







 本文介绍了算法性能评估的两个关键指标——时间复杂度和空间复杂度,重点讲解了如何计算时间复杂度和空间复杂度,以及渐进符号(大O、大Ω、大Θ、小o、小ω)的含义。常见的时间复杂度计算规则包括常数项忽略、保留最高次幂项等。此外,还讨论了均摊复杂度的概念,以快速排序为例解释了均摊复杂度的重要性。
本文介绍了算法性能评估的两个关键指标——时间复杂度和空间复杂度,重点讲解了如何计算时间复杂度和空间复杂度,以及渐进符号(大O、大Ω、大Θ、小o、小ω)的含义。常见的时间复杂度计算规则包括常数项忽略、保留最高次幂项等。此外,还讨论了均摊复杂度的概念,以快速排序为例解释了均摊复杂度的重要性。
复杂度
评估算法性能的两个指标
- 执行时间->时间复杂度
- 内存消耗->空间复杂度
通常在服务端领域我们更关注的是执行时间,这是因为内存消耗可以回收,并且用户不会关心服务端那边执行一个程序用了多少空间。
「时间复杂度」与「空间复杂度」的前面还有一个词,叫「渐进」,它表示的是:算法在输入数据的规模成倍增长的时候,相应的时间消耗多增长了多少。例如数学家高斯计算 1 到 100 的和,如果按照普通加法一个一个加起来来算,计算 1 到 1000000 消耗的时间一般来说会更多,而高斯使用的等差数列前 n 项和公式,就可以保证当问题规模成倍扩大的时候,计算资源的消耗不受太大影响。
int n = 100;
int sum = 0;
for (int i = 1; i <= n; i++) {
sum += i;
}
System.out.println(sum);
说明:这个算法执行的操作数与输入规模 n 线性相关,n 越大,执行的操作数越多,消耗时间越长。
int n = 100;
int sum = (1 + n) * n / 2;
System.out.println(sum);
说明:这个算法执行的操作数与 n 无关。不论 n 多大,程序的执行的次数都是常数次的。
计算时间复杂度与空间复杂度
时间复杂度的计算(估算)只有在输入规模特别大的时候才有意义。「输入规模特别大」往往是我们初学的时候不可感知的。大 O 表示法是一种事前估计法,得到一个函数表达式,它表示了:随着输入规模的扩大,程序的执行消耗会扩大的程度。这个程度不是直接从表达式上直接看出来的,需要在一个动态增加的过程中去理解程序的执行消耗会扩大的程度。
