







文章目录
协程
一些 文档
本文有些例子是来源于一些 python 书籍。
关于 python 我最想推荐的书是 <<flunt python>>
协程的概念
协程, 又称微线程, 纤程。 英文名
Coroutine, 是一种用户态的轻量级线程。
子程序, 或者称为函数, 在所有语言中都是层级调用, 比如 A 调用 B, B 在执行过程中又调用了 C, C 执行完毕返回, B 执行完毕返回, 最后是 A 执行完毕。
所以子程序调用是通过栈实现的(先进后出), 一个线程就是执行一个子程序。 子程序调用总是一个入口, 一次返回, 调用顺序是明确的。
而协程的调用和子程序不同。
线程是系统级别的它们由操作系统调度, 而协程则是程序级别的由程序根据需要自己调度。
在一个线程中会有很多函数, 我们把这些函数称为子程序, 在子程序执行过程中可以中断去执行别的子程序, 而别的子程序也可以中断回来继续执行之前的子程序, 这个过程就称为协程。
也就是说在同一线程内一段代码在执行过程中会中断然后跳转执行别的代码, 接着在之前中断的地方继续开始执行。
协程拥有自己的寄存器上下文和栈。 协程调度切换时, 将寄存器上下文和栈保存到其他地方, 在切回来的时候, 恢复先前保存的寄存器上下文和栈。
因此: 协程能保留上一次调用时的状态(即所有局部状态的一个特定组合) , 每次过程重入时, 就相当于进入上一次调用的状态,
换种说法: 进入上一次离开时所处逻辑流的位置。
概念
我们要理解 非阻塞 和阻塞
异步和同步
异步不代表 非阻塞。
同步也不代表阻塞
并发也不代表非阻塞
异步,线程,并行.三个概念是不同的.(关于 并发和 并行可以看我前面的博客)
并行的时候 也可以是并发的。(但并发的时候不一定是并行的)
其实我们完全可以 抛开线程 进程 来看待并行 和并发 这样会好理解很多
同步: 先执行第一个事务,如果遇到阻塞(time.sleep()),会一直等待,直到第一个事务执行完毕,
才会执行第二事务 前面也说过 这个就是 协程的 缺点。
整个程序 会被挂起。
或者说 就是在发出一个
调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
异步:与同步是相对的,指执行第一个事务时候,如果遇到阻塞,会直接执行第二个事务,不会等待.
网页加载 的 异步 就是类似于这样的
也可以说 调用在发出之后,这个调用就直接返回了,所以没有返回结果。
换句话说,当一个异步过程调用发出后,
调用者不会立刻得到结果。
而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
阻塞和非阻塞是一种状态
代表的是 同步和异步 等待调用返回的这个时刻的过程。 在等待中 就是阻塞,不等待就是非阻塞
比喻:
我们下课上厕所,你在门口等我一起回教室,这就是被阻塞了。 如果我上厕所,你直接会教室了,那就是非阻塞的,需要我上完厕所告诉你我上好厕所了。 大致就是这么个意思。
协程的优点:
(1) 无需线程上下文切换的开销, 协程避免了无意义的调度, 由此可以提高性能(但
也因此, ‘程序员必须自己承担调度的责任’, 同时, 协程也失去了标准线程使用多 CPU 的能力)
(2) 无需原子操作锁定及同步的开销
(3) 方便切换控制流, 简化编程模型
( 4) 高并发+高扩展性+低成本: 一个 CPU 支持上万的协程都不是问题。 所以很适合用于高并发处理。
协程的缺点:
(1) 无法利用多核资源: 协程的本质是个单线程,它不能同时将单个 CPU 的多个核用上
协程需要和进程配合才能运行在多 CPU 上.当然我们日常所编写的绝大部分应用都没有这个必要, 除非是 cpu 密集型应用。
(2) 进行阻塞(Blocking) 操作(如 IO 时) 会阻塞掉整个程序。(因为单线程的)
我走的坑
切记 这一条 (2) 进行阻塞(Blocking) 操作(如 IO 时) 会阻塞掉整个程序。
然后不要走火入魔 ,因为我就跑去思考为啥 阻塞的操作。 就会 将整个程序阻塞。
我就想为啥我的 time.sleep 会被阻塞 。 我要怎么让他不阻塞。
然后我就去看了 gevent 的源码 。 发现也是 用了其他手段。 比如线程+协程切换。是结合起来使用的。
但是我当时就钻了牛角尖。 我就要 用纯 yield 协程实现。 asyncio 我也不用我还特地看了源码,他也用了其他的方式。 我要 用 yield 切换阻塞任务。 还要 让他异步。
想想走入了死胡同,还有点不甘心的感觉。
这个时候我们应该回头看一下 协程的缺点 那么 也就 应该能释然了吧。
所以希望大家 ,也能注意这一点,不要像我一样想太多。导致浪费了一些时间。(虽然我也从中有很多体悟。)
yield
# 使用yield
# next 函数 教程链接
# https://www.runoob.com/python/python-func-next.html
# yield 生成器 链接 浅析
# https://www.runoob.com/w3cnote/python-yield-used-analysis.html
# 执行到 yield 时, 函数就返回一个迭代值,下次迭代时,代码从 yield 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。
# yield 其实有两个作用 一个是产出。
# 一个是接收。 接收需要 外部 send 数据 给 yield
def foo():
print('starting')
while True:
res= yield 4
print('res:',res)
'''
在函数中使用了yield,则该函数就称为了一个生成器
yield的理解
1.当成return 程序返回
2.当成生成器
'''
g=foo() #g就是一个生成器对象
print(type(g))
print(next(g))
print('*'*20)
print(next(g))
运行结果:
从绿色来看。 返回的是生成器类型。
我们调用 next 启动(生成器 都需要使用 next 来启动或者叫做预激(预先激活))
打印start 以及 4
4 相当于是 return 回来的值。注意这里没有打印 res:4
之所以打印了 4 是 因为 4 在那个状态时返回值。 可以理解为
res=yield 4
# 等价于下面两句 当然 真实的是无法执行的。只是 方便理解。
return 4
# 就当这里的 return 不终止函数 , 只是暂停。
res =return
# return 空的东西 当然是 None 了 这一步 是在 下次执行 next 的时候 从这步开始。 然后这一步的 return 是不会 终止 函数的。
# 因为这里只是一个 比喻。 这个 就是 对 yield 的功能描述。
所以 后面打印了 res:None 这个地方 要有值 , 只有我们 send 过去值。 才会 将接收的值 赋值给 res

