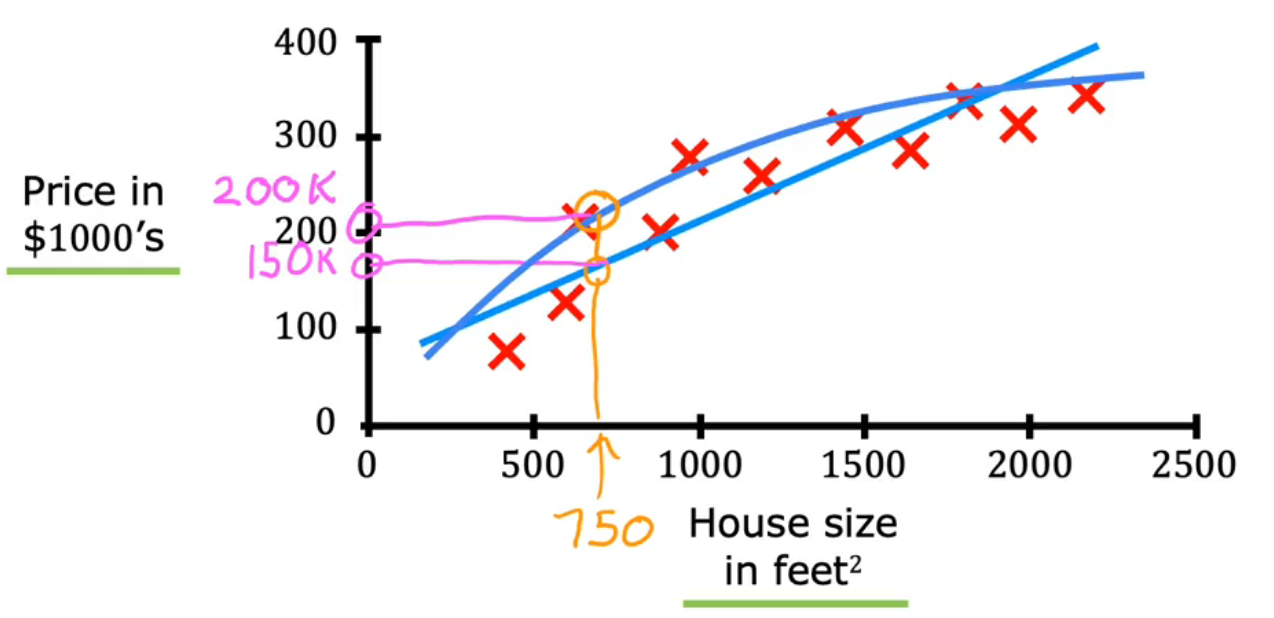
回归
Predict a number from infinitely many possible outputs
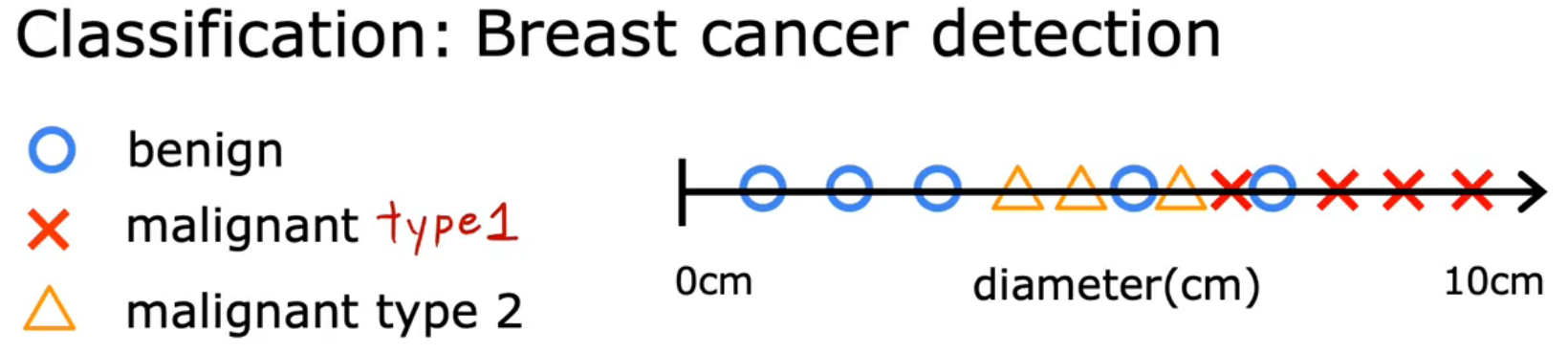
分类
Trying to predict only a small limitied number of classifies or categories——disperse
The case of One input:
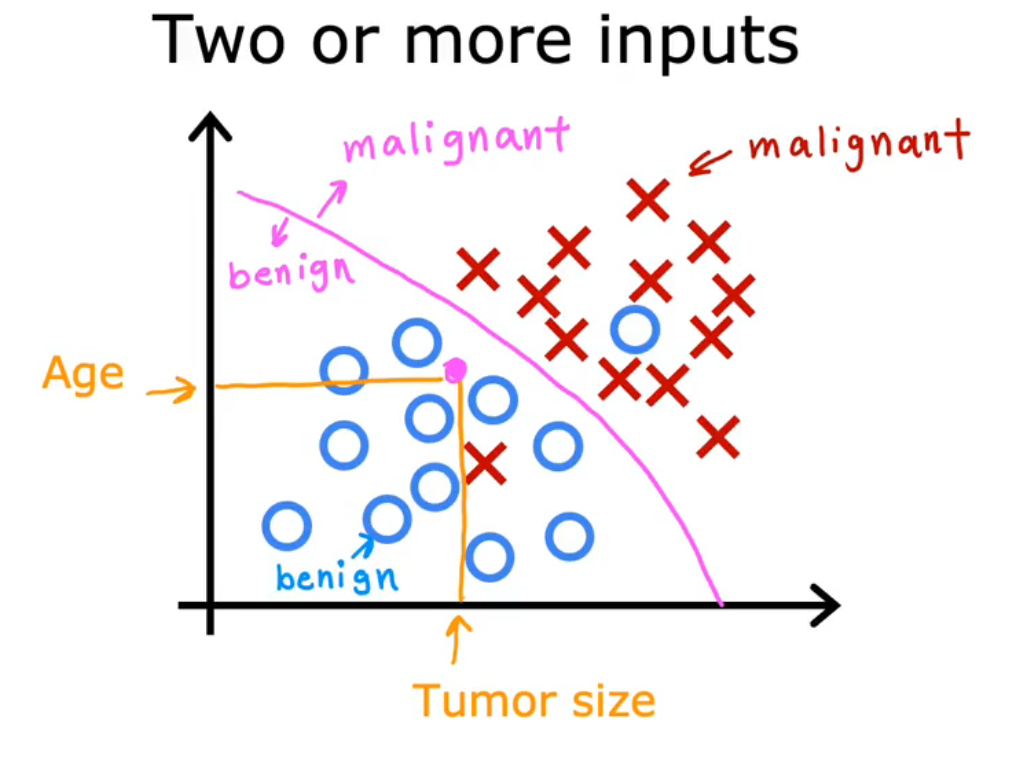
Multiple inputs:
无监督学习
有输入x,没有标签y
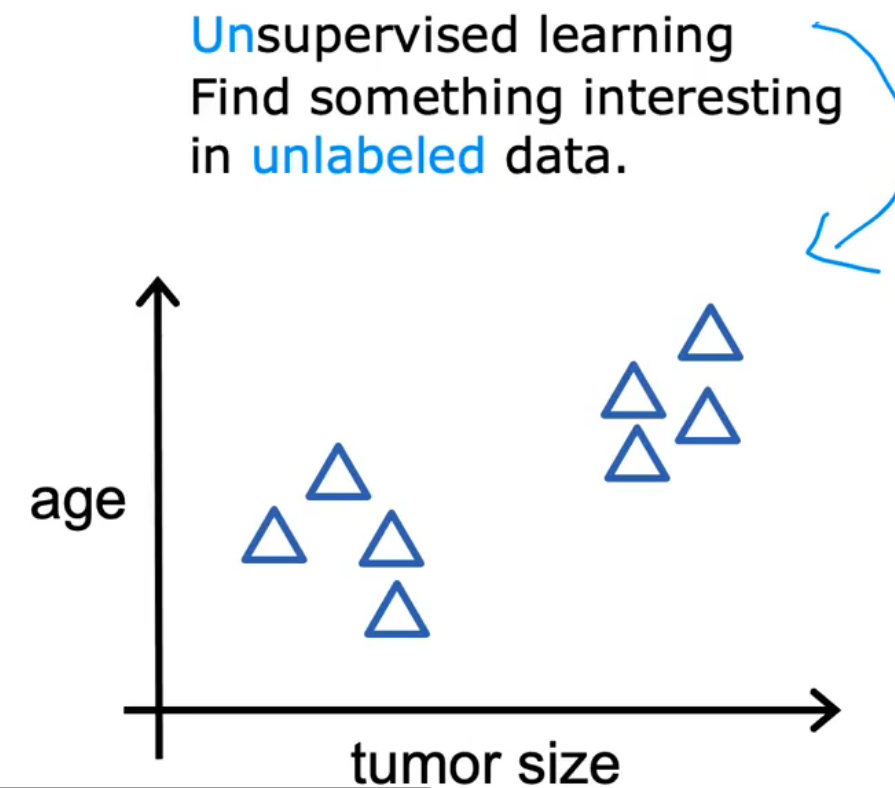
无监督学习分类:
聚类算法Clustering
将未标记的数据放到不同的簇中
examlpes:
