









 本文详细解析了JDK1.7 ConcurrentHashMap的源码,包括其数据结构、初始化过程、put流程以及线程安全策略。ConcurrentHashMap采用分段 Segment 的设计,每个 Segment 类似一个小型 HashMap,内置 ReentrantLock 保证并发安全。在 put 操作时,通过 CAS 和自旋锁确保线程安全。扩容过程是多线程安全的,仅限于单个 Segment 进行,避免了循环链表的问题。
本文详细解析了JDK1.7 ConcurrentHashMap的源码,包括其数据结构、初始化过程、put流程以及线程安全策略。ConcurrentHashMap采用分段 Segment 的设计,每个 Segment 类似一个小型 HashMap,内置 ReentrantLock 保证并发安全。在 put 操作时,通过 CAS 和自旋锁确保线程安全。扩容过程是多线程安全的,仅限于单个 Segment 进行,避免了循环链表的问题。
前面说到JDK1.7 HashMap是数组+链表的数据结构,但是这是线程不安全的。而ConcurrentHashMap则是HashMap的升级版解决了线程安全问题,而且底层大部分逻辑和HashMap是相似的。接下来还是通过QA方式解析源码。
1.ConcurrentHashMap的数据结构是怎么样的?初始化过程是怎么样的?
(1)首先,ConcurrentHashMap设计是作为线程安全的Map集合,那么就需要考虑怎么支持并发操作,我们用HashMap进行对比,就可以知道HashMap要想并发安全操作就不能不对整个HashMap进行加锁,这样大大影响了整个容器的性能。

作为解决这个问题的设计者们,在ConcurrentHashMap就想到了基于HashMap的数组+链表的思想,将每个数组都拆分成一个个小型各自独立的Segment(每个Segment相当于一个个小型HashMap),每个线程加锁只对各自独立的Segment去加锁操作,这样就大大提升了性能。于是就引入了“分段Segment”的思想,每个分段还集成了ReentrantLock可以对内部HashEntry数据进行CAS操作,这样就保证了线程安全。基于此,ConcurrentHashMap的数据结构图大致可以如下:

上图可知:在JDK7的ConcurrentHashMap中,首先有一个Segment数组,存的是Segment对象,Segment相当于一个小HashMap,而Segment内部有一个HashEntry的数组用于存储实际数据。
(2)ConcurrentHashMap有哪些核心属性,数据结构是怎么初始化的?
从上面知道ConcurrentHashMap与HashMap的属性相似,不同的是ConcurrentHashMap内部有一个Segment数组,而每个Segment内部存储HashEntry数组。
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
//默认初始化容量大小16
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默认加载因子0.75
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Segment分段的数量,默认也是16个分段数
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
/**
* 最大容量数:2^30,保证所有元素可以存储不越界
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 每个Segment内部的HashMap数组最小长度:默认最小为2
*/
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
/**
* 每个Segment内部的HashMap数组最大长度:最大为2^16
*/
static final int MAX_SEGMENTS = 1 << 16;
/**
* 尝试非阻塞加锁次数,如果超过次数还没能加锁则转换为阻塞等待加锁
*/
static final int RETRIES_BEFORE_LOCK = 2;
/**
* hash种子,可影响hash散列
*/
private transient final int hashSeed = randomHashSeed(this);
/**
* 当前segments数组的最大下标
*/
final int segmentMask;
/**
* 32-(segments数组长度最大下标对应二进制最高位1开始往后占据的位数)
* 例如20=0001 0100,则最高位1开始往后共占据5个位数,则segmentShift=32-5=27。
* 相当于保留hash值的高n位,用于put操作对hash右移segmentShift位数,使hash的高n位
* 算出要存在segments哪个位置。
*/
final int segmentShift;
/**
* 最核心的segment分段数组,是一个Segment对象
*/
final Segment<K,V>[] segments;
/**
* HashEntry定义,和HashMap定义一样。
* 不同的是内部的next属性是通过UNSAFE工具类线程安全方式获取;
* hash属性的高位用于计算segment下标,低位又用于计算table下标
*/
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
/**
* Sets next field with volatile write semantics. (See above
* about use of putOrderedObject.)