执行 过程 gif 。

使用yield 实现协程
import time
def A():
while True:
print('-------A--------')
yield
time.sleep(0.5)
def B(c):
while True:
print('--------B--------')
c.__next__()
# 就是调用next函数
# next(c) 也是一样的 看个人习惯
time.sleep(0.5)
a = A() #生成一个生成器对象
B(a)
这个 简单例子 只是 无限的交错 打印 B A B A

send 发送一个参数
def foo():
print('starting')
while True:
res = yield 4
print('res:',res)
g = foo()
print(next(g))
# print(next(g))
print(g.send(10))
可以看到 我们send 了一个值。 然后 res 那里 就 不再是 None 了

生成器状态查看
from inspect import getgeneratorstate
该函数会返回下述字符串中的一个。
'GEN_CREATED' 等待开始执行。
'GEN_RUNNING' 解释器正在执行。
'GEN_SUSPENDED' 在yield表达式处暂停。
'GEN_CLOSED' 执行结束。
from inspect import getgeneratorstate
def foo():
print('starting')
result=None
total=0
while True:
res = yield result
total+=res
result=total
g = foo()
getgeneratorstate(g) # 查看生成器状态
print(next(g))
# print(next(g))
print(g.send(10))
稍微修改一下。 就是一个 加法器。 你只要一直 send 他就会一直将这个值 加上去。

与创建生成器的方式一样,调用函数得到生成器对象。
首先要调用next(...)函数(当然你也可以使用for 循环遍历,for 循环会隐式的调用 next),因为生成器还没启动,没在yield语句处暂停,所以一开始无法发送数据。(会报错)
当然一开始你就send None 也是可以激活的。 除此之外都是报错。

使用协程的好处是,
total声明为局部变量即可,无需使用实例属性或闭包在多次调用之间保持上下文。
下面是一个简单的使用 实例属性 以及 闭包来进行 上下文保持的 简单例子。
如果不这样写的话。 也可以定义一个全局变量来维持上下文。
我这里是在
funIn函数上挂了个属性。.result

使用装饰器进行预激活
调用g.send(x)之前,记住一定要调用next(g)。为了简化协程的用法,有时会使用一个预激装饰器
from functools import wraps
@coroutine
def foo():
print('starting')
result=None
total=0
while True:
res = yield result
total+=res
result=total
def coroutine(func):
@wraps(func)
def primer(*args,**kwargs):
gen=func(*args,**kwargs)
next(gen)
return gen
return primer
执行结果 。 可以看到已经 自动激活了。 我们就可以直接 send 值

使用yield from句法 调用协程时,会自动预激,因此与我们写的 @coroutine等装饰器不兼容。标准库里的asyncio.coroutine装饰器不会预激协程,因此能兼容yield from句法。
关于 @wraps 这是一个属性修改的装饰器。
用我们之前写的装饰器函数 的简单实例 来说明。
# 功能函数三个参数
import time
def writeLog(func):
print('访问了方法名:',func.__name__,'\t时间:',time.asctime())
def funOut2(func):
def funcIn(a,b,c):
writeLog(func)
return func(a,b,c)
return funcIn
@funOut2
def add(a,b,c):
"""
返 回 3 个 数 的 和
"""
return a+b+c
result=add(10,20,30)
print('三个数的和:',result)
# ----------------------------
# 加 wraps
# 功能函数三个参数
import time
from functools import wraps
def writeLog(func):
print('访问了方法名:',func.__name__,'\t时间:',time.asctime())
def funOut2(func):
@wraps(func)
def funcIn(a,b,c):
writeLog(func)
return func(a,b,c)
return funcIn
@funOut2
def add(a,b,c):
"""
返 回 3 个 数 的 和
"""
return a+b+c
运行结果
不加 wraps

我们发现 add 的名字已经不叫 add 了 , 叫 funOut2 中的 funcIn(funcIn 在 funOut2 的 locals 字典中。)
这可能会干扰我们的工作。 例如内置的help 将失效
将wraps 用到 funIn 函数之后 他就会把内部函数的重要元数据(实例字典中的一些信息 . 比如 文档字符串。 函数名字 等) 全部复制到外围 函数上。
加 wraps

终止协程 和 异常处理
协程中未处理的异常会向上冒泡,传给next或send的调用方(即触发协程的对象)
我们这里还是使用 前面 预激 装饰器 的例子。
from functools import wraps
def coroutine(func):
@wraps(func)
def primer(*args,**kwargs):
gen=func(*args,**kwargs)
next(gen)
return gen
return primer
@coroutine
def foo():
print('starting')
result=None
total=0
while True:
res = yield result
total+=res
result=total