- 谷歌新闻
- DNA序列
- 市场细分
异常检测Anomaly detection
降维Dimensionality reduction
3.回归模型
术语 Terminology
- Training set
- x x x= input variable / feature
- y y y = output / target variable
- m m m = total number of training examples
- ( x , y ) (x, y) (x,y) = single training example
-
(
x
(
i
)
,
y
(
i
)
)
(x^{(i)},y^{(i)})
(x(i),y(i)) = the
i
t
h
i^{th}
ith training example
- i == a specific column
- y ^ \widehat{y} y (y hat): prediction or estimate
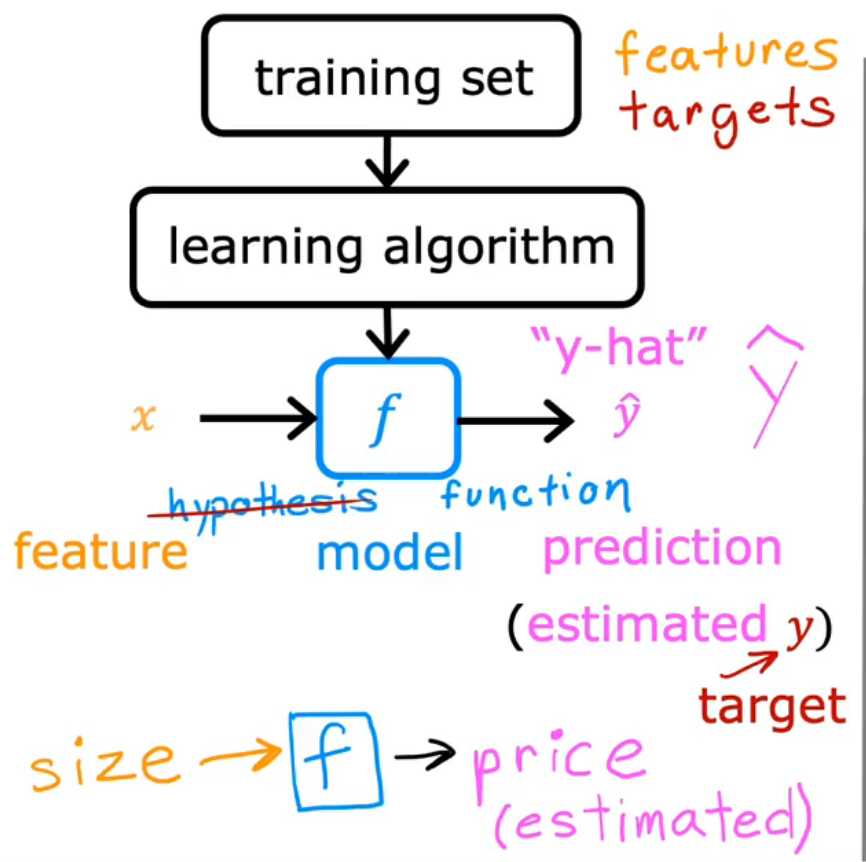
how to express f?—Liner regression
say the f is a linear function

Cost function
f ( x ) = w x + b f(x)=wx+b f(x)=wx+b
- w,b:parameters
- w:coefficients
- b:weights
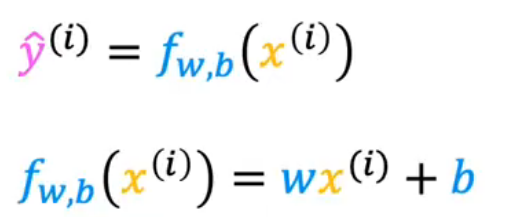
Cost Function
review: f w , b ( x ( i ) ) = w x ( i ) + b f_{w,b}(x^{(i)})=wx^{(i)}+b fw,b(x(i))=wx(i)+b
- error : y ^ ( i ) − y ( i ) \widehat{y}^{(i)}-y^{(i)} y (i)−y(i)
