









 该博客讨论了一种使用双指针方法解决在大文本文件中查找两个不同单词最短距离的问题。在给定的示例中,给出了如何在字符串数组中找到单词'a'和'student'的最短距离。进阶问题提出了一种优化方案,即通过维护哈希表来存储单词的下标,以提高多次查找的效率。这种方法减少了重复遍历文件的次数,提高了查找速度。
该博客讨论了一种使用双指针方法解决在大文本文件中查找两个不同单词最短距离的问题。在给定的示例中,给出了如何在字符串数组中找到单词'a'和'student'的最短距离。进阶问题提出了一种优化方案,即通过维护哈希表来存储单词的下标,以提高多次查找的效率。这种方法减少了重复遍历文件的次数,提高了查找速度。
面试题 17.11. 单词距离 ●●
描述
有个内含单词的超大文本文件,给定任意两个不同的单词,找出在这个文件中这两个单词的最短距离(相隔单词数)。
进阶问题:
如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,你能对此优化吗?
示例
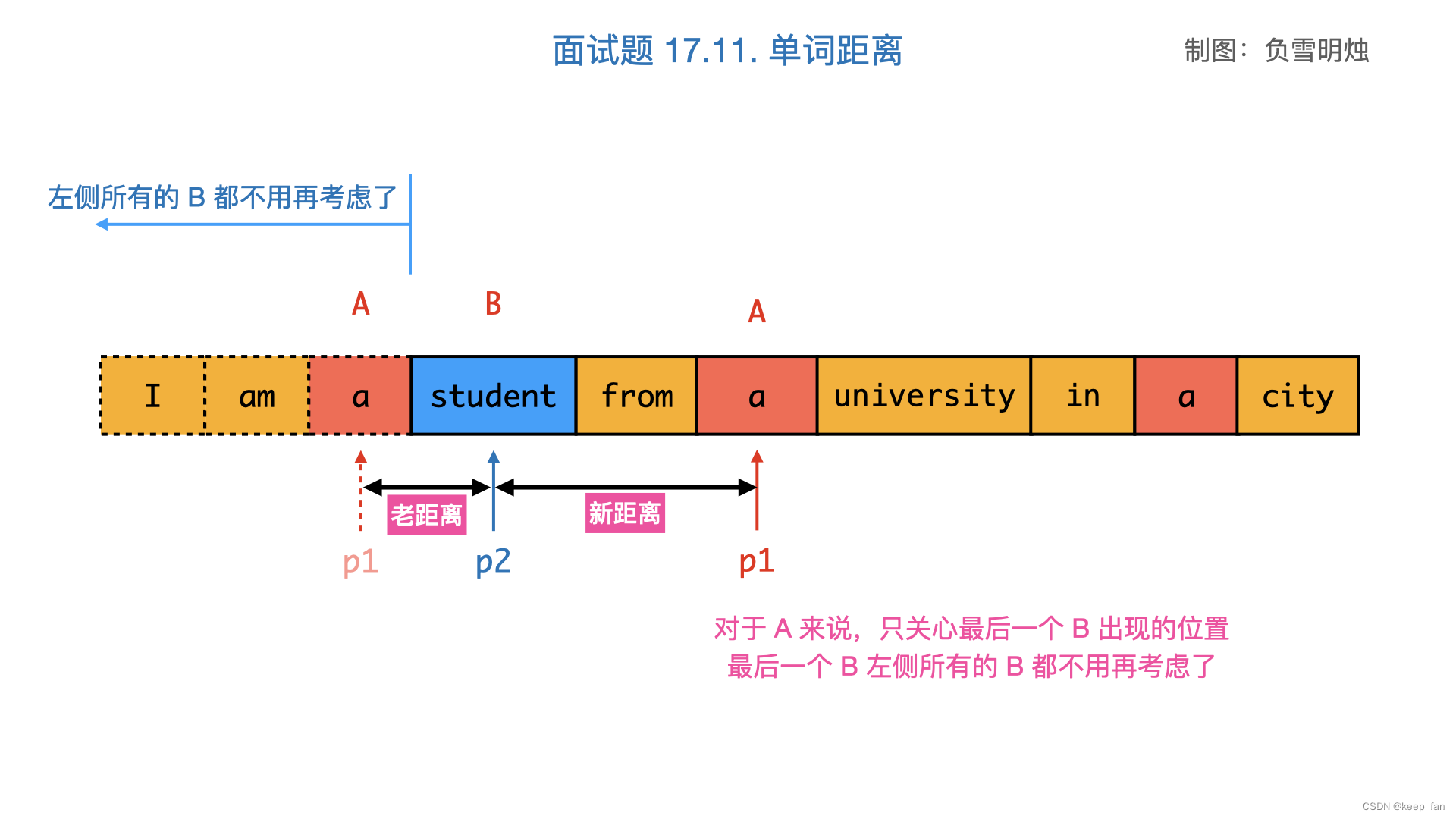
输入:words = [“I”,“am”,“a”,“student”,“from”,“a”,“university”,“in”,“a”,“city”], word1 = “a”, word2 = “student”
输出:1
题解
1. 双指针
建立两个指针,在遍历字符串数组的过程中,两个指针分别指向已遍历范围内,对应单词的最大下标 idx1 和 idx2 (即遇到对应单词变更新指针位置),每次计算并更新间隔距离。
- 时间复杂度:O(n),其中 nn 是数组 words 的长度。需要遍历数组一次计算 word1 和 word2 的最短距离,每次更新下标和更新最短距离的时间都是 O(1)。这里将字符串的长度视为常数。
- 空间复杂度:O(1)。
class Solution {
public:
int findClosest(vector<string>& words, string word1, string word2) {
int idx1 = -1, idx2 = -1;
int ans = INT_MAX;
for(int i = 0; i < words.size(); ++i){
if(words[i] == word1 || words[i] == word2){
if(words[i] == word1){ // 更新指针
idx1 = i;
}else{
idx2 = i;
}
if(idx1 >= 0 && idx2 >= 0){ // 更新距离
ans = min(ans, abs(idx1 - idx2));
if(ans == 1) return 1;
}
}
}
return ans;
}
};
进阶问题:
如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,
则可以维护一个哈希表记录每个单词的下标列表。
遍历一次文件,按照下标递增顺序得到每个单词在文件中出现的所有下标。
在寻找单词时,只要得到两个单词的下标列表,使用双指针遍历两个下标链表,即可得到两个单词的最短距离。

















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