由于在协程内没有处理异常,协程会终止。如果试图重新激活协程,会抛出StopIteration异常
出错的原因是,发送给协程 的
'a'值不能加到total变量上。
使用 close 终止 协程

使用 throw 终止协程

这里说明了 异常 如果未处理将导致 协程终止。
使用close和throw方法控制协程
class TestException(Exception):
"""
为这次演示定义的异常类型。
"""
@coroutine
def test_exception_handing():
print("-> 协程开始" )
while True:
try:
x=yield
except TestException:
print("+++ TestException 异常处理. 继续... +++")
else:
print("-> 协程接收 :{!r}".format(x))
raise RuntimeError("这一行永远不会被执行。")
使用 close 终止 协程
使用 throw 终止协程

让协程返回值
关于 namedtuple的 基本用法 示例

from functools import wraps
from collections import namedtuple
Result=namedtuple("Result","result count")
def coroutine(func):
@wraps(func)
def primer(*args,**kwargs):
gen=func(*args,**kwargs)
next(gen)
return gen
return primer
@coroutine
def foo():
print('starting')
result=None
total=0
count=0
while True:
res = yield result
if res is None:# 需要一个退出循环的条件
break
total+=res
result=total
count+=1
return Result(result,count)

获取值。

获取协程的返回值虽然要绕个圈子,但这是PEP 380定义的方式
yield from结构会在内部自动捕获StopIteration异常。
这种处理方式与for循环处理StopIteration异常的方式一样:
循环机制使用用户易于理解的方式处理异常。
对yield from结构来说,解释器不仅会捕获StopIteration异常,还会把value属性的值变成yield from表达式的值。
yield from 的使用
首先要知道,yield from是全新的语言结构。
它的作用比
yield多很多,因此人们认为继续使用那个关键字多少会引起误解。
在其他语言中,类似的结构使用await关键字,这个名称好多了,因为它传达了至关重要的一点:
在生成器
gen中使用yield from subgen()时(subgen子生成器),subgen子生成器 ,会获得控制权,把产出的值传给gen的调用方(在我们的例子里,g或者是后面例子中的main 中的 group就是调用方。),
即调用方可以直接控制subgen。与此同时,gen会阻塞,等待subgen终止。
使用yield from句法 调用协程时,会自动预激协程。 for 循环也是一样的。
原来的写法

yield from的写法
def gen():
yield from "onepisYa"
yield from range(5)
print("协程结束")
# range(5) 获得控制权
# 把 产出值 传给 gen()的调用方 g
# g 可以直接控制 range(5)
# 这个时候 gen 会阻塞
# (阻塞代表无法执行后面的程序,你需要 对 yield i 那一层yeild 进行操作 如果"onepis"换成生成器,那你的 操作都是直接作用于生成器,
# 比如 gen().send 那么 就send 一层一层传递到了最内层。(先到gen 内部和yield 再到 “onepis” 内部的yield(如果onepis是生成器),这里仅仅只是为了描述过程。)
# 等待 range(5) 终止
# 然后恢复协程 gen()


def chain(*iterables):
for i in iterables:
yield from i
[*chain("onepis","666")]

yield from的主要功能是打开双向通道,把 最外层的调用方 (就是我们以前的g)与 最内层的子生成器 (可以理解为一个管道) 连接起来,这样二者可以直接发送和产出值,还可以直接传入异常,而不用在位于中间的协程中添加大量处理异常的样板代码
来看一下 flunt python 这本书中的一个例子。
- 委派生成器在
yield from表达式处暂停时,调用方(main)可以直接把数据发给子生成器, - 子生成器再把产出的值发给调用方。
- 子生成器返回之后,解释器会抛出
StopIteration异常,并把返回值附加到异常对象上,此时委派生成器会恢复
from collections import namedtuple
Result = namedtuple("Result", "result count")
# foo 子生成器
def foo():
result = None
total = 0
count = 0
from time import sleep
while True:
res = yield
if res is None: # 需要一个退出循环的条件
break
total += res
result = total
count += 1
# sleep(1)
# 测试的时候 把 sleep 去掉是可以的
# 因为 这里只是告诉我们 不要在 协程中使用 阻塞型 io 或者函数
return Result(result, count)
# 委派生成器 带有 yield from 的函数
def grouper(results, key):
while True:
results[key] = yield from foo()
# 调用子生成器 foo 后,在yield from表达式处暂停
# 客户端代码 。 即调用方
def main(data):
results = {}
from time import time
s = time()
for key, values in data.items():
group = grouper(results, key)
next(group)
for value in values:
group.send(value)
# 内层for循环调用group.send(value),直接把值传给子生成器 foo
# 同时,当前的grouper实例(group)在yield from表达式处暂停。
group.send(None) # 这个 send None 非常重要
# 把None传入grouper,导致当前的 foo 实例终止,
# 也让grouper继续运行,再创建一个 foo 实例,处理下一组值。
# 如果外层for循环的末尾没有 group.send(None),那么foo子生成器永远不会终止,委派生成器group永远不会再次激活,
# 因此永远不会为 results[key] 赋值。
print_result(results)
print("耗时 ——> ", time() - s, " 秒")
# 打印结果的方法
def print_result(results):
for key, result in sorted(results.items()):
print("{} : result(sum) -> {:2} | count -> {:.2f}".format(
key, result.result, result.count))
data = {
'girls;kg': [40.9, 38.5, 44.3, 42.2, 45.2, 41.7, 44.5, 38.0, 40.6, 44.5],
'girls;m': [1.6, 1.51, 1.4, 1.3, 1.41, 1.39, 1.33, 1.46, 1.45, 1.43],
'boys;kg': [39.0, 40.8, 43.2, 40.8, 43.1, 38.6, 41.4, 40.6, 36.3],
'boys;m': [1.38, 1.5, 1.32, 1.25, 1.37, 1.48, 1.25, 1.49, 1.46],
}
main(data)
其实依然是阻塞的 我加了 sleep 耗时 38 秒
因为 有 38 个数据
看完这里 我找到了 书里的一句话 。 绝对不要 在 协程中使用 阻塞型io 因为这会阻塞整个程序 。 导致 我们的程序 变为 同步的。

