






 本文详细介绍了Linux系统中常用的Shell命令,包括获取帮助、处理文件、字符串操作、流程控制、变量和函数等内容,并提供了示例。此外,还讲解了文本处理工具如grep、sed和awk的使用方法,以及如何编写简单的Shell脚本来自动化任务。
本文详细介绍了Linux系统中常用的Shell命令,包括获取帮助、处理文件、字符串操作、流程控制、变量和函数等内容,并提供了示例。此外,还讲解了文本处理工具如grep、sed和awk的使用方法,以及如何编写简单的Shell脚本来自动化任务。
常用命令
获取命令解析
# 以head命令做例子
head -help
man head
两个命令分别执行
echo "$name"; echo "$school"获取当前系统版本
cat /etc/os-release获取当前系统内核数量
cat /proc/cpuinfo | grep -c name&>
将输出内容扔到回收站,则不会打印ping的结果。
ping -c1 www.ba.com &> /dev/null; echo $? head
默认获取文件前十行
head test.txt获取指定前*行数内容
# 获取前两行
head -2 test.txt
head -n2 test.txt
head --line=2 test.txt
tail
默认获取文件后十行
tail test.txt获取指定后*行数内容
# 获取后两行
tail -2 test.txt
tail -n2 test.txt
动态展示
tail -f test.txt
head和tail结合打印中间
| 管道符会将前面的结果当做后面的筛选目标
#先将前五行筛选出来,再从前五行的结果筛选出后两行,得到3行4行5行的数据
head -5 test.txt | tail -3
cut
取出指定文本列,默认以空格或tab进行分割
# 获取第一列内容
cut -f1 test.txt
# 获取第一列,第二列内容
cut -f1,2 test.txt
cut -f1-2 test.txt
# 两种组合获取124列
cut -f1-2,4 test.txt使用指定分隔符提取
# 获取:前第一列内容
cut -d:":" -f1 test.txt
sort
对文本内容进行排序,默认以字符的ASCII码数值从小到大排序
# 第一列的第一个字符数值排序
sort test.txt
按照字符数字大小排序
sort -n test.txt
用某种符号切成多块区域,将某列按照数字大小排序
sort -t":" -k3 -n test.txt
uniq
去重 ,先有顺序才能够去重
sort -t":" -k3 -n test.txt | uniq
wc
计算文本数量
打印行数
wc -l test.txt打印单词数
wc -w test.txtecho
-e识别换行符
echo -e "$name \n111"上一条命令的结果
echo $?sudo
进入root用户
sudo -i变量
定义变量
# 下方定义的都是本地变量
name=yue
# 看到什么,输出什么
name='yue'
# 调用变量时使用双引号
name_list="$name lixiaoming"
# 脚本中调用变量
name_list="${name} lixiaoming"
# 将linux命令结果赋值给变量$()
time=$(date)
echo $time
# 将linux命令结果赋值给变量``键盘esc下边那个
time=`date`
echo $time全局变量(跨控制台则无法调用)
本地变量转换为全局变量
export $name创建全局变量
export name查看变量
echo $name
echo “$name”数值运算
支持
+ - * / %
> = < >= <= !=
a=1
b=2
# 第一种
echo $((a+b))
echo $(($a+$b))
# 第二种
result=`expr $a + $b`条件表达式
返回值
- 条件成立,返回0
- 条件不成立,返回1
文件表达式
一般后面会接 ;echo $? 输出结果
# 判断是否是文件
test -f test.txt
# 判断是否是目录
test -d test.txt
# 判断是否可执行
test -x test.txt
# 判断是否存在
test -e test.txt数值操作符
一般后面会接 ;echo $? 输出结果
a=1
b=2
# 判断数值是否相等
test $a -eq $b
# 判断数值是否大于
test $a -gt $b
# 判断数值是否小于
test $a -lt $b
# 判断数值是否不等于
test $a -ne $b
# 还有另一种写法
[ $a -ne $b ]字符串比较
a=你好
b=你不能好
# 判断字符串是否相等
test $a == $b
# 判断字符串是否不等于
test $a != $b
与或非&& ||
a=1
b=2
test $a -ne $b && echo "不等于判断成功" || echo "或关系执行成功"
shell脚本
格式要求

demo
#!/bin/bash
# Author: xxx <xxx@qq.com>
# Date: xxxx-xxxx-xx
# Description: 这个一个演示程序
# xxxx这里是单行注释
:<<!
