





背景
对象检测和实例分割是迄今为止计算机视觉中最重要的应用程序。
然而,在实际使用中,小物体的检测和大图像的推理仍然需要改进。
SAHI(Slicing Aided Hyper Inference)应运而生,它通过许多视觉实用程序帮助开发人员克服这些实际问题。
简介
-
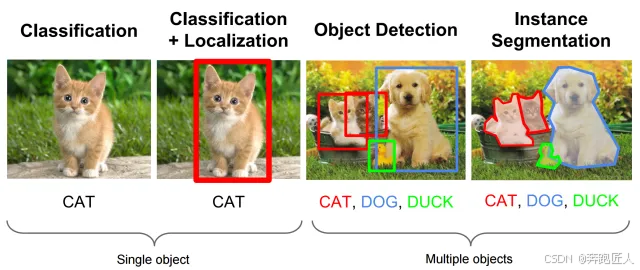
对象检测:对象检测是指识别并正确标记图像帧中存在的所有对象的方法。
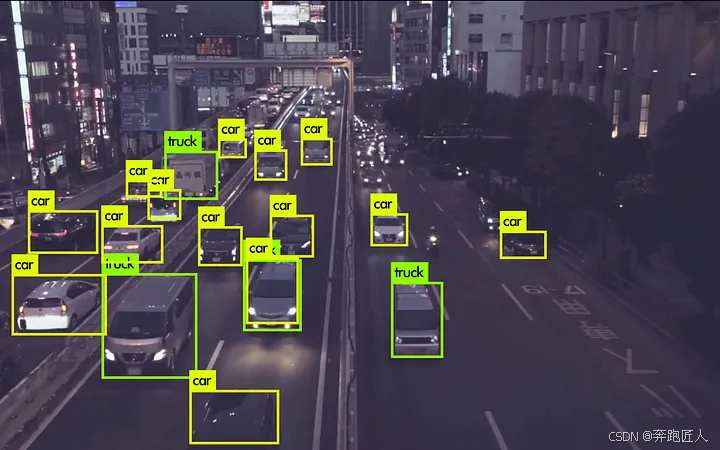
这大致包括两个步骤:1:对象定位 :在这里,以最紧密的方式确定边界框或封闭区域,以便定位对象在图像中的确切位置。
2:图像分类:然后将本地化对象馈送到标记对象的分类器。
-
语义分割:是指将给定图像中的每个像素链接到特定类标签的过程。例如,在下图中,像素被标记为汽车、树木、行人等。然后使用这些 segments 来查找各种对象之间的交互/关系。

-
实例分割:在这里,我们将一个类标签关联到每个像素,类似于语义分割,不同之处在于它将同一类的多个对象视为单个对象/单独的实体。

安装 SAHI

您可以通过 pip 安装最新版本:
pip install -U sahi
然后安装您想要的 pytorch 和 torchvision 版本:
pip install torch torchvision
最后,安装所需的检测框架(例如 mmdet):
pip install mmdet mmcv-full
就是这样,现在您可以在 Python 中导入和使用任何 SAHI 函数:
from sahi import get_sliced_prediction
使用 SAHI 进行切片推理

切片推理的概念 基本上是对原始图像的较小切片执行推理,然后合并原始图像上的切片预测。可以在下面说明:

通过执行切片推理而不是标准推理,可以更准确地检测较小的对象。*

在这里,我们将展示使用 SAHI 对此示例图像进行切片推理演示:

