







一,什么是Java Stream API?
Java Stream函数式编程接口最初是在Java 8中引入的,并且与lambda一起成为Java开发的里程碑式的功能特性,它极大的方便了开放人员处理集合类数据的效率。从笔者之前看过的调查文章显示,绝大部分的开发者使用的JDK版本是java 8,其中Java Stream和lambda功不可没。
Java Stream就是一个数据流经的管道,并且在管道中对数据进行操作,然后流入下一个管道。有学过linux 管道的同学应该会很容易就理解。在没有Java Stram之前,对于集合类的操作,更多的是通过for循环。大家从后文中就能看出Java Stream相对于for 循环更加简洁、易用、快捷。
管道的功能包括:Filter(过滤)、Map(映射)、sort(排序)等,集合数据通过Java Stream管道处理之后,转化为另一组集合或数据输出。

二、Stream API代替for循环
List<String> nameStrs = Arrays.asList("Monkey", "Lion", "Giraffe","Lemur");
List<String> list = nameStrs.stream()
.filter(s -> s.startsWith("L"))
.map(String::toUpperCase)
.sorted()
.collect(toList());
System.out.println(list);三、将数组转换为管道流
String[] array = {"Monkey", "Lion", "Giraffe", "Lemur"};
Stream<String> nameStrs2 = Stream.of(array);
Stream<String> nameStrs3 = Stream.of("Monkey", "Lion", "Giraffe", "Lemur");五、将文本文件转换为管道流
List<String> list = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
Stream<String> streamFromList = list.stream();
Set<String> set = new HashSet<>(list);
Stream<String> streamFromSet = set.stream();五、将文本文件转换为管道流
Stream<String> lines = Files.lines(Paths.get("file.txt"));
六、filter与谓语逻辑
public class StreamFilterPredicate {
public static void main(String[] args){
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
List<Employee> filtered = employees.stream()
.filter(e -> e.getAge() > 70 && e.getGender().equals("M"))
.collect(Collectors.toList());
System.out.println(filtered);
}
}谓词逻辑的复用
public static Predicate<Employee> ageGreaterThan70 = x -> x.getAge() >70;
public static Predicate<Employee> genderM = x -> x.getGender().equals("M");1.and语法(交集)
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.and(Employee.genderM))
.collect(Collectors.toList());2.or语法(并集)
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM))
.collect(Collectors.toList());3.negate语法(取反)
List<Employee> filtered = employees.stream()
.filter(Employee.ageGreaterThan70.or(Employee.genderM).negate())
.collect(Collectors.toList());七.map操作
1.基础用法
将集合中的每一个字符串,全部转换成大写!
List<String> alpha = Arrays.asList("Monkey", "Lion", "Giraffe", "Lemur");
//不使用Stream管道流
List<String> alphaUpper = new ArrayList<>();
for (String s : alpha) {
alphaUpper.add(s.toUpperCase());
}
System.out.println(alphaUpper); //[MONKEY, LION, GIRAFFE, LEMUR]
// 使用Stream管道流
List<String> collect = alpha.stream().map(String::toUpperCase).collect(Collectors.toList());
//上面使用了方法引用,和下面的lambda表达式语法效果是一样的
//List<String> collect = alpha.stream().map(s -> s.toUpperCase()).collect(Collectors.toList());
System.out.println(collect); //[MONKEY, LION, GIRAFFE, LEMUR]2、处理非字符串类型集合元素