这里写多行注释
!
echo 520
执行shell脚本
bash demo.sh
sh demo.sh
source demo.sh
# 加-x能打印日志
bash -x demo.sh
脚本中提示用户输入
默认赋值给REPLY变量
# -e会有正确提示
read -e -p "请输入主机名称:"
echo $REPLY赋值给指定变量host_name
read -p "请输入主机名称:" host_name
echo $host_name-n*可输入*个字符
read -n1 -p "请输入Y/N:" result
$echo result加密输入
read -s -n1 -p "请输入Y/N:" result
$echo result函数
定义:第一种写法
# 定义get_name函数
function get_name
{
四个空格/tab键的位置后,输入命令
}
# 调用get_name函数
get_name
定义:第二种写法
# 定义get_name函数
get_name()
{
四个空格/tab键的位置后,输入命令
}
# 调用get_name函数
get_name入参
1-9位置的参数可用$1$2$3.....,10位置开始就要用${10}
function get_host
{
host="$1"
echo "$1","网址百度在线${host}"
}
get_host www.baidu.com 前面是第一个入参,这是第二个入参 第三个入参 第四个入参命令行入参
{
host="$1"
echo "$1","网址百度在线${host}"
}
get_host $1
# 命令行输入get_host www.baidu.com流程控制
if
# 方式一
if [ 条件1 ]
then
若条件1符合,执行此处
elif [ 条件2 ]
then
若条件2符合,执行此处
else
若条件12均不符合,执行此处
# fi是if闭合,参考前端代码
fi
# 方式二
if [ 条件1 ];then
若条件1符合,执行此处
elif [ 条件2 ];then
若条件2符合,执行此处
else
若条件12均不符合,执行此处
# fi是if闭合,参考前端代码
fi
demo:基础判断
read -e -p "请输入路径(如:/etc/passwd):"
if [ -f "${REPLY}" ]; then
echo "${REPLY}是常规文件"
