







 本文探讨了推荐系统中用户和物品冷启动问题的解决方案,包括利用用户注册信息进行分类推荐,选择合适物品激发用户兴趣,以及利用物品内容信息和专家作用进行物品推荐的方法。
本文探讨了推荐系统中用户和物品冷启动问题的解决方案,包括利用用户注册信息进行分类推荐,选择合适物品激发用户兴趣,以及利用物品内容信息和专家作用进行物品推荐的方法。
一、思维导图
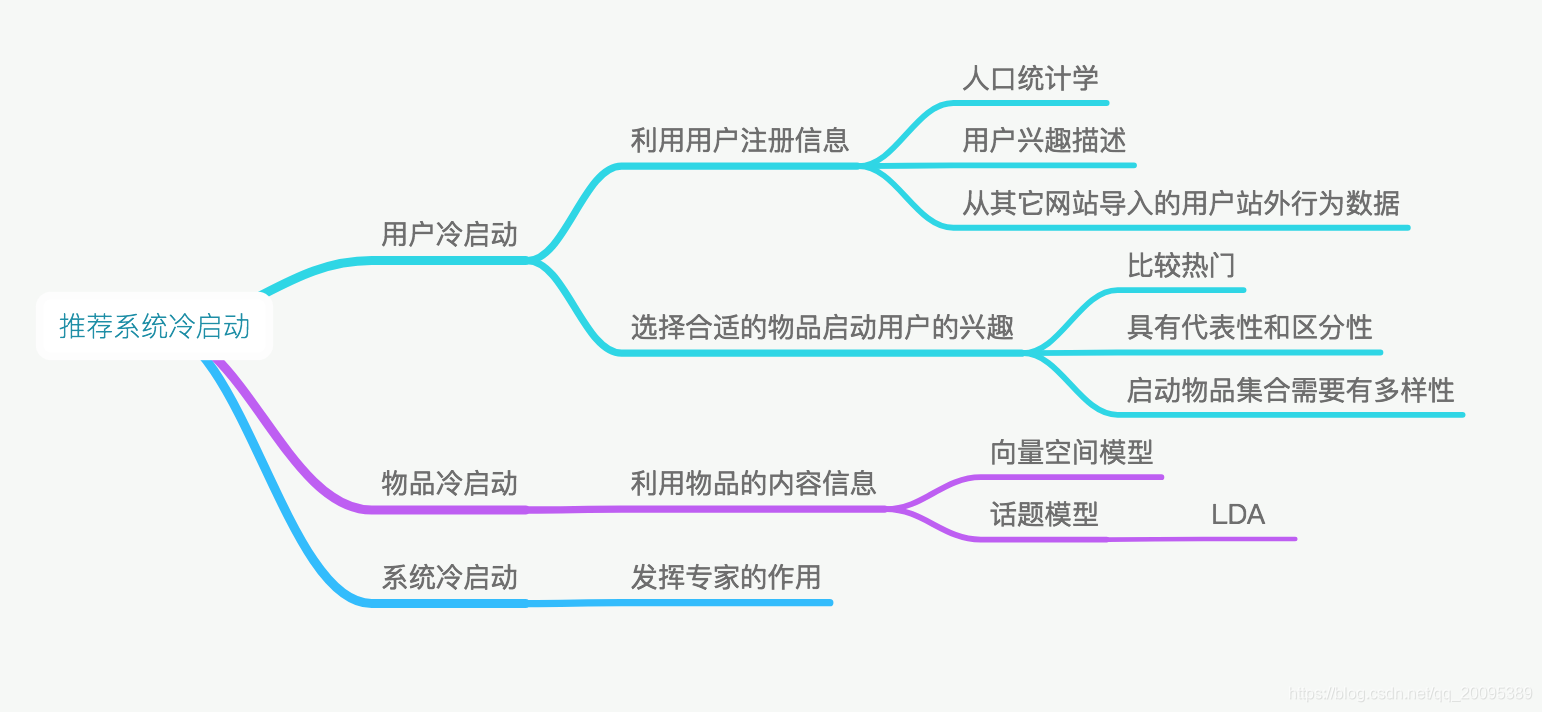
二、用户冷启动
1、利用用户注册信息
算法流程
- 获取用户的注册信息
- 根据用户的注册信息对用户分类
- 给用户推荐他所属分类中用户喜欢的物品
重点 - 计算每种特征用户喜欢的物品
- 方式一:p(f,i):有f特征的用户中喜欢物品i的人数
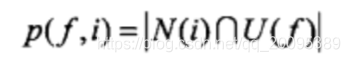
- 方式二:惩罚热门物品
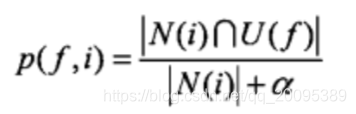
- 一般来说,分类粒度越细,精度和覆盖率也会越高
2、选择合适的物品启动用户的兴趣
什么是合适的物品?
- 比较热门
- 具有代表性和区分性
- 启动物品集合需要多样性
如何选择启动物品集合?
基本思想,选择物品区分度大的作为启动物品集合,然后利用决策树将用户兴趣提取出来,再推荐同类型的物品~
- 算法,其中 δ u ∈ N + ( i ) \delta_{u\in N^{+}(i)} δu∈N+(i)是喜欢物品i的用户对其他物品评分的方差, δ u ∈ N − ( i ) \delta_{u\in N^{-}(i)} δu∈N−(i)是不喜欢物品i的用户对其他物品评分的方差, δ u ∈ N ˉ ( i ) \delta_{u\in \bar{N}(i)} δu∈Nˉ(i)是没有对物品i评分的用户对其他物品评分的方差。
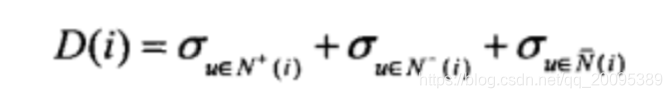
3、两个算法的区别
- 利用用户注册信息,一般是基本信息,无法知道用户的兴趣,或用户自己也不知道自己兴趣的情况下,因此利用用户的类别和这类别用户喜欢的物品推荐,更具社交属性。