map()函数不仅可以处理数据,还可以转换数据的类型
List<Integer> lengths = alpha.stream()
.map(String::length)
.collect(Collectors.toList());
System.out.println(lengths); //[6, 4, 7, 5]
Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.mapToInt(String::length)
.forEach(System.out::println);3、处理对象数据格式转换
- 将每一个Employee的年龄增加一岁
- 将性别中的“M”换成“male”,F换成Female。
public static void main(String[] args){
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
/*List<Employee> maped = employees.stream()
.map(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
return e;
}).collect(Collectors.toList());*/
List<Employee> maped = employees.stream()
.peek(e -> {
e.setAge(e.getAge() + 1);
e.setGender(e.getGender().equals("M")?"male":"female");
}).collect(Collectors.toList());
System.out.println(maped);
}由于map的参数e就是返回值,所以可以用peek函数。peek函数是一种特殊的map函数,当函数没有返回值或者参数就是返回值的时候可以使用peek函数。
4、flatMap
map可以对管道流中的数据进行转换操作,但是如果管道中还有管道该如何处理?即:如何处理二维数组及二维集合类。实现一个简单的需求:将“hello”,“world”两个字符串组成的集合,元素的每一个字母打印出来。如果不用Stream我们怎么写?写2层for循环,第一层遍历字符串,并且将字符串拆分成char数组,第二层for循环遍历char数组。
List<String> words = Arrays.asList("hello", "word");
words.stream()
.map(w -> Arrays.stream(w.split(""))) //[[h,e,l,l,o],[w,o,r,l,d]]
.forEach(System.out::println);输出打印结果:
java.util.stream.ReferencePipeline$Head@3551a94
java.util.stream.ReferencePipeline$Head@531be3c5- flatMap可以理解为将若干个子管道中的数据全都,平面展开到父管道中进行处理。
words.stream()
.flatMap(w -> Arrays.stream(w.split(""))) // [h,e,l,l,o,w,o,r,l,d]
.forEach(System.out::println);输出打印结果:
h
e
l
l
o
w
o
r
d5.对象的操作
class Test{
public static void tredst1(Trader trader){
System.out.println("************************");
System.out.println(trader);
}
public static void main(String[] args) {
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario","Milan");
Trader alan = new Trader("Alan","Cambridge");
Trader brian = new Trader("Brian","Cambridge");
Arrays.asList(Arrays.asList(raoul,mario,alan,brian))
.stream()
.flatMap(e->e.stream())
.forEach(item->{
tredst1(item);
});
}
}
八.Stream的状态与并行操作
通过前面章节的学习,我们应该明白了Stream管道流的基本操作。我们来回顾一下:
- 源操作:可以将数组、集合类、行文本文件转换成管道流Stream进行数据处理
- 中间操作:对Stream流中的数据进行处理,比如:过滤、数据转换等等
- 终端操作:作用就是将Stream管道流转换为其他的数据类型。这部分我们还没有讲,我们后面章节再介绍。
看下面的脑图,可以有更清晰的理解: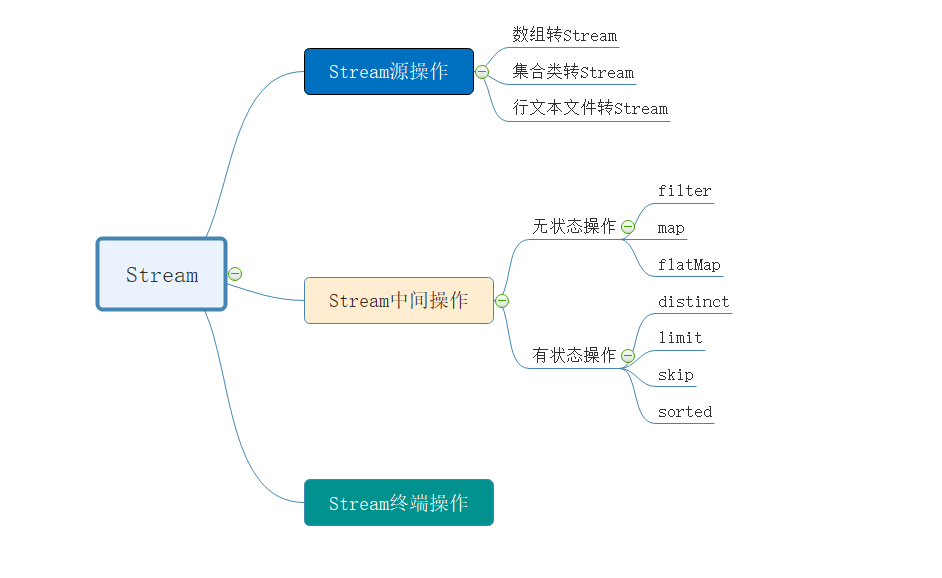
1.Limit与Skip管道数据截取
List<String> limitN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.limit(2)
.collect(Collectors.toList());
List<String> skipN = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.skip(2)
.collect(Collectors.toList());- limt方法传入一个整数n,用于截取管道中的前n个元素。经过管道处理之后的数据是:[Monkey, Lion]。