elif [ -d "${REPLY}" ]; then
echo "${REPLY}是目录"
else
echo "${REPLY}是其他文件"
fidemo:常用端口判断
if netstat -tlunp | grep ":3306" &>/dev/null; then
echo "mysql已启动"
else
echo "mysql未启动"
fifor
# 格式1
for 值 in 列表
do
执行语句
done
# 格式1优化
for 值 in 列表; do
执行语句
done
# 举例
arr=(1 2 3)
for i in "${arr[@]}"; do
echo ${i}
done
# 格式2
max=10
for ((i=1;i<=10;i++))
do
echo "$i"
done
# 格式2优化
max=10
for ((i=1;i<=10;i++)); do
echo "$i"
donedemo
dir=$(ls /)
index=1
for f in $dir; do
echo "${index}.${f}"
index=$((index+1))
donewhile
只要条件满足,则一直循环
# 格式
while 条件
do
执行语句
done
# 格式优化
while 条件; do
执行语句
done
demo
while使用本地文件进行判断
# 每次循环将值赋予hostname和ip
while read hostname ip; do
ping -c1 -W1 "$ip" &> /dev/null
if [ $? -eq 0 ]; then
echo "主机【${hostname}】在线"
else
echo "主机【${hostname}】离线"
fi
# 本地文件写在done后方,通过小于号重定向
done < ~/servers.txt
until
只要条件不满足,则一直循环
# 格式
while 条件
do
执行语句
done
# 格式优化
while 条件; do
执行语句
done
case
是判断等于的关系,菜单需求比较常用,输入什么进入什么
case 变量名 in
值1)
指令1
;;
值2)
指令2
;;
值3)
指令3
;;
*)
其他指令
;;
esacdemo
#!/bin/bash
function menu
{
echo -e "\t\txxx管理系统"