- Cost function(Squared error cost function 方差代价函数):
- J ( w , b ) = 1 2 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) 2 J(w,b)=\frac1{2m}\sum_{i=1}^{m}(\widehat{y}^{(i)}-y^{(i)})^2 J(w,b)=2m1∑i=1m(y (i)−y(i))2
- as we substitute the
y
^
\widehat{y}
y
with
f
w
,
b
x
(
i
)
f_{w,b}x^{(i)}
fw,bx(i), it changes to:
- J ( w , b ) = 1 2 m ∑ i = 1 m ( f w , b x ( i ) − y ( i ) ) 2 J(w,b)=\frac1{2m}\sum_{i=1}^m(f_{w,b}x^{(i)}-y^{(i)})^2 J(w,b)=2m1∑i=1m(fw,bx(i)−y(i))2
Cost function Intution—the relation between f(w) and J(w)
-
in the first part, we ignore b b b
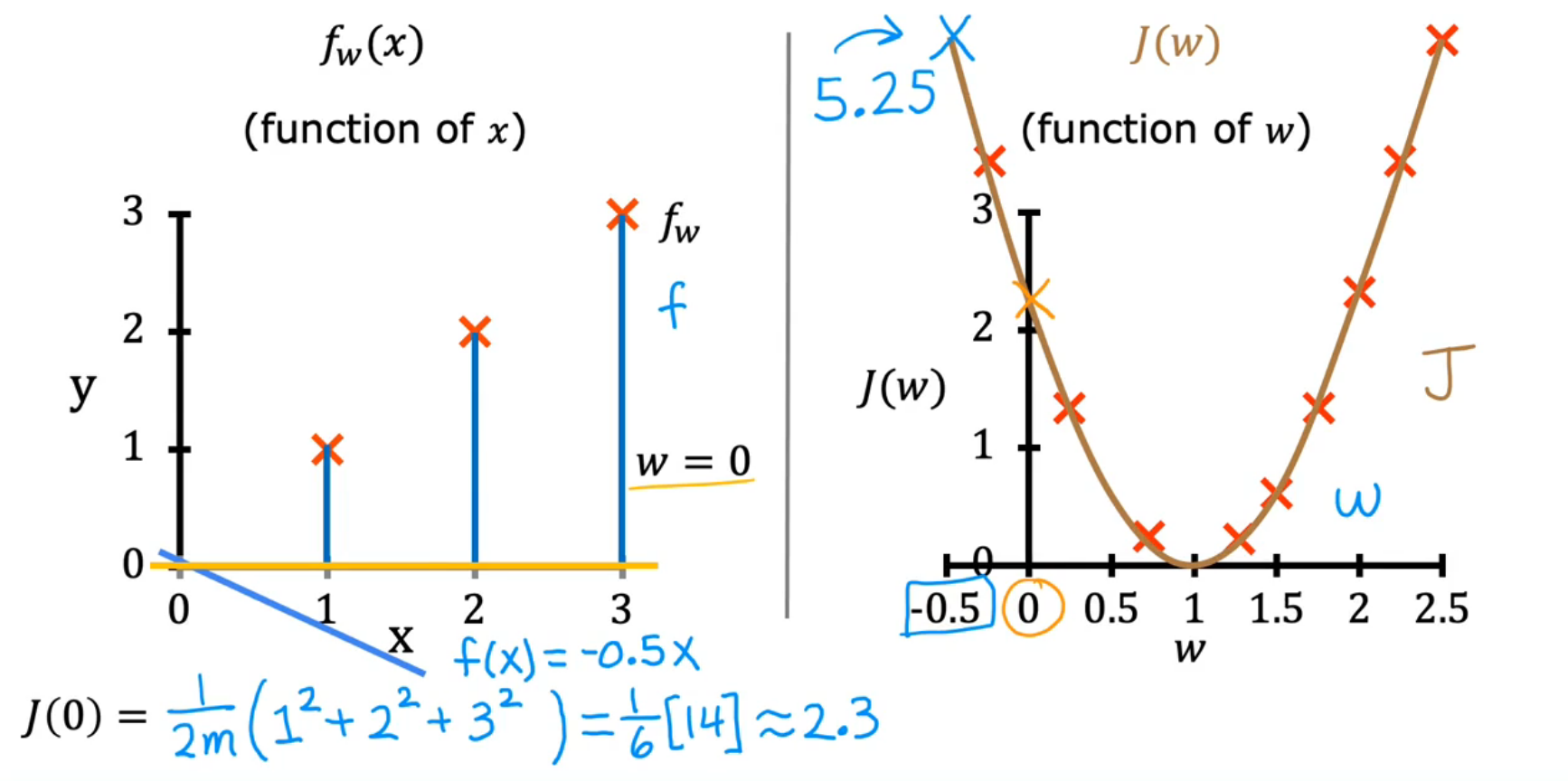
-
the second part:
- To approach the lowest point
4. Gradient decent梯度下降法
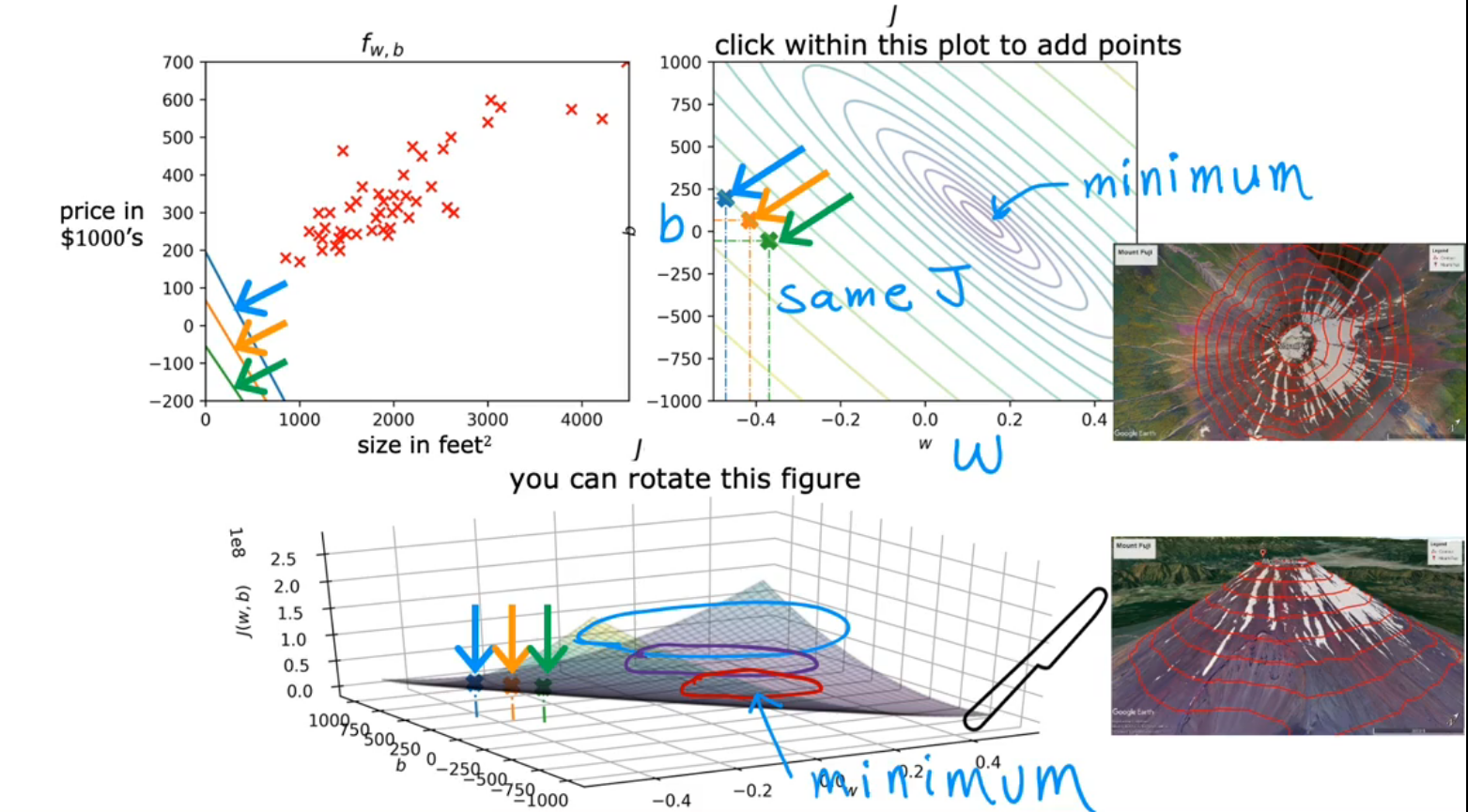
Problem description

The Visuable model:
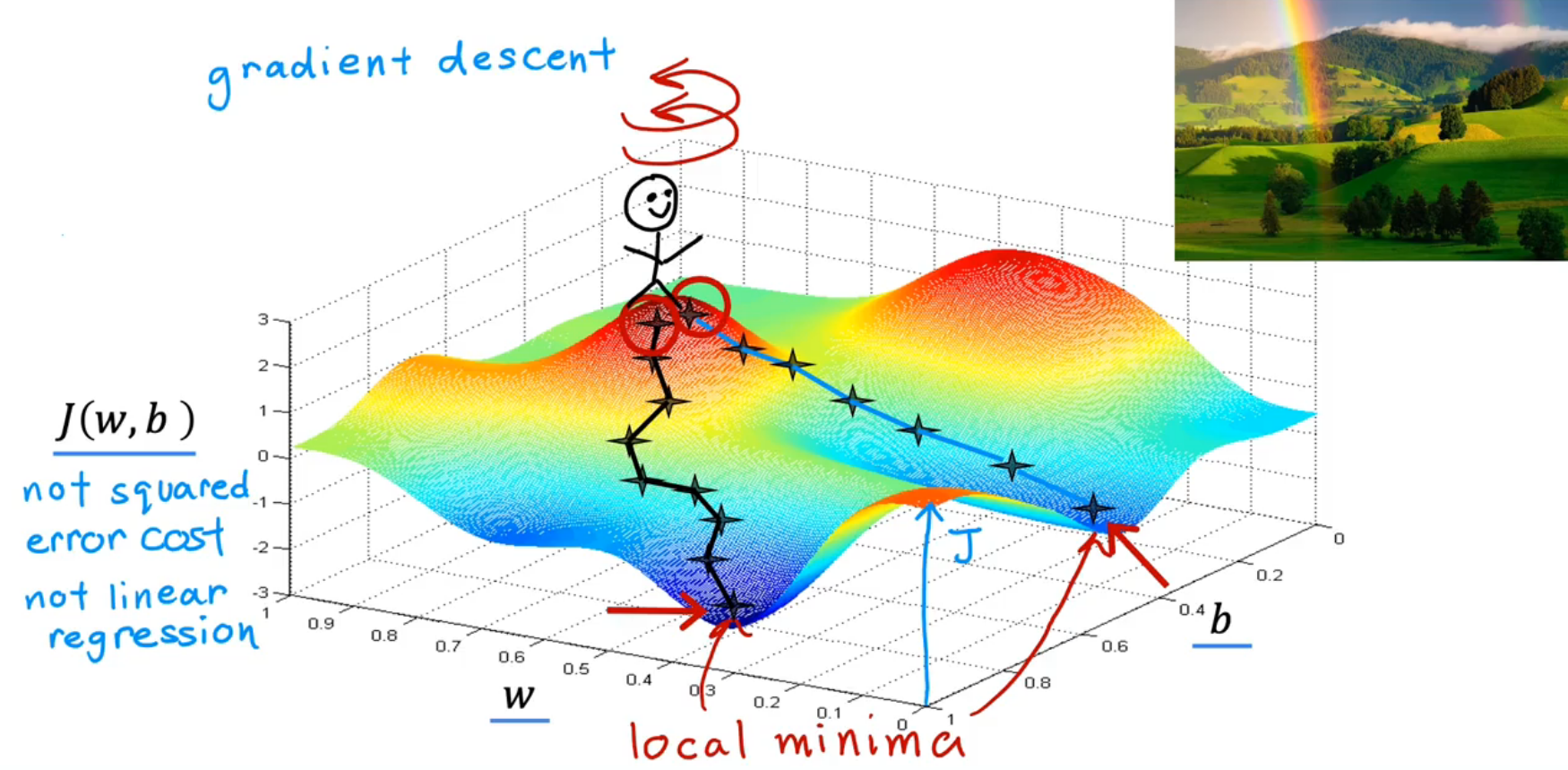