- skip方法与limit方法的使用相反,用于跳过前n个元素,截取从n到末尾的元素。经过管道处理之后的数据是: [Giraffe, Lemur]
2、Distinct元素去重
List<String> uniqueAnimals = Stream.of("Monkey", "Lion", "Giraffe", "Lemur", "Lion")
.distinct()
.collect(Collectors.toList());3、Sorted排序
List<String> alphabeticOrder = Stream.of("Monkey", "Lion", "Giraffe", "Lemur")
.sorted()
.collect(Collectors.toList());
九.像使用SQL一样排序集合
1、字符串List排序
List<String> cities = Arrays.asList(
"Milan",
"london",
"San Francisco",
"Tokyo",
"New Delhi"
);
System.out.println(cities);
//[Milan, london, San Francisco, Tokyo, New Delhi]
cities.sort(String.CASE_INSENSITIVE_ORDER);
System.out.println(cities);
//[london, Milan, New Delhi, San Francisco, Tokyo]
cities.sort(Comparator.naturalOrder());
System.out.println(cities);
//[Milan, New Delhi, San Francisco, Tokyo, london]- 当使用sort方法,按照String.CASE_INSENSITIVE_ORDER(字母大小写不敏感)的规则排序,结果是:[london, Milan, New Delhi, San Francisco, Tokyo]
- 如果使用Comparator.naturalOrder()字母自然顺序排序,结果是:[Milan, New Delhi, San Francisco, Tokyo, london]
同样我们可以把排序器Comparator用在Stream管道流中。
cities.stream().sorted(Comparator.naturalOrder()).forEach(System.out::println);
//Milan
//New Delhi
//San Francisco
//Tokyo
//london在java 7我们是使用Collections.sort()接受一个数组参数,对数组进行排序。在java 8之后可以直接调用集合类的sort()方法进行排序。sort()方法的参数是一个比较器Comparator接口的实现类,Comparator接口的我们下一节再给大家介绍一下。
2、整数类型List排序
List<Integer> numbers = Arrays.asList(6, 2, 1, 4, 9);
System.out.println(numbers); //[6, 2, 1, 4, 9]
numbers.sort(Comparator.naturalOrder()); //自然排序
System.out.println(numbers); //[1, 2, 4, 6, 9]
numbers.sort(Comparator.reverseOrder()); //倒序排序
System.out.println(numbers); //[9, 6, 4, 2, 1]3、按对象字段对List<Object>排序
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
employees.sort(Comparator.comparing(Employee::getAge));
employees.forEach(System.out::println);- 首先,我们创建了10个Employee对象,然后将它们转换为List
- 然后重点的的代码:使用了函数应用Employee::getAge作为对象的排序字段,即使用员工的年龄作为排序字段
- 然后调用List的forEach方法将List排序结果打印出来,如下(当然我们重写了Employee的toString方法,不然打印结果没有意义):
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)- 如果我们希望List按照年龄age的倒序排序,就使用reversed()方法。如:
employees.sort(Comparator.comparing(Employee::getAge).reversed());4、Comparator链对List<Object>排序
下面这段代码先是按性别的倒序排序,再按照年龄的倒序排序
employees.sort(
Comparator.comparing(Employee::getGender)
.thenComparing(Employee::getAge)
.reversed()
);
employees.forEach(System.out::println);
//都是正序 ,不加reversed
//都是倒序,最后面加一个reserved
//先是倒序(加reserved),然后正序
//先是正序(加reserved),然后倒序(加reserved)
5、自定义Comparator排序
我们自定义一个排序器,实现compare函数(函数式接口Comparator唯一的抽象方法)。返回0表示元素相等,-1表示前一个元素小于后一个元素,1表示前一个元素大于后一个元素。这个规则和java 8之前没什么区别。
下面代码用自定义接口实现类的的方式实现:按照年龄的倒序排序!