echo
echo -e "\t\t1.备份"
echo -e "\t\t2.显示"
echo -e "\t\t3.重启"
echo -e "\t\t4.还原"
echo -e "\t\t0.退出"
}
function main
{
while true; do
clear
menu
read -s -e -n1
echo
case "$REPLY" in
"1")
echo "执行备份操作"
;;
"2")
echo "执行显示操作"
;;
"3")
echo "执行重启操作"
;;
"4")
echo "执行还原操作"
;;
"0")
echo "执行退出操作"
break
;;
*)
echo "其他操作操作"
;;
esac
read
done
}
main
文本处理三剑客
grep
主要作用于“行过滤”
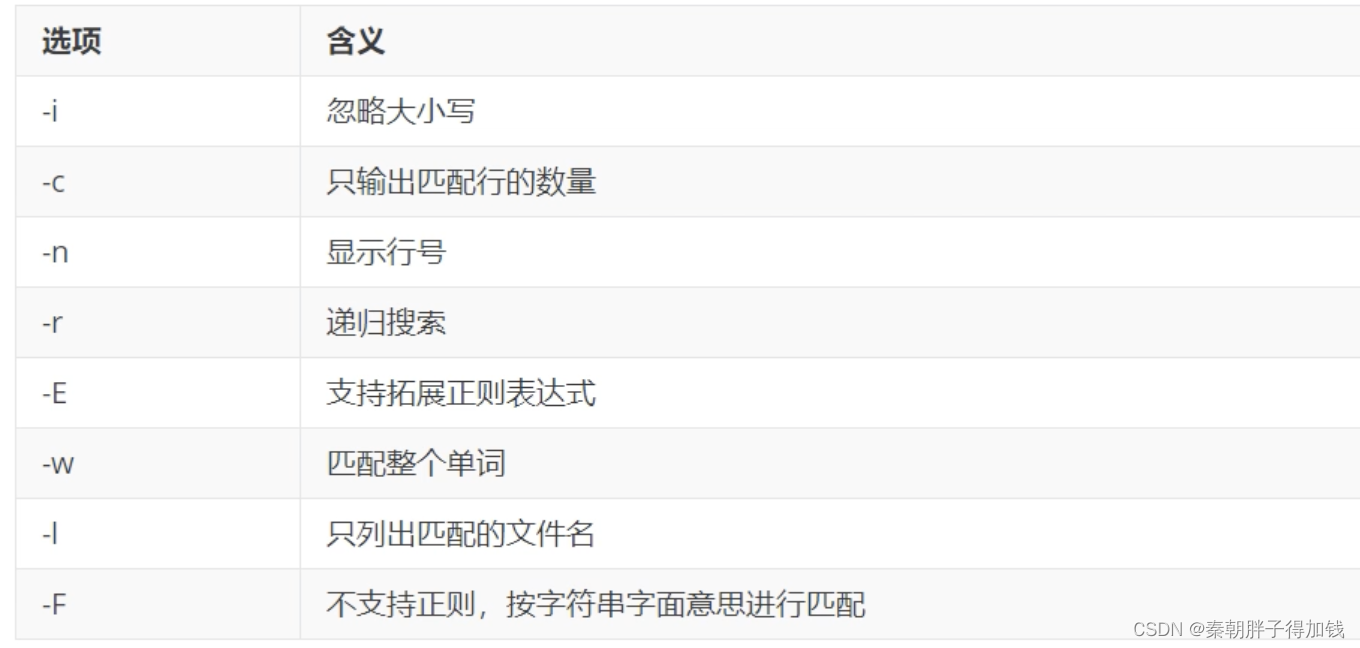
# 忽略大小写
grep -i "HJKkfd" text.txt
# 显示匹配到内容的行号
grep -n "HJKkfd" text.txt
# 显示匹配到内容的总行数
grep -c "HJKkfd" text.txt
# 显示”目录下“所有匹配的内容
grep -i -r "HJKkfd" ./
# 显示”目录下“所有匹配内容所在的文件
grep -i -r -l "HJKkfd" ./sed
可对文本进行增删改查
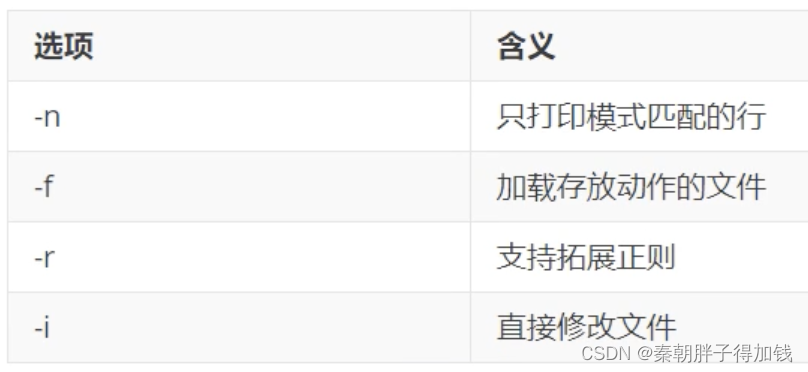
# p相当于print。下方打印会导致每行打印两遍
sed 'p' text.txt
# 加-n只打印匹配行
sed -n 'p' text.txt
# 匹配第一行
sed -n '1 p' text.txt
# 匹配1到5行
sed -n '1,5 p' text.txtawk
默认使用空格分隔
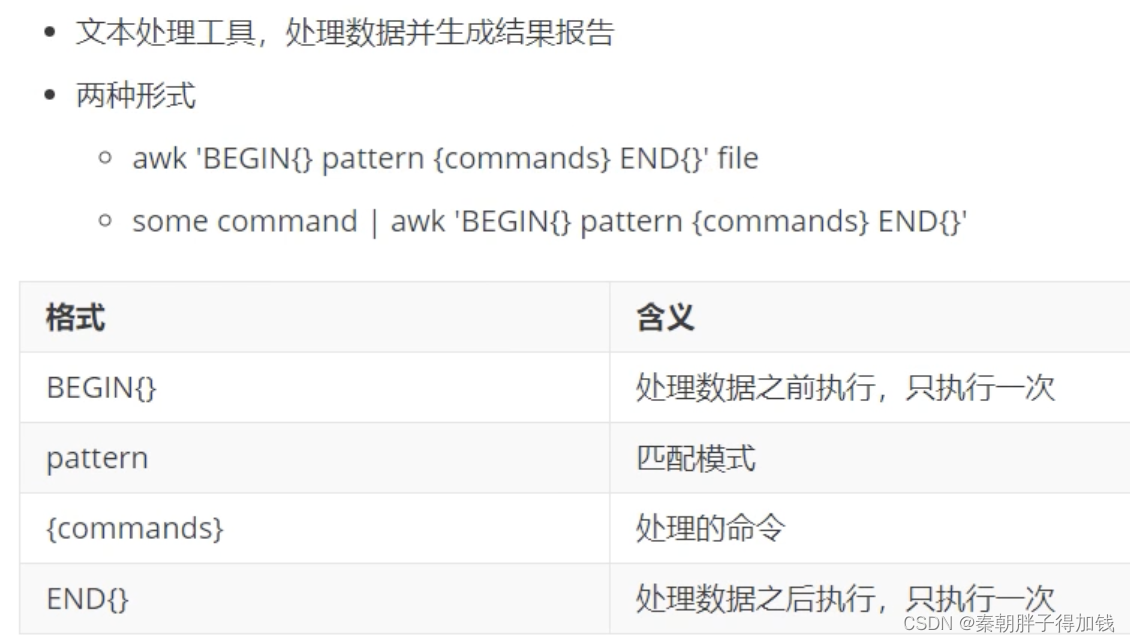
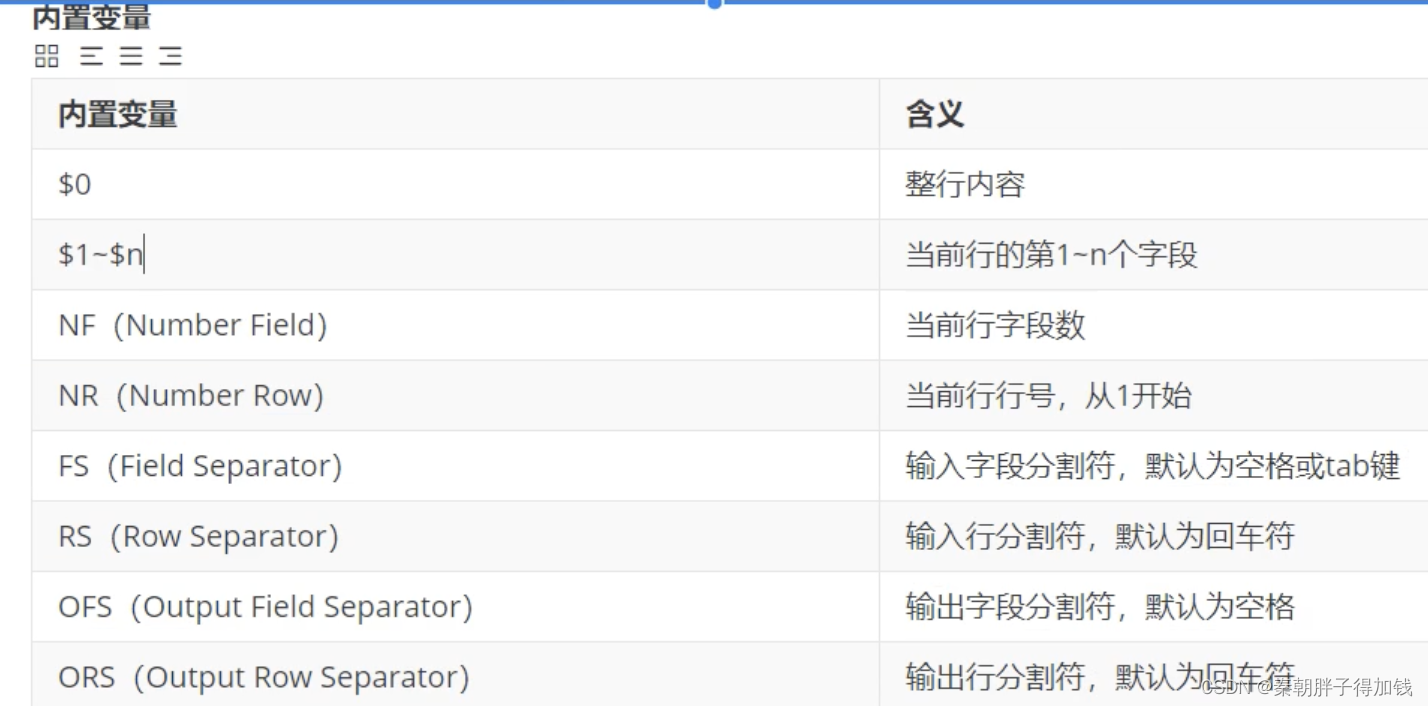
# 打印所有内容
awk '{print $0}' test.txt
# 打印第一列
awk '{print $1}' test.txt
# 打印每行的列数
awk '{print NF}' test.txt
# 打印每行最后一列
awk '{print $NF}' test.txt