*/
final void setNext(HashEntry<K,V> n) {
UNSAFE.putOrderedObject(this, nextOffset, n);
}
// UNSAFE工具类
static final sun.misc.Unsafe UNSAFE;
static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = HashEntry.class;
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
/**
* 核心Segment定义。内部属性和方法和HashMap基本一样
*/
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 实际数据存储数组table
*/
transient volatile HashEntry<K,V>[] table;
/**
* HashMap已存储元素个数
*/
transient int count;
/**
* HashMap操作次数:新增,删除,更新
*/
transient int modCount;
/**
* 扩容阈值
*/
transient int threshold;
/**
* HashMap加载因子
*/
final float loadFactor;
}
}从源码上看ConcurrentHashMap底层是由两层嵌套数组来实现的:
1.ConcurrentHashMap对象中有一个属性segments,类型为Segment[];
2.Segment对象中有一个属性table,类型为HashEntry[];
接下来看下数据结构的初始化过程。ConcurrentHashMap也有以下多种构造函数:
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel); ConcurrentHashMap(int initialCapacity, float loadFactor); ConcurrentHashMap(int initialCapacity); ConcurrentHashMap(); ConcurrentHashMap(Map<? extends K, ? extends V> m);
可以看出主要也是对初始化容量,加载因子,初始Segment长度进行初始化。这里要特别注意concurrencyLevel这个属性的作用,下面是构造函数核心代码和相关注释:
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//检查参数的合法性
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
//ssize是Segment数组的长度,
//ssize通过位移操作获得一个刚好比concurrencyLevel大一点的2幂次方整数
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
/**
*初始化segmentShift= 32-(segments数组长度最大下标对应二进制最高位1开始往后占据的位数),例如20=0001 0100,则最高位1开始往后共占据5个位数,则segmentShift=32-5=27。
* 相当于保留hash值的高n位,用于put操作对hash右移segmentShift位数,使hash的高n位
* 算出要存在segments哪个位置。
**/
this.segmentShift = 32 - sshift;
//初始化segmentMask=segments数组最大的数组下标,用于后面计算角标位置
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//根据初始化容量和segments数组长度进行均分,
//通过均分方式获得一个大于等于均分值的整数,作为每个segment内部的table数组长度,
//且每个segment内部table数组长度最小为2,最终值为cap用于初始化Segment对象
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY; //cap最小值为2
while (cap < c)
cap <<= 1;
//创建一个Segment[0]对象,这个对象可以用于当其它Segment位置需要初始化时,
//可以通过Segment[0]对象原型模式直接复制过去
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
//初始化Segment数组,数组长度就是取一个刚好比concurrencyLevel大一点的2幂次方整数
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//将上面创建的Segment[0]通过UNSAFE使用CAS方式写入Segment数组内存
UNSAFE.putOrderedObject(ss, SBASE, s0);
//初始化完成的segment数组赋值到segments属性中
this.segments = ss;
}
通过上述构造函数,一个ConcurrentHashMap对象就产生了,这个对象有Segment数组对象,且Segment[0]初始化了一个table数组长度固定的小型HashMap。
2.ConcurrentHashMap的put流程是怎么样的?
public V put(K key, V value) {
Segment<K,V> s;
//ConcurrentHashMap是不能存储value=null的数据的
if (value == null)
throw new NullPointerException();
//计算hash散列值,如果hashseed种子有值也会参与计算,和hashmap类似
int hash = hash(key);
//和segmentMask对应的segments长度与操作计算要存入哪个segments数组下标。
//这里使用hash值的高(32-segmentShift)位参与计算segments下标
int j = (hash >>> segmentShift) & segmentMask;
//判断segments[j]如果为空,则自旋执行ensureSegment生成该位置一个新segment对象
//UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)实际上是获取segments数组的第j个位置数据,SSHIFT是数组对象头,SBASE是数组的起始位置,两个变量都在static中定义了
if ((s = (Segment<K,V>)UNSAFE.getObject(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