这个试验想表明的关键一点是,如果子生成器不终止,委派生成器会在
yield from表达式处永远暂停。
如果是这样,程序不会向前执行,因为yield from(与yield一样)把控制权转交给客户代码(即,委派生成器的调用方)了。显然,肯定有任务无法完成。
引用 自 flunt python的一些例子
“把迭代器当作生成器使用,相当于把子生成器的定义体内联在
yield from表达式中。此外,子生成器可以执行return语句,返回一个值,而返回的值会成为yield from表达式的值。”
子生成器foo产出的值都直接传给委派生成器grouper的调用方(即客户端代码)main。
使用
send()方法发给委派生成器的值都直接传给子生成器。
如果发送的值是None,那么会调用子生成器foo·的 __next__( )方法。
如果发送的值不是None,那么会调用子生成器的send( )方法。
如果调用的方法抛出StopIteration异常(即foo中抛出StopIteration异常),那么委派生成器(grouper)恢复运行。
任何其他异常都会向上冒泡, 传给
委派生成器(grouper)。
生成器退出时,生成器(或子生成器)(foo)中的return expr表达式会触发StopIteration(expr)异常抛出。
yield from表达式的值是子生成器foo终止时传给StopIteration异常的第一个参数。
如果字数太多 可以只看 桃心 这几行字。
❤❤
yield from结构的另外两个特性与异常和终止有关。
- 传入委派生成器的异常,除了
GeneratorExit之外都传给子生成器的throw( )方法。 - 如果调用
throw( )方法时抛出StopIteration异常,委派生成器恢复运行。 StopIteration之外的异常会向上冒泡,传给委派生成器。
- 如果把
GeneratorExit异常传入委派生成器,或者在委派生成器上调用close( )方法,那么在子生成器上调用close( )方法,如果它有的话。 - 如果调用
close( )方法导致异常抛出,那么异常会向上冒泡,传给委派生成器;
否则,委派生成器抛出GeneratorExit异常。
yield from 的具体语义很难理解,尤其是处理异常的那两点。
在单个线程中使用一个主循环驱动协程执行并发活动。
使用协程做面向事件编程时,协程会不断把控制权让步给主循环,激活并向前运行其他协程,从而执行各个并发活动。
这是一种协作式多任务(顺序执行):协程显式自主地把控制权让步给中央调度程序。
多线程实现的是抢占式多任务(乱序运行),调度程序可以在任何时刻暂停线程(即使在执行一个语句的过程中),把控制权让给其他线程。
简单测试
这是我测试的 yield 阻塞的 测试
并且是一开始就阻塞。
def sleep_():
while True:
x = yield
if x is None: # 需要一个退出循环的条件
break
from time import sleep, time
s = time()
# sleep(x)
# 记得测试完 注释掉 sleep
# 因为 只是测试 让我们不要在 协程中使用
# 阻塞型 方法和 函数 以及io
# 会导致 整个程序 阻塞。
# 无法异步。
print(time() - s)
return time() - s
# 如果我 send 2 有 3个 2 秒 阻塞的话 是 6 秒
# 如果是 非阻塞的话 那么 应该是 2秒
def grouper():
while True:
pay_time = yield from sleep_()
print(pay_time)
def main():
g1 = grouper()
g2 = grouper()
g3 = grouper()
next(g1)
next(g2)
next(g3)
from time import time
s = time()
g1.send(2)
g1.send(None)
g2.send(2)
g2.send(None)
g3.send(2)
g3.send(None)
print(time() - s, "秒")
if __name__ == "__main__":
main()

看完这里 我找到了 书里的一句话 。 绝对不要 在 协程中使用 阻塞型io 因为这会阻塞整个程序 。 导致 我们的程序 变为 同步的。
关于如何区分委派生成器子生成器
- 调用方
最外层的非协程非生成器函数 可以理解为 调用方 - 委派生成器
最外层 的生成器函数 或者对象 - 子生成器
真正实现功能的 生成器对象或者函数。
这里是多线程的 一个对比。
from threading import Thread
def sleep_(x):
from time import sleep, time
s = time()
sleep(x)
print(time() - s)
return time() - s
def main(num):
from time import time as t
s = t()
for i in range(1, num + 1):
locals()[f't{i}'] = Thread(target=sleep_, args=(i, ))
locals()[f't{i}'].start()
for i in range(1, num + 1):
locals()[f't{i}'].join()
# 注意不要 .start 一个 线程对象之后 马上对他使用join
# 这样会导致 虽然是并发 但是是却是同步的 。
# 并发
# 而应该在全部线程 start 之后再 使用 join 去阻塞
print("耗时", t() - s, "秒")
if __name__ == "__main__":
main(10)
这是多线程的效果。
虽然我们阻塞了。但是 依然是 只花费 耗时最多的那个 线程的时间。