# 打印每行倒数第二列
awk '{print $(NF-1)}' test.txt
# 以:分隔,打印第一列
awk -F":" '{print $1}' test.txt
awk 'BEGIN{FS=":"} {print $1}' test.txt
# 设置行分隔符,默认是回车
截图有
# 包含www的行中,取第三列
awk -F":" '/www/ {print $3}' test.txt
# www开头的行中,取第三列
awk -F":" '/^www/ {print $3}' test.txt
# www结尾的行中,取第三列
awk -F":" '/www$/ {print $3}' test.txt
# 取出固定范围的行的第几列
awk -F":" 'NR==3,NR==5 {print $1}' test.txt
# 取出1-10行的第一列和最后一列
awk -F":" 'NR==1,NR==2 {print $1,$NF}' test.txt
# 打印第三列小于100的行内容
awk -F":" '$3 <100 {print}' test.txt
# 打印第三列小于100的第一行和最后一行
awk -F":" '$3 <100 {print $1,$NF}' test.txt
# 打印第三列小于100的第一行和最后一行,字符串类型格式化
awk -F":" '$3 <100 {printf "%-20s%-21s\n" $1,$NF}' test.txt
# 打印第三列小于100的第一行和最后一行,字符串类型格式化,加表头
awk -F":" 'BEGIN{printf "%-20s%-21s\n" "表头一","表头二"} $3 <100 {printf "%-20s%-21s\n" $1,$NF}' test.txt
# 打印第三列小于100的第一行和最后一行,字符串类型格式化,加表头加表位
awk -F":" 'BEGIN{printf "%-20s%-21s\n" "表头一","表头二"} $3 <100 {printf "%-20s%-21s\n" $1,$NF; i++} END{printf "%-20s%-21s\n" "表尾Total",i}' test.txt
awk的流程控制语句
输出每个测试人员执行的用例数
 输出lemon执行的数量
输出lemon执行的数量
