







原文链接 http://tecdat.cn/?p=1614
【视频】支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
,时长07:24
In order to solve the problem of safety accidents in production and life, we can use the current rapid development of DM (Data Mining) technology to realize the accident prediction of the monitoring system through the multi-dimensional analysis of the accident information, improve the performance of the monitoring system and form the safety warning mechanism.
▼
Accident prediction requires meaningful and reliable information, and a large number of raw information flows must be analyzed and processed during the crisis.
Based on the above background, tecdat researchers focus on the collection of accident information data and analyze the relevant information, through the time, place, semantic and other different dimensions of the analysis of valuable information, and try to machine learning method to predict the occurrence of the accident.
▍时间维度事故分析
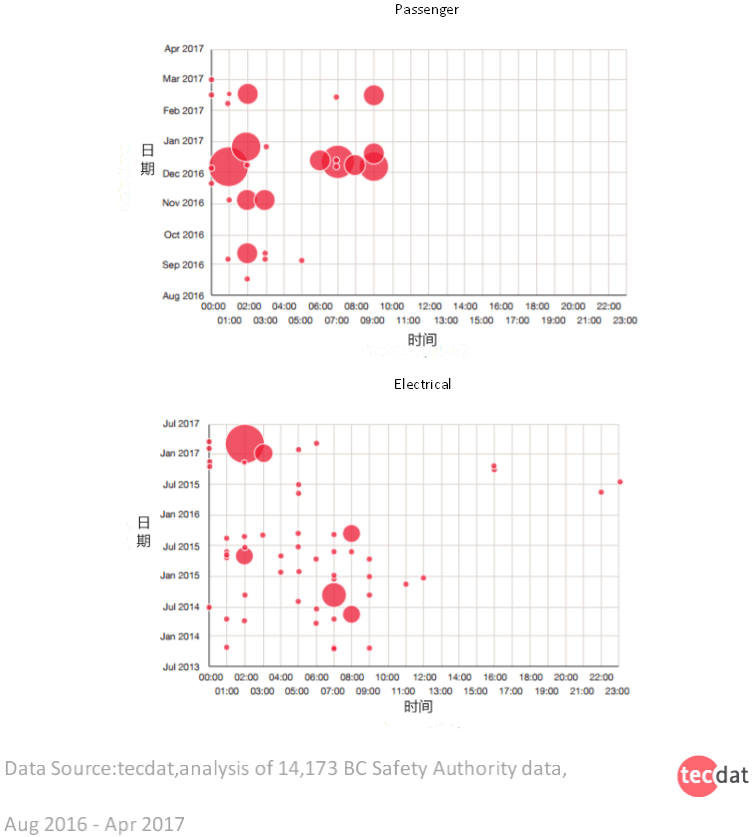
通过时间维度(日期和时间)的事故分析,我们可以洞察到不同类型的事故发生的高峰时间和高发月份,从而进行有效预防。
通过对结果的可视化,可以发现不同时间和月份的事故发生率有一定的差异,因此在后续的预测模型中可以构建相应的时间伪变量从而提高精度。
▍不同事故类型
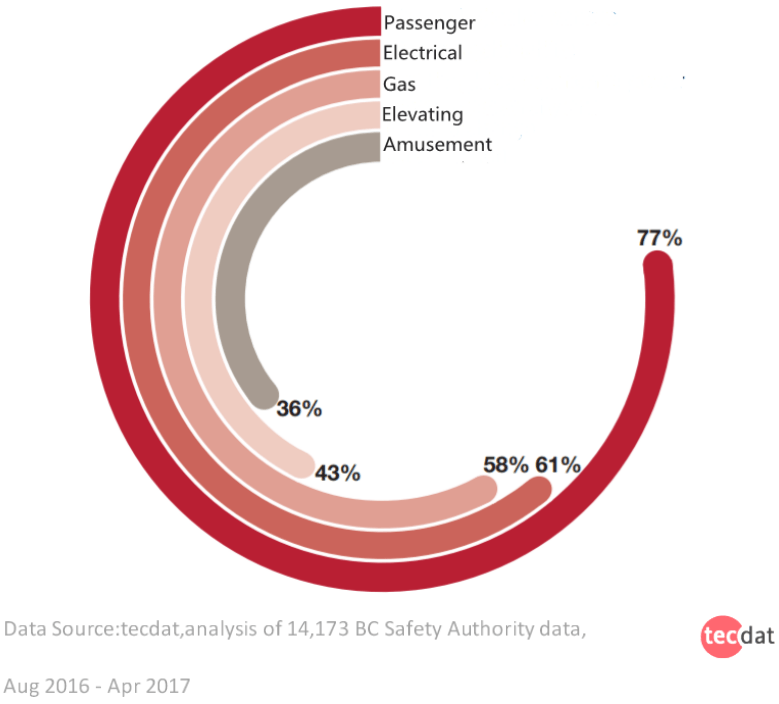
通过对所有事故数据类型的占比分析,我们可以发现出行的事故发生率是最高的,也远远高于其他类型,其次是触电事故等。(注:部分事故重属多个类型)
▍事故报告语义分析
通过对事故报告的语义分析,我们可以发现报告中频繁出现的关键词,从中洞察到某类事故发生后通常会关联到哪些关键词,分析其背后的原因,从而进行有效的预防。

▍安全事故预测模型
在获得事故的不同维度基本特征之后,我们通过SVM算法使用这些特征来预测不同类型的事故发生的可能性,采取有针对性的措施,避免未知事故发生带来的损失,达到补救的效果。
▍技术
SVM(Support Vector Machine)用于构建、验证和测试数据集的模型。
在Spark / MLLib / Scikit-Learn / HDFS中重构实现处理较大的数据集。
▍结果
模型预测精度精度达到82.5%。


















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