employees.sort(new Comparator<Employee>() {
@Override
public int compare(Employee em1, Employee em2) {
if(em1.getAge() == em2.getAge()){
return 0;
}
return em1.getAge() - em2.getAge() > 0 ? -1:1;
}
});
employees.forEach(System.out::println);最终的打印结果如下,按照年龄的自定义规则进行排序。
Employee(id=8, age=79, gender=M, firstName=Alex, lastName=Gussin)
Employee(id=7, age=68, gender=F, firstName=Melissa, lastName=Roy)
Employee(id=10, age=45, gender=M, firstName=Naveen, lastName=Jain)
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)
Employee(id=4, age=26, gender=M, firstName=Jon, lastName=Lowman)
Employee(id=1, age=23, gender=M, firstName=Rick, lastName=Beethovan)
Employee(id=5, age=19, gender=F, firstName=Cristine, lastName=Maria)
Employee(id=9, age=15, gender=F, firstName=Neetu, lastName=Singh)
Employee(id=6, age=15, gender=M, firstName=David, lastName=Feezor)
Employee(id=2, age=13, gender=F, firstName=Martina, lastName=Hengis)
这段代码如果以lambda表达式简写。箭头左侧是参数,右侧是函数体,参数类型和返回值根据上下文自动判断。如下:
employees.sort((em1,em2) -> {
if(em1.getAge() == em2.getAge()){
return 0;
}
return em1.getAge() - em2.getAge() > 0 ? -1:1;
});
employees.forEach(System.out::println);5、求最大值和最小值
// 找出最大值
int[] array=new int[]{123,43,2453,3,532,5,324,123,21,412,3,123,2154,35,123241,125443};
int max = Arrays.stream(array).max().getAsInt();
System.out.println(max);
//最小值
int min = Arrays.stream(array).min().getAsInt();
System.out.println(min);5、List集合中最大值和最小值
List<Integer> integers = Arrays.asList(1, 1, 23, 43, 4, 4, 21, 3, 21, 321, 3, 214, 12, 34, 13, 21, 4, 214);
List<Integer> collect = integers.stream().distinct().collect(Collectors.toList());
System.out.println(collect);
//方式1
System.out.println(collect.stream().mapToInt(e->e).max().getAsInt());
//方式2
System.out.println(collect.stream().max(Integer::compare).get());十.Stream查找与匹配元素
1、对比一下有多简单
employees是10个员工对象组成的List,在前面的章节中我们已经用过多次,这里不再列出代码。
如果我们不用Stream API实现,查找员工列表中是否包含年龄大于70的员工?代码如下:
boolean isExistAgeThan70 = false;
for(Employee employee:employees){
if(employee.getAge() > 70){
isExistAgeThan70 = true;
break;
}
}如果我们使用Stream API就是下面的一行代码,其中使用到了我们之前学过的"谓词逻辑"。
boolean isExistAgeThan70 = employees.stream().anyMatch(Employee.ageGreaterThan70);将谓词逻辑换成lambda表达式也可以,代码如下:
boolean isExistAgeThan72 = employees.stream().anyMatch(e -> e.getAge() > 72);所以,我们介绍了第一个匹配规则函数:anyMatch,判断Stream流中是否包含某一个“匹配规则”的元素。这个匹配规则可以是lambda表达式或者谓词。
2、其他匹配规则函数介绍
- 是否所有员工的年龄都大于10岁?allMatch匹配规则函数:判断是够Stream流中的所有元素都符合某一个"匹配规则"。
boolean isExistAgeThan10 = employees.stream().allMatch(e -> e.getAge() > 10);- 是否不存在小于18岁的员工?noneMatch匹配规则函数:判断是否Stream流中的所有元素都不符合某一个"匹配规则"。
boolean isExistAgeLess18 = employees.stream().noneMatch(e -> e.getAge() < 18);3、元素查找与Optional
从列表中按照顺序查找第一个年龄大于40的员工。
Optional<Employee> employeeOptional
= employees.stream().filter(e -> e.getAge() > 40).findFirst();
System.out.println(employeeOptional.get());打印结果
Employee(id=3, age=43, gender=M, firstName=Ricky, lastName=Martin)Optional类代表一个值存在或者不存在。在java8中引入,这样就不用返回null了。
- isPresent() 将在 Optional 包含值的时候返回 true , 否则返回 false 。
- ifPresent(Consumer block) 会在值存在的时候执行给定的代码块。我们在第3章
介绍了 Consumer 函数式接口;它让你传递一个接收 T 类型参数,并返回 void 的Lambda
表达式。 - T get() 会在值存在时返回值,否则?出一个 NoSuchElement 异常。
- T orElse(T other) 会在值存在时返回值,否则返回一个默认值。
- findFirst用于查找第一个符合“匹配规则”的元素,返回值为Optional
- findAny用于查找任意一个符合“匹配规则”的元素,返回值为Optional
十一.Stream集合元素归约
1.Integer类型归约
reduce初始值为0,累加器可以是lambda表达式,也可以是方法引用。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6);
int result = numbers
.stream()
.reduce(0, (subtotal, element) -> subtotal + element);
System.out.println(result); //21
int result = numbers
.stream()
.reduce(0, Integer::sum);
System.out.println(result); //21
2.String类型归约
不仅可以归约Integer类型,只要累加器参数类型能够匹配,可以对任何类型的集合进行归约计算。
List<String> letters = Arrays.asList("a", "b", "c", "d", "e");