Gradient decent algorithm
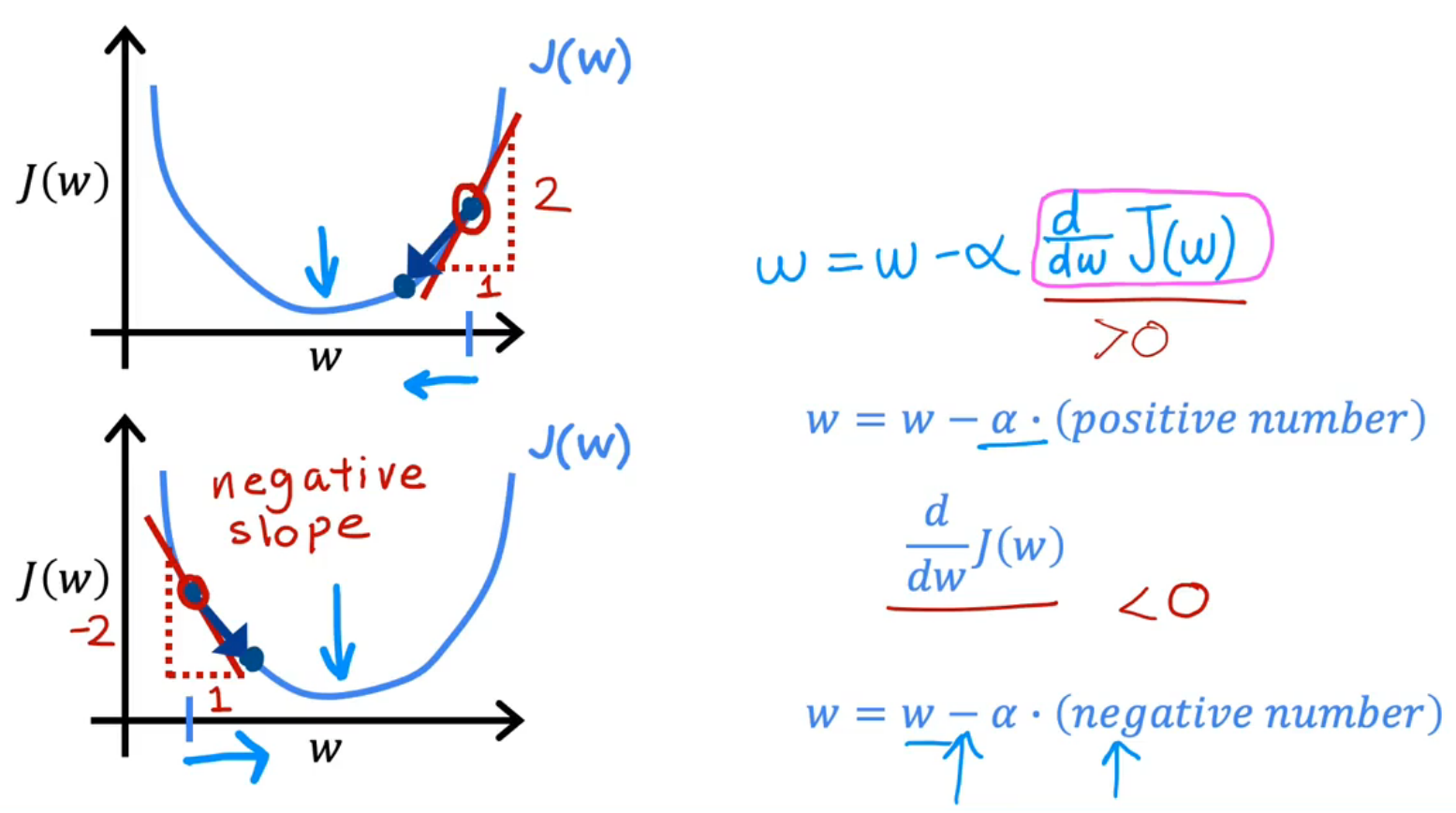
- w = w − α ∂ ∂ w J ( w , b ) w=w-\alpha\frac\partial{\partial w}J(w,b) w=w−α∂w∂J(w,b)
- α \alpha α means Learning rate
Algorithm description
- The right way of updating w and b is ----- Simultaneous update
Ordered Steps:
- t m p _ w = w − α ∂ ∂ w J ( w , b ) tmp\_w=w-\alpha\frac\partial{\partial w}J(w,b) tmp_w=w−α∂w∂J(w,b)
- t m p _ b = b − α ∂ ∂ b J ( w , b ) tmp\_b=b-\alpha\frac{\partial}{\partial b}J(w,b) tmp_b=b−α∂b∂J(w,b)
- w = t m p _ w w=tmp\_w w=tmp_w
- b = t m p _ b b=tmp\_b b=tmp_b
which ∂ \partial ∂ means partial derivative
Intution understangding of gradient descent
Learning Rate
- Too small: It will take a long time by each going a tiny tiny baby step
- Too large:
-
![]](https://i-blog.csdnimg.cn/blog_migrate/3daa6fd3ede881a50875ce0369b52338.png)
-
Overshoot, never reach minimum
-
Or, Fail to converge, even diverge
-
Gradient decent for liner regression
∂ ∂ w J ( w , b ) = \frac{\partial}{\partial w}J(w,b)= ∂w∂J(w,b)=
The Squared error cost is a bowl shape and only ONE minimum
- In other words, a convex function
Batch gradient descent
consider the whole data set each time


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