awk '/lemon/ {COUNT++} END{printf "%-10s%-10d\n", "lemon" COUNT}' testcases.log最总输出所有的
awk 'BEGIN{printf "%-10s%-10s\n, "Tester","Counts"} {USERS[$4]++} END{printf "%-10s%-10d\n", "lemon" COUNT}' testcases.logawk文件形式输出
执行awk文件命令
awk -f awk文件 处理的数据文件
awk -f test0.awk testcases.log
输出每个测试人员执行用例成功和失败的的总数
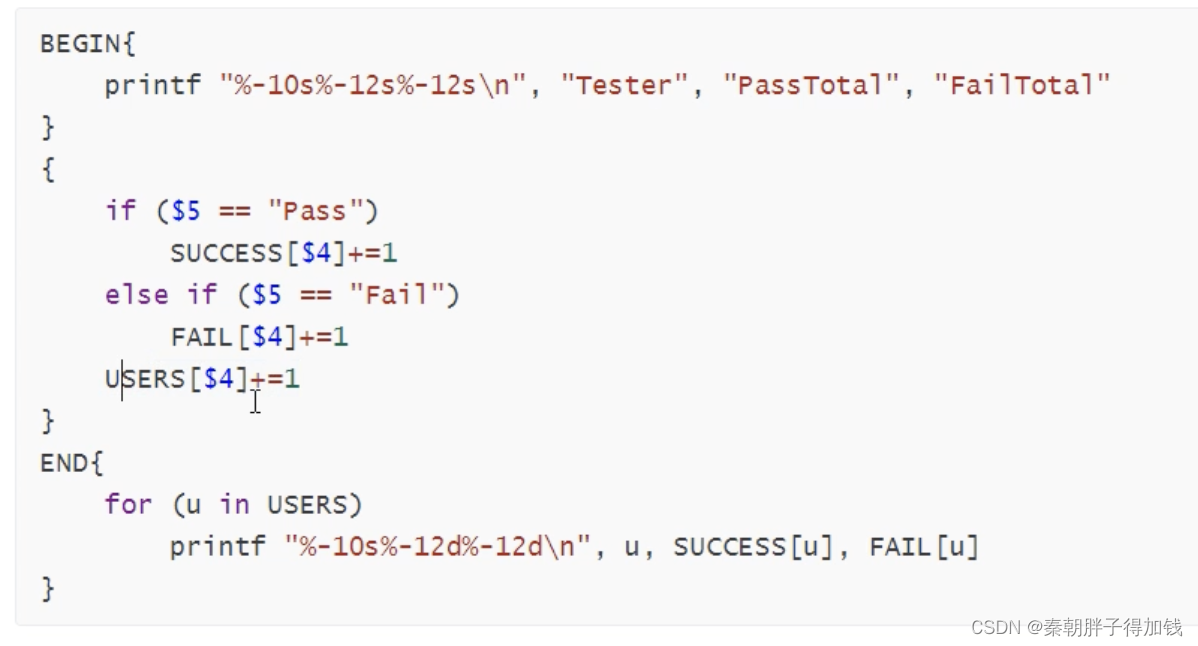
将上面两个合并,分别统计每位测试人员的执行用例CRITICAL、ERROR日志等级数以及所有所有测试人员每项总数

实战
备份指定文件
要求:
提示用户输入带备份的目录,需要备份的文件后缀,备份文件存放的目录。
将指定带备份目录下的文件(过滤出特定后缀的文件)赋值到备份文件存放的目录中
#!/bin/bash
# log file
LOG_FILE="/var/log/backup_file.log"
PROMPT_COLS=100
step_prompt() {
echo -n "[*] "${1}
echo -n "[*] "${1} >>${LOG_FILE}
}
step_fail() {
echo -en "\033[${PROMPT_COLS}G"
echo -e "\033[31m\t[FAILED]\033[0m"
echo -en "\033[${PROMPT_COLS}G" >>${LOG_FILE}
echo -e "\033[31m\t[FAILED]\033[0m" >>${LOG_FILE}
}
step_ok() {
echo -en "\033[${PROMPT_COLS}G"
echo -e "\033[32m\t[OK]\033[0m"
echo -en "\033[${PROMPT_COLS}G" >>${LOG_FILE}
echo -e "\033[32m\t[OK]\033[0m" >>${LOG_FILE}
}
main(){
read -e -p '请输入要备份的文件后缀(如:.sh)' file_suffix