String result = letters
.stream()
.reduce("", (partialString, element) -> partialString + element);
System.out.println(result); //abcde
String result = letters
.stream()
.reduce("", String::concat);
System.out.println(result); //ancde
3.复杂对象归约
计算所有的员工的年龄总和。
Employee e1 = new Employee(1,23,"M","Rick","Beethovan");
Employee e2 = new Employee(2,13,"F","Martina","Hengis");
Employee e3 = new Employee(3,43,"M","Ricky","Martin");
Employee e4 = new Employee(4,26,"M","Jon","Lowman");
Employee e5 = new Employee(5,19,"F","Cristine","Maria");
Employee e6 = new Employee(6,15,"M","David","Feezor");
Employee e7 = new Employee(7,68,"F","Melissa","Roy");
Employee e8 = new Employee(8,79,"M","Alex","Gussin");
Employee e9 = new Employee(9,15,"F","Neetu","Singh");
Employee e10 = new Employee(10,45,"M","Naveen","Jain");
List<Employee> employees = Arrays.asList(e1, e2, e3, e4, e5, e6, e7, e8, e9, e10);
Integer total = employees.stream().map(Employee::getAge).reduce(0,Integer::sum);
System.out.println(total); //346- 先用map将Stream流中的元素由Employee类型处理为Integer类型(age)。
- 然后对Stream流中的Integer类型进行归约
十二.练习题
public static void main(String[] args) {
Trader raoul = new Trader("Raoul", "Cambridge");
Trader mario = new Trader("Mario","Milan");
Trader alan = new Trader("Alan","Cambridge");
Trader brian = new Trader("Brian","Cambridge");
List<Transaction> transactions = Arrays.asList(
new Transaction(brian, 2011, 300),
new Transaction(raoul, 2012, 1000),
new Transaction(raoul, 2011, 400),
new Transaction(mario, 2012, 710),
new Transaction(mario, 2012, 700),
new Transaction(alan, 2012, 950)
);
Stream<Transaction> stream = transactions.stream();
//(1) 找出2011年发生的所有交易,并按交易额排序(从低到高)。
Predicate<Transaction> year=e->e.getYear()==2011;
stream
.filter(year)
.sorted(Comparator.comparing(e->e.getValue()))
.collect(Collectors.toList()).forEach(System.out::println);
//(2) 交易员都在哪些不同的城市工作过?
transactions.stream().map(e->e.getTrader().getCity()).distinct().collect(Collectors.toList()).forEach(System.out::println);
System.out.println("---------------------------------2");
//(3) 查找所有来自于剑桥的交易员,并按姓名排序。
transactions.stream()
.filter(e->e.getTrader().getCity().equals("Cambridge"))
.sorted(Comparator.comparing(e->e.getTrader().getName()))
.map(e->e.getTrader().getName())
.distinct()
.collect(Collectors.toList())
.forEach(System.out::println);
System.out.println("---------------------------------3");
//(4) 返回所有交易员的姓名字符串,按字母顺序排序。
transactions.stream()
.map(e->e.getTrader().getName())
.sorted(Comparator.naturalOrder())
.distinct()
.collect(Collectors.toList())
.forEach(System.out::println);
System.out.println("---------------------------------4");
String reduce = transactions.stream()
.map(e -> e.getTrader().getName())
.distinct()
.sorted()
.reduce("", (n1, n2) -> n1 + n2);
System.out.println(reduce);
System.out.println("------------------------------------4");
// (5) 有没有交易员是在米兰工作的?
boolean milan = transactions.stream()
.anyMatch(e -> e.getTrader().getCity().equals("Milan"));
System.out.println(milan);
System.out.println("_-----------------------------------5");
//(6) 打印生活在剑桥的交易员的所有交易额。
transactions.stream()
.filter(e->e.getTrader().getCity().equals("Cambridge"))
.map(Transaction::getValue)
.collect(Collectors.toList())
.forEach(System.out::println);
System.out.println("_------------------------------------6");
//(7) 所有交易中,最高的交易额是多少?
Integer integer = transactions.stream()
.map(Transaction::getValue)
.max(Integer::compareTo).get();
System.out.println(integer);
System.out.println("_------------------------------------8");
//(8) 找到交易额最小的交易。
Integer integer1 = transactions.stream()
.map(Transaction::getValue)
.min(Integer::compareTo).get();
System.out.println(integer1);
}

















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