yield 实现生产者 消费者模式
# 生产者和消费者传递数据
def produce(c):
for i in range(10):
print('生产者生产产品并送出:%d'%i)
c.send(str(i))
def consumer():
while True:
res = yield
print('从生产者那里send过来的资源,消费者接收并消费:', res)
if __name__ == "__main__":
c = consumer() # 生成器
# 使用next执行生成器
next(c)
produce(c)
其实非常简单。 就是 这边 send 一个数据 过去。 那边用 yield 接收。
如果不用yield 返回数据 那么就无需 在 yield 后面添加参数 比如 yield 4 或者 yield 变量名或者表达式
flunt python 中的例子(扩展。初步了解使用无需看这一节。)
使用协程做离散事件仿真
协程是asyncio包的基础构建。通过仿真系统能说明如何使用协程代替线程实现并发的活动,而且对理解 asyncio 包 有极大的帮助。
如何只使用标准库提供的功能实现一个特别简单的离散事件仿真系统。
目的是增进你对使用协程管理并发操作的感性认知。让我们洞悉asyncio、Twisted和Tornado等库是如何在单个线程中管理多个并发活动的。
学到这里我发现了一个问题 单纯的yield 和 yield from 似乎无法做到非阻塞的 执行程序(因为一开始 就说了 协程的缺点就是 会被 阻塞型 io 阻塞整个 程序 啊)
感觉自己蠢哭了
当然这里是 并发的 因为 由多个对象来调用的
但是与我想象的能提升效率似乎 不太一样。
这个好像目前看来 只能进行 管理 以及传递数据。
也就是说 主要在于理解思路。
好了 坑踩过了。朋友们测试的时候 记得 不要纠结上面的问题 。可以将我 的sleep 注释掉
time 指的是第 几分钟。 出门 上客 下客 回家。
argparse 这个暂时可以忽略 ,重点 是 taxi_process , run 次之。
import random
import collections
import queue
import argparse
from time import time as t
from time import sleep
DEFAULT_NUMBER_OF_TAXIS = 2
# 的士数量
DEFAULT_END_TIME = 180
# 默认结束时间
SEARCH_DURATION = 5
# 四处走动的找客户时间长度。
TRIP_DURATION = 20
# 长度 时间间隔 平局值 会传入到 compute 里面计算
DEPARTURE_INTERVAL = 5
# 每辆车从车库离开的间隔时间
Event = collections.namedtuple('Event', 'time proc action')
# time 字段是事件发生时的仿真时间,
# proc 字段是出租车进程实例的编号,
# action 字段是描述活动的字符串。
# 开始出租车进程
def taxi_process(ident, trips, start_time=0):
# 每辆出租车调用一次taxi_process函数,创建一个生成器对象,表示各辆出租车的运营过程。
"""
每次改变状态时创建事件。把控制全交给仿真器
:ident: ident是出租车的编号(如 0、1、2);
:trips: trips是出租车回家之前的行程数量;
:start_time: start_time是出租车离开车库的时间。
"""
time = yield Event(start_time, ident, 'leave garage')
sleep(time / 1000) # 这就是我用来测试的时间
# 产出的第一个Event是'leave garage'。
# 执行到这一行时,协程会暂停,让仿真主循环着手处理排定的下一个事件。
# 需要重新激活这个进程时,主循环会发送(使用send方法)当前的仿真时间,赋值给time。
for i in range(trips): # 每次行程都会执行一遍这个代码块。
time = yield Event(time, ident, 'pick up passenger')
sleep(time / 1000)
# 产出一个Event实例,表示拉到乘客了。
# 协程在这里暂停。需要重新激活这个协程时,主循环会发送(使用send方法)当前的时间。
time = yield Event(time, ident, 'drop off passenger')
sleep(time / 1000)
# 产出一个Event实例,表示乘客下车了。协程在这里暂停,等待主循环发送时间,然后重新激活。
yield Event(time, ident, 'going home')
# 协程执行到最后时,生成器对象抛出StopIteration异常。
# end of taxi process # <7>
# 出租车进程结束
# 开始出租车仿真
class Simulator:
def __init__(self, procs_map):
self.events = queue.PriorityQueue()
# 保存排定事件的 PriorityQueue对象,按时间正向排序。
# 优先队列
self.procs = dict(procs_map)
# 获取的procs_map参数是一个字典(或其他映射),可是又从中构建一个字典,创建本地副本,
# 因为在仿真过程中,出租车回家后会从self.procs属性中移除,而我们不想修改用户传入的对象。
# 仿真 run 方法
def run(self, end_time): # run方法只需要仿真结束时间(end_time)这一个参数
"""安排和显示事件,直到时间到了"""
# 为每个人安排第一个活动
for _, proc in sorted(self.procs.items()):
# run方法只需要仿真结束时间(end_time)这一个参数
first_event = next(proc)
# 调用next(proc)预激各个协程,向前执行到第一个yield表达式,做好接收数据的准备。
# 产出一个Event对象。
self.events.put(first_event)
# 把各个事件添加到self.events属性表示的PriorityQueue对象中。
# 各辆出租车的第一个事件是'leave garage'。
# 仿真主循环
sim_time = 0 # 把sim_time变量(仿真钟)归零。
while sim_time < end_time:
# 这个仿真系统的主循环:sim_time小于end_time时运行。
if self.events.empty(): # 如果队列中没有未完成的事件,退出主循环
print('*** 事件结束 ***')
break
current_event = self.events.get()
# 获取优先队列中time属性最小的Event对象;这是当前事件(current_event)。
sim_time, proc_id, previous_action = current_event
# 拆包Event对象中的数据。
# 这一行代码会更新仿真钟sim_time,对应于事件发生时的时间。
print('taxi:', proc_id, proc_id * ' ', current_event)
# 显示Event对象,指明是哪辆出租车,并根据出租车的编号缩进
active_proc = self.procs[proc_id]
# 从self.procs字典中获取表示当前活动的出租车的协程。
next_time = sim_time + compute_duration(previous_action)