- 选择合适的物品启动兴趣,主要利用用户对物品的选择,发掘用户的兴趣点,给用户推荐同类别的物品,更具有用户自我的独特个性~
三、物品冷启动
1、利用物品的内容信息
个人感觉这应该是依据具体业务,然后自己制定相应的算法,这边所谓的算法,除了通用的,基本是根据业务自己设定的逻辑条件等,就像传统图像算法一样。
向量空间模型
- 将文本信息表示成关键向量 d i = { ( e 1 , w 1 ) , ( e 2 , w 2 ) . . . } d_{i}=\{(e_{1},w_{1}),(e_{2},w_{2})...\} di={(e1,w1),(e2,w2)...},其中 e i e_{i} ei是关键词,w_{i}是关键词对应的权重。

- 权重计算利用TF-IDF理论https://www.cnblogs.com/pinard/p/6693230.html
w i = T F ( e i ) l o g D F ( e i ) w_{i}=\frac{TF(e_{i})}{logDF(e_{i})} wi=logDF(ei)TF(ei) - 计算物品相似度
w i j = d i ∗ d j ∥ d i ∥ ∥ d j ∥ w_{ij}=\frac{d_{i}*d_{j}}{\sqrt{\left\|d_{i}\right\|\left\|d_{j}\right\|}} wij=∥di∥∥dj∥di∗dj - ItermCF 的思想,给用户推荐和他历史上喜欢的物品相似的物品。
话题模型
- 解决文本很短,关键词很少情况,物品相似度难以计算的问题。例如:推荐系统的动态特性VS基于时间的协同过滤算法研究。因此需要建立文章,话题,关键词的关系
- LDA算法
- 对z初始化,z[i][j]是第i篇文档中第j个词属于的话题
- 迭代使话题的分布收敛到一个合理的分布上去
- 这篇讲的比较好LDA原理讲解通俗版

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