read -e -p '请输入存放备份文件的路径(如:/root/backup)' dest_dir
read -e -n1 -p '请输入打包压缩的类型(L/M/H,L为tar, M为tar.gz, H为tar.bzip2)' file_compression
if [ ! -d ${dest_dir} ]; then
step_prompt "${dest_dir}目录不存在,创建目录"
mkdir -m 700 ${dest_dir} &> /dev/null && step_ok || step_fail
fi
step_prompt "查询待备份的文件并进行备份操作"
find ${HOME} -path ${dest_dir} -prune -o \
-name "*${file_suffix}" -exec cp -r {} ${dest_dir} \; &> /dev/null && step_ok || step_fail
if [ "${file_compression}" = "L" ]; then
tar_type="-cvf ${dest_dir}/backup.tar ${dest_dir}"
elif [ "${file_compression}" = "M" ]; then
tar_type="-czvf ${dest_dir}/backup.tar.gz ${dest_dir}"
else
tar_type="-cjvf ${dest_dir}/backup.tar.bzip2 ${dest_dir}"
fi
step_prompt "tar ${tar_type}"
tar ${tar_type} &> /dev/null && step_ok || step_fail
step_prompt "删除${dest_dir}目录中备份的所有*${file_suffix}文件"
rm -rf ${dest_dir}/*${file_suffix} &> /dev/null && step_ok || step_fail
echo -e "\n查询备份打包后的压缩文件:\n$(ls $dest_dir/)"
}
main

















 31万+
31万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