# 调用compute_duration(...)函数,传入前一个动作(例如,'pick up passenger'、'drop off passenger'等),
# 把结果加到sim_time上,计算出下一次活动的时间。(即 下一个事件的开始时间。)
# 这里是 send 到 taxi_process 中的某一个 yield 处。
try:
next_event = active_proc.send(next_time)
# 把计算得到的时间发给出租车协程。协程会产出下一个事件(next_event),
# 或者抛出StopIteration异常(完成时)。
except StopIteration:
del self.procs[proc_id]
# 如果抛出了StopIteration异常,从self.procs字典中删除那个协程。
else:
self.events.put(next_event)
# 否则,把next_event放入队列中。
else: # 如果循环由于仿真时间到了而退出,显示待完成的事件数量(有时可能碰巧是零)
msg = '*** end of simulation time: {} 待处理事件 ***'
print(msg.format(self.events.qsize()))
# 结束出租车仿真
def compute_duration(previous_action):
"""使用指数分布计算动作持续时间"""
if previous_action in ['leave garage', 'drop off passenger']:
# pre 指的是上一个动作
# new state is prowling
# 新状态四处走动
# leave garage 离开车库
# drop off passenger 下客
interval = SEARCH_DURATION
elif previous_action == 'pick up passenger':
# new state is trip
# 新的状态是 trip 行程
# pick up passenger 拉到乘客了
interval = TRIP_DURATION # 时间 间隔
elif previous_action == 'going home':
# going home 回家
interval = 1
else:
# 未知动作 抛出异常
raise ValueError('Unknown previous_action: %s' % previous_action)
return int(random.expovariate(1 / interval)) + 1
# 根据 interval 计算一个随机值。
# random.expovariate(lambd) 指数分布。 参数 兰伯德(lambd) 是1.0除以期望的平均值(在这里是 interval)。它应该是非零的。
# https://baike.baidu.com/item/%E6%8C%87%E6%95%B0%E5%88%86%E5%B8%83/776702?fr=aladdin
# 这是指数分布的百科
# 指数函数的一个重要特征是无记忆性(Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数分布,当s,t>0时有P(T>t+s|T>t)=P(T>s)。即,如果T是某一元件的寿命,已知元件使用了t小时,它总共使用至少s+t小时的条件概率,与从开始使用时算起它使用至少s小时的概率相等。
# 我们只需要知道这是一个用来 得到无记忆 随机数的函数就可以了。
# 本节重点 是 taxe_process 和 run
# 主要理解这两个 。 其他相对来说都是无关紧要的。
def main(end_time=DEFAULT_END_TIME,
num_taxis=DEFAULT_NUMBER_OF_TAXIS,
seed=None):
"""初始化随机生成器,构建过程并运行仿真"""
if seed is not None:
random.seed(seed) # 获得可重复的结果
taxis = {
i: taxi_process(i, (i + 1) * 2, i * DEPARTURE_INTERVAL)
for i in range(num_taxis)
}
sim = Simulator(taxis)
s = t()
sim.run(end_time)
print(t() - s)
# 命令行支持 python3 taxi_sim.py -s 3 -e 120 支持如此调用。
# 以下 暂时不用看。这里主要还是以 理解如何在单个线程中管理多个并发活动的。
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Taxi fleet simulator.')
# 出租车队模拟器
parser.add_argument('-e',
'--end-time',
type=int,
default=DEFAULT_END_TIME,
help='simulation end time; default = %s' %
DEFAULT_END_TIME)
parser.add_argument('-t',
'--taxis',
type=int,
default=DEFAULT_NUMBER_OF_TAXIS,
help='number of taxis running; default = %s' %
DEFAULT_NUMBER_OF_TAXIS)
parser.add_argument('-s',
'--seed',
type=int,
default=None,
help='random generator seed (for testing)')
# 随机生成器种子(用于测试)
args = parser.parse_args()
main(args.end_time, args.taxis, args.seed)
这个示例的要旨是说明如何在一个主循环中处理事件,以及如何通过发送数据驱动协程。这是asyncio包底层的基本思想
运行效果
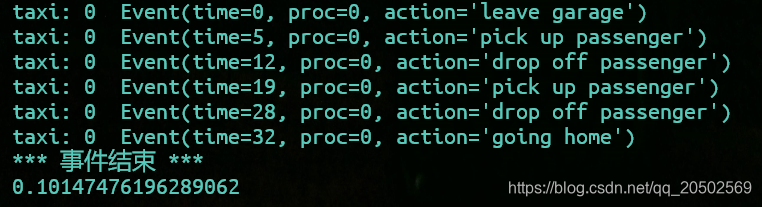
1 辆车
0.1014 * 1000 和 time+ 起来是基本一致的
2 辆车
序号 0 taxi:
序号 1 taxi:
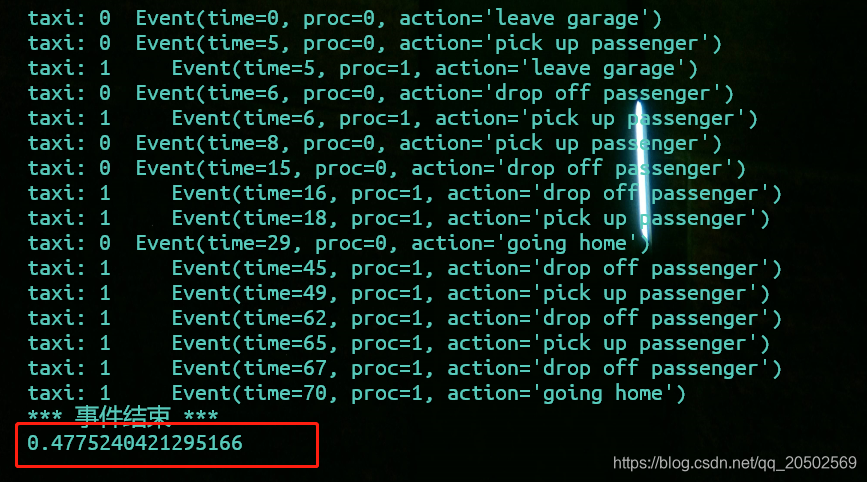
计算这个时间 就是我愚蠢的地方。
爬虫爬取表情包 yield 练习
斗图吧这个网站一页是 68张图片。
普通的依序下载
import os
import re
import string
import requests
from lxml import etree
import time
# from concurrent import futures
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)',
'Referer': 'http://www.doutula.com/'
}
PAT = string.punctuation
SAVEPATH = "".join([".", os.sep, "img"])
page_url_template = 'http://www.doutula.com/photo/list/?page={}'
get = requests.get
def gen_html_obj(url):
try:
r = get(url, headers=HEADERS, timeout=30)
r.raise_for_status() # 如果状态不是200 引发 异常
r.encoding = "utf-8" # 设置编码
html = etree.HTML(r.text)
return html
except BaseException as exc:
print(exc)
def save_(img_url, filename):
res = get(img_url, headers=HEADERS).content