- 首先导入本教程所需的函数:
from sahi import AutoDetectionModel
from sahi.predict import get_sliced_prediction
from sahi.utils.cv import read_image_as_pil
AutoDetectionModel 是支持常用检测框架的工厂类。它可用于对任何 MMDetection 模型加载和执行切片/标准推理。
get_sliced_prediction 是执行切片推理的函数。
- 然后,我们需要通过定义所需的参数来创建一个 DetectionModel 实例:
detection_model = AutoDetectionModel.from_pretrained(
model_type='mmdet',
model_path=mmdet_cascade_mask_rcnn_model_path,
config_path=mmdet_cascade_mask_rcnn_config_path,
confidence_threshold=0.4,
device="cuda:0"
)
model_type可以是 ‘yolov5’、‘mmdet’、‘huggingface’、‘torchvision’、‘detectron2’,具体取决于你的权重文件。
需要 model_path 和 config_path 才能成功加载任何模型。
分数低于 confidence_threshold 的预测将在结果中被忽略。
device 参数指定推理设备,可设置为 cuda:0 或 cpu。
- 阅读图片:
image = read_image_as_pil(image_dir)
- 最后,我们可以执行切片预测。在此示例中,我们将对重叠率为 0.2 的 256x256 切片执行预测:
result = get_sliced_prediction(
image,
detection_model,
slice_height = 256,
slice_width = 256,
overlap_height_ratio = 0.2,
overlap_width_ratio = 0.2
)
- 在原始图像上可视化预测的边界框和掩码:
result.export_visuals(export_dir="result/")
Image("result/prediction_visual.png")
您可以在 mmdetection colab notebook 或 yolov5 colab notebook 上查看完整详细信息。
使用 SAHI 进行图像和数据集切片
您可以独立使用 SAHI 的切片操作。
例如,您可以将单个图像切片为:
from sahi.slicing import slice_image
slice_image_result, num_total_invalid_segmentation = slice_image(
image=image_path,
output_file_name=output_file_name,
output_dir=output_dir,
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
或者,您可以从任何 coco 格式的数据集创建切片 coco 数据集,如下所示:
from sahi.slicing import slice_coco
coco_dict, coco_path = slice_coco(
coco_annotation_file_path=coco_annotation_file_path,
image_dir=image_dir,
slice_height=256,
slice_width=256,
overlap_height_ratio=0.2,
overlap_width_ratio=0.2,
)
使用 SAHI 的命令行界面

✔️ 使用权重路径对 YOLOv5 模型执行推理:
sahi predict --source image_dir/ --model_type yolov5 --model_path yolov5s.pt --slice_height 512 --slice_width 512
✔️ 使用您的权重路径和配置路径对 MMDetection 和 Detectron2 模型执行推理:
sahi predict --source image_dir/ --model_type detectron2 --model_path weight.pt --config_path config.yaml --slice_height 512 --slice_width 512
误差分析图/指标
✔️ 使用 COCO 格式数据集创建 COCO 格式预测结果:

sahi predict --source image_dir/ --dataset_json_path dataset.json --model_type yolov5 --model_path weight.pt --no_sliced_prediction
✔️ 使用创建的 result.json 创建误差分析图解:

sahi coco analyse --dataset_json_path dataset.json --result_json_path result.json
🎯 指标的含义:
C75:0.75 IOU 阈值
C50 的结果:0.75 IOU 阈值
的结果 位置:忽略定位错误 后的结果 Sim:忽略超类别误报
后的结果 其他:忽略所有类别混淆
后的结果 BG:忽略所有误报
后的结果 FN:忽略所有假阴性
后的结果
📈 可能的模型改进:
C75-C50 和 C50-Loc=边界框预测
更准确的潜在增益 Loc-Sim=修复超类别混淆
后的潜在增益 Loc-Oth=修复类别混淆
后的潜在增益 Oth-BG=修复所有假阳性
后的潜在增益 BG-FN=修复所有假阴性后的潜在增益
交互式可视化
✔️ 安装 fiftyone:
pip install -U fiftyone
✔️ 使用您的预测结果启动 51 个 Web 应用程序:

sahi coco fiftyone --dataset_json_path dataset.json --image_dir image_dir/ result.json
使用 SAHI 向新的检测框架添加支持
SAHI 库目前支持 YOLOv5、所有 MMDetection 模型、HuggingFace 对象检测器和所有 Detectron2 模型。此外,添加新框架很容易。
您需要做的就是在 sahi/models/ 文件夹下创建一个新的 .py 文件,并在该 .py 文件中创建一个继承自 DetectionModel 类的类。你可以将 YOLOv5 包装器作为参考。
参考文献
https://medium.com/codable/sahi-a-vision-library-for-performing-sliced-inference-on-large-images-small-objects-c8b086af3b80
https://github.com/obss/sahi/blob/main/README.md

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