在数据规模较小的时候,不同时间复杂度的执行操作数,我们把它们画在同一个直角坐标系中,可以看出它们增长的趋势。
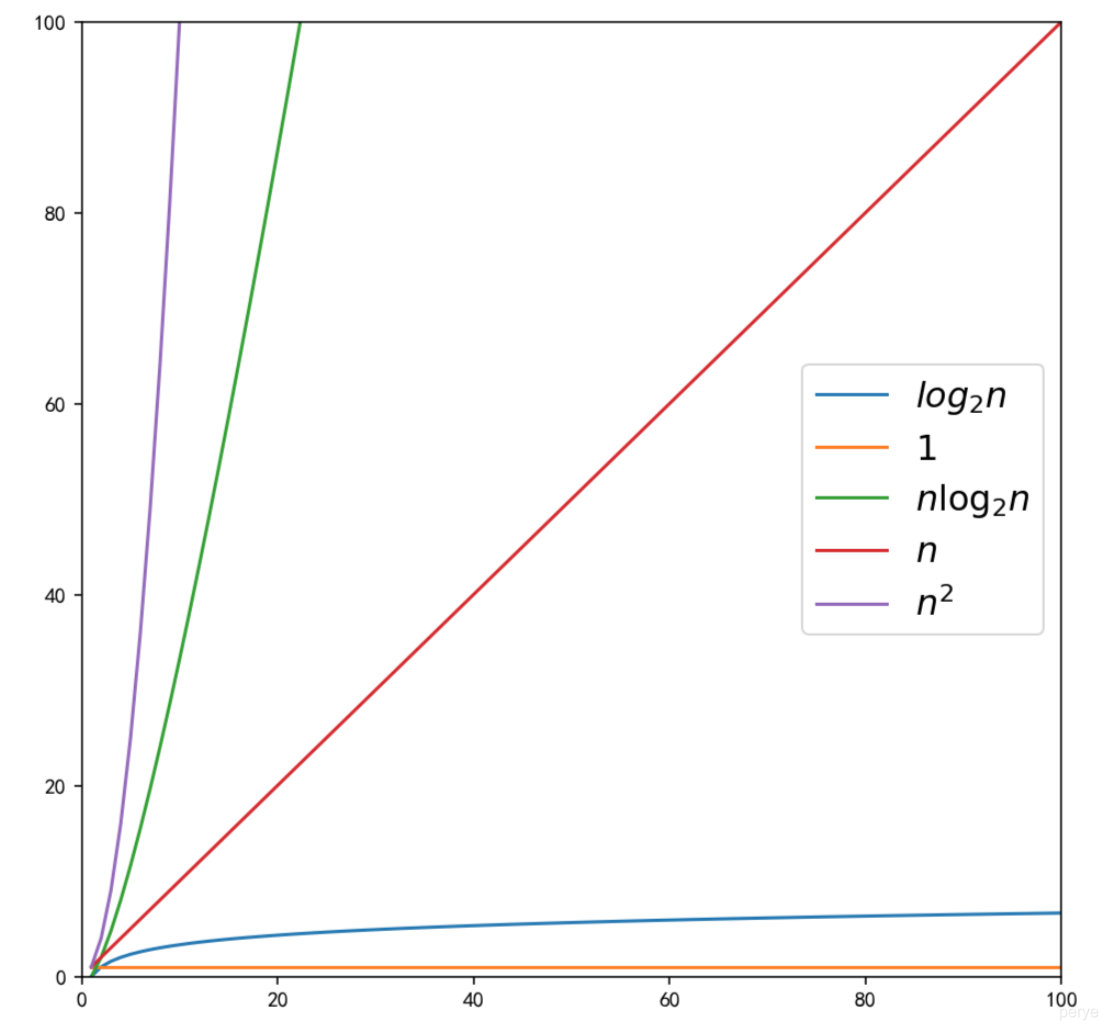
常见的时间复杂度计算规则
1、常数加法系数看做 0
一段程序必须要做的操作(常数次操作)不纳入复杂度的计算。一般而言,常数次操作都不会是造成程序性能瓶颈的原因。
2、对于一个多项式,只保留最高次幂的项,并且乘法系数化简成 1
- 一次遍历,里面不再有循环的操作,时间复杂度是 O ( N ) O(N) O(N)。也就是说,我们把输入数据里所有的元素看一遍,就可以得到结果。这样的算法称为具有线性复杂度的算法。
- 双重循环,内外层都与输入规模相关的时候,时间复杂度是 O ( N 2 ) O(N^2) O(N2)
3、对数或者是含有对数乘法因子的项,对数底都看作 2
对数级别的时间复杂度,常见且典型的算法是「二分查找」,时间复杂度的表达式为 O ( log N ) O(\log N) O(logN) 。
如果一个算法计算出来的输入规模 NN 与算法执行次数的表达式为 log 10 N \log_{10} N log10N,那么根据高中数学学习过的对数换底公式:
log a b = log c b log c a \log_{a}b =\frac {\log_{c}b}{\log_{c}a} logab=logcalogcb
有 log 10 N = log 2 N log 2 10 = 1 log 2 10 log 2 N \log_{10}N =\frac {\log_{2}N}{\log_{2}10} = \frac{1}{\log_{2}10}\log_{2}N log10N=log210log2N=log2101log2N
常数乘法系数项 1 log 2 10 \frac{1}{\log_{2}10} log2101视为1,因此写 O ( log 10 N ) O(\log_{10} N) O(log10N) 等价于 O ( log 2 N ) O(\log_{2} N)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