save_name = "".join([SAVEPATH, os.sep, filename])
try:
with open(save_name, "wb") as f:
f.write(res)
except FileNotFoundError:
os.mkdir(SAVEPATH)
with open(save_name, "wb") as f:
f.write(res)
# print(img_url)
def handle_img_node(img):
"""
从图片节点提取属性
构造文件名字,以及获取图片url
"""
img_url = img.get('data-original')
# 用get方法获取data-original属性 的值 ,也就是下载链接
alt = img.get('alt')
alt = re.sub(fr'[{PAT}]', '', alt) # 把特殊字符给替换掉
suffix = os.path.splitext(img_url)[1] # 提取后缀
filename = alt + suffix # 组合图片名字
return img_url, filename
def handle_html(html):
# 获取 下面class 不等于 gif 的图片
if html is not None:
imgs = html.xpath(
"//div[@class='page-content text-center']//img[@class!='gif']")
for img in imgs: # data-original
img_url, filename = handle_img_node(img)
save_(img_url, filename) # 调用 save_ 发送请求 并保存图片
def download_one(x):
url = page_url_template.format(x)
html = gen_html_obj(url)
handle_html(html)
def main(func, num):
start = time.time()
for x in range(1, num+1):
download_one(x)
print("耗时 -> ", time.time()-start, "秒")
if __name__ == "__main__":
main(download_one, 1) # 下载一页的表情包
以下 是使用 threading 写的简单的多线程(异步的)_
这是简化版的 多线程,就当是复习了。
完整的其实在之前的 多线程并发编程部分就已经 写过了。(生产者消费者+队列)
忘记了的可以回过头去看一下。
关于爬虫的 requests 包 的使用 , 可以看下我在 文章开始部分贴出来的文档链接。
import os
import re
import string
import requests
from lxml import etree
import time
# from concurrent import futures
import threading
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)',
'Referer': 'http://www.doutula.com/'
}
PAT = string.punctuation
SAVEPATH = "".join([".", os.sep, "img"])
page_url_template = 'http://www.doutula.com/photo/list/?page={}'
get = requests.get
def gen_html_obj(url):
try:
r = get(url, headers=HEADERS, timeout=30)
r.raise_for_status() # 如果状态不是200 引发 异常
r.encoding = "utf-8" # 设置编码
html = etree.HTML(r.text)
return html
except BaseException as exc:
print(exc)
def save_(img_url, filename):
res = get(img_url, headers=HEADERS).content
save_name = "".join([SAVEPATH, os.sep, filename])
try:
with open(save_name, "wb") as f:
f.write(res)
except FileNotFoundError:
os.mkdir(SAVEPATH)
with open(save_name, "wb") as f:
f.write(res)
# print(img_url)
def handle_img_node(img):
"""
从图片节点提取属性
构造文件名字,以及获取图片url
"""
img_url = img.get('data-original')
# 用get方法获取data-original属性 的值 ,也就是下载链接
alt = img.get('alt')
alt = re.sub(fr'[{PAT}]', '', alt) # 把特殊字符给替换掉
suffix = os.path.splitext(img_url)[1] # 提取后缀
filename = alt + suffix # 组合图片名字
return img_url, filename
def handle_html(html):
# 获取 下面class 不等于 gif 的图片
if html is not None:
imgs = html.xpath(
"//div[@class='page-content text-center']//img[@class!='gif']")
for img in imgs: # data-original
img_url, filename = handle_img_node(img)
t = threading.Thread(target=save_, args=(img_url, filename))
# 这里线程开启我们并没有限制数量
# 也就是说 ,一页里面有多少个 图片我们就开启多少个线程。
# 所以一般来说我们都是配合队列来进行操作的。
# 这样可以设定 线程数量来运行。
# 还有更好的方式是 使用 Future
# 这个后面我会将fluntpython 这本书的例子贴出来
# 以及用书上的方式改写这个脚本。
t.start()
# save_(img_url, filename) # 调用 save_ 发送请求 并保存图片
def download_one(x):
url = page_url_template.format(x)
html = gen_html_obj(url)
handle_html(html)
def main(func, num):
start_time = time.time()
for x in range(1, num+1):
# 这样我们就对 下载页数的进行了多线程
# 类似于几页同时下载
# 但是单个图片在内部还是 一张一张下载的。
# 其实更好的思路 是 对request.get 下载单张图片所在的函数 进行封装。 开启多线程。
# 也就是 for img in imgs 下面的步骤进行封装为单个函数
# 然后用多线程来 运行 循环里面的结构。
locals()[f't{x}'] = threading.Thread(target=download_one, args=(x,))
locals()[f't{x}'].start()
# download_one(x)
for x in range(1, num+1):
locals()[f't{x}'].join()
print("耗时 -> ", time.time()-start_time, "秒")
if __name__ == "__main__":