//通过获取到的segment,将数据写入该segment对应的table数组中
return s.put(key, hash, value, false);
}
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
//检查此时segments的u位置处是不是已经有初始化好的segment对象,
//因为可能这时已经被其它线程初始化出来了,通过UNSAFE操作内存对象并返回
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
//还没被初始化过,则通过原型模式复制方式得到该新位置segment对象,
//根据segment[0]位置的原型对象初始化一个HashEntry数组待用
Segment<K,V> proto = ss[0]; //use segment 0 as prototype使用segment[0]作为原型
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
//初始化后UNSAFE再判断此刻内存中该位置是不是已经有segment被初始化出来了
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
//此刻还是没有被其它线程初始化segment出来,接下来传入属性构造出新的segment对象
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
//通过自旋方式,假如始终没有其他线程初始化该位置segment对象,那么就通过CAS方式
//写入到segments[u]位置的内存中,退出并返回该新segment对象。
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
得到一个Segment之后就调用Segment对象,执行复杂的加锁s.put(key, hash, value, false)操作
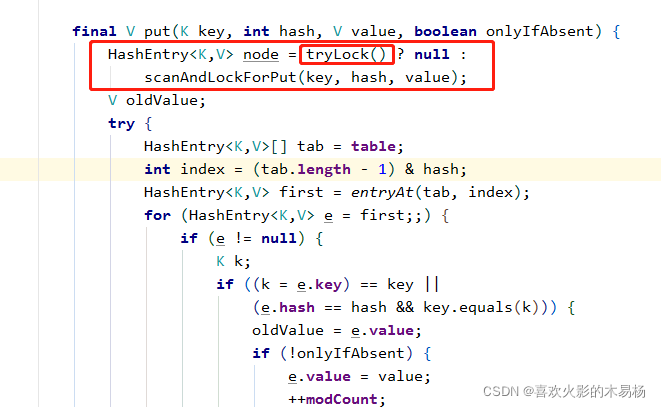
当tryLock()得不到锁,则继续尝试加锁,当加锁次数达到最大尝试次数,则转换为lock阻塞等待加锁:
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash); //first记录当前链表的头结点,用于辅助判断本链表是否已经被改变了
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
//不断尝试tryLock获取锁,在尝试期间会先遍历这个要加锁的链表,看是否有匹配的k-V数据,如果没有就提前将数据封装成HashEntry对象。
//但是在尝试加锁遍历期间,很可能这个要加锁的segnemt内部链表数据已经被其它线程修改了,那么本线程就要重新检查遍历这条链表数据
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) //本链表没有匹配k-v数据,则提前创建出hashEntry
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) { //当超过尝试次数则阻塞lock方式等待锁
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; //当本链表的数据已经被其它线程改变了,那么最新本链表的头结点肯定就改变了不再等于方法入口声明的first结点,此时需要重新对最新改变后的链表进行遍历
retries = -1; //重置重试次数
}
}
return node;
}
当加锁成功之后,后面的新增HashEntry逻辑和HashMap一样了,都是头插法添加到table后解锁。
总结:当调用ConcurrentHashMap的put方法时,先根据key计算出对应的Segment[]的数组下标j,确定好当前key,value应该插入到哪个Segment对象中,如果segments[j]为空,则利用自旋锁的方式在j位置生成一个Segment对象。
然后调用Segment对象的put方法。Segment对象的put方法会先加锁,然后也根据key计算出对应的HashEntry[]的数组下标i,然后将key,value封装为HashEntry对象放入该位置,此过程和JDK7的HashMap的put方法一样,然后解锁。在加锁的过程中逻辑比较复杂,先通过自旋加锁,如果超过一定次数就会直接阻塞等等加锁。
3.ConcurrentHashMap怎么保证线程安全?
主要利用Unsafe操作+ReentrantLock+分段思想。
主要使用了Unsafe操作中的:
- compareAndSwapObject:通过cas的方式修改对象的属性
- putOrderedObject:并发安全的给数组的某个位置赋值
- getObjectVolatile:并发安全的获取数组某个位置的元素
分段思想是为了提高ConcurrentHashMap的并发量,分段数越高则支持的最大并发量越高,程序员可以通过concurrencyLevel参数来指定并发量。ConcurrentHashMap的内部类Segment就是用来表示某一个段的。
每个Segment就是一个小型的HashMap的,当调用ConcurrentHashMap的put方法是,最终会调用到Segment的put方法,而Segment类继承了ReentrantLock,所以Segment自带可重入锁,当调用到Segment的put方法时,会先利用可重入锁加锁,加锁成功后再将待插入的key,value插入到小型HashMap中,插入完成后解锁。
具体代码体现可参考第2点源码注释。
4.ConcurrentHashMap扩容过程是怎么样的?
JDK7中的ConcurrentHashMap和JDK7的HashMap的扩容是不太一样的。
首先JDK7中也是支持多线程扩容的,原因是JDK7中的ConcurrentHashMap分段了,每一段叫做Segment对象,每个Segment对象相当于一个HashMap。分段之后,对于ConcurrentHashMap而言,能同时支持多个线程进行操作,前提是这些操作的是不同的Segment,而ConcurrentHashMap中的扩容是仅限于本Segment,也就是对应的小型HashMap进行扩容,换言之就是将每个Segement作为一把独立的可重入锁提供给不同线程竞争,所以是可以多线程扩容的。
对于每个Segment内部的扩容逻辑和HashMap中一样,都是创建新table,再将源数据转移到新table中。由于同一时间扩容时只会有一个线程得到锁进行扩容,就不会存在多线程循环链表的问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