main(download_one, 2) # 下载两页的表情包
测试 下载两页 普通爬虫 用时 21 秒 。(下载10页 耗时 122秒) 但是多线程 只用 30 多秒就下载 完成了。
这个代码的目的是 为了 体现 协程 如何切换任务 (也就是说如何 实现并发)
以及 yield from 和 yiled 的一些用法。
但是我们要知道这是阻塞的 。前面仿真那一节,我测试之后发现,单纯的 yield 无法实现 非阻塞的异步下载。(原因自己去看一下 协程缺点)
因为request 是阻塞型io
所以如果我们将 request 换为 aiohttp.request 是不是就可以异步下载了呢?
或者是 httpx 的 异步请求。
往后面继续看吧。
所以下面的代码是 学习思路,但是下载效率还是和原来的依序下载差不多的。
import os
import re
import string
import time
from collections import deque, namedtuple
from lxml import etree
import requests
# from requests import Session
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)',
'Referer': 'http://www.doutula.com/'
}
PAT = string.punctuation
RESULT = namedtuple("Result", "img_url filepath")
SAVEPATH = "".join([".", os.sep, "img"])
page_url_template = 'http://www.doutula.com/photo/list/?page={}'
get = requests.get
def gen_html(depth):
def get_html(url):
try:
r = get(url, headers=HEADERS, timeout=30)
r.raise_for_status() # 如果状态不是200 引发 异常
r.encoding = "utf-8" # 设置编码
html = etree.HTML(r.text)
return html
except BaseException as exc:
print(exc)
for x in range(1, depth + 1):
html = get_html(page_url_template.format(x))
yield html
def handle_img_node(img):
"""
从图片节点提取属性
构造文件名字,以及获取图片url
"""
img_url = img.get('data-original')
# 用get方法获取data-original属性 的值 ,也就是下载链接
alt = img.get('alt')
alt = re.sub(fr'[{PAT}]', '', alt) # 把特殊字符给替换掉
suffix = os.path.splitext(img_url)[1] # 提取后缀
filename = alt + suffix # 组合图片名字
return img_url, filename
def parse_page(html):
imgs = html.xpath("//div[@class='page-content text-center']//img[@class!='gif']")
for img in imgs: # data-original
img_url, filepath = handle_img_node(img)
# 组合图片保存路径
yield RESULT(img_url, filepath)
def save_():
def get_(url):
return get(url, headers=HEADERS).content
# 主要是为了使用 yield from 的时候 让其 将控制权 交给 最外层的 调用方。
# 之所以 这么多 yield from 是为了 将控制权 放出来。
while True:
result = yield
# print("请求发送时间 ", time.ctime())
res = get_(result.img_url)
path_ = "".join([SAVEPATH, os.sep, result.filepath])
try:
with open(path_, "wb") as f:
f.write(res)
except FileNotFoundError:
os.mkdir(SAVEPATH)
with open(path_, "wb") as f:
f.write(res)
# 委派生成器 带有 yield from 的函数
def grouper():
def html():
yield from gen_html(1) # 下载多少页 在这里设置 2 就是 2 页
for html_ele in html():
yield from parse_page(html_ele)
# 调用子生成器 gen 后,在yield from表达式处暂停
class TaskScheduler:
# 一个简单任务调度器
def __init__(self, g):
self._task_queue = deque()
self.g = g
def new_task(self, task):
'''
添加一个新的已开始的任务到调度器
'''
print(task)
next(task)
self._task_queue.append(task)
def run(self):
'''
运行到没有更多的任务
'''
task_append = self._task_queue.append
while self._task_queue:
task = self._task_queue.popleft()
try:
# 运行到下一个 yield 语句
task.send(next(self.g))
task_append(task)
except StopIteration:
# 生成器没有内容了
break
print("任务结束")
def main():
start = time.time()
sched = TaskScheduler(grouper())
# grouper 用于生成 img_url
for i in range(5): # 新建多少个任务
sched.new_task(save_())
# save_ 任务用于 发送图片img_url 进行保存
sched.run()
# 下载多少页 在 grouper 函数中设置
# 下面这个 方式也是 可以的。
# g = grouper()
# task = [save_() for i in range(4)] # 创建 几个 图片下载的协程任务
# try:
# for save in task:
# next(save)
# while True:
# for save in task: # 循环 的send 因为 请求发送有延迟 所以 发送请求之后不等他返回 响应 , 就继续发送 下一个请求。
# save.send(next(g)) # 将 Result 对象 发送给 save 协程处理
# except StopIteration:
# print("下载完毕")
pay_time = time.time() - start
print(' 耗时 -> %d' % pay_time)
if __name__ == "__main__":
main()
下一节会写 future 的方式调用 多线程(实现真正非阻塞异步的下载方式)


















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









