







往期阅读:
Python3爬取优快云博客信息1.0(基础版-附完整代码)
Python3爬取优快云博客信息1.1(GUI版-附完整代码)
一、效果演示
1、 拷贝[我的博客]URL
2、该版本程序运行效果
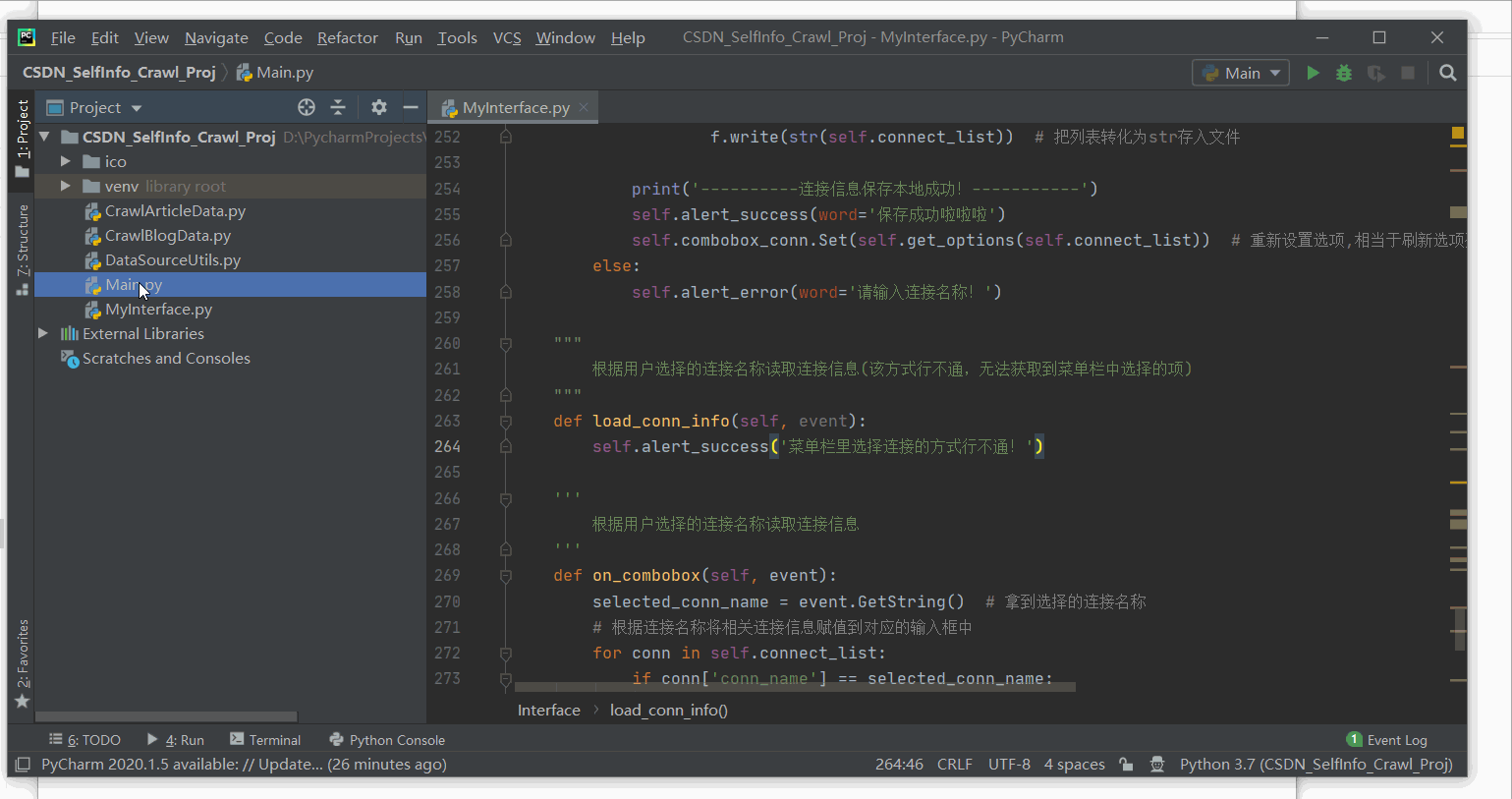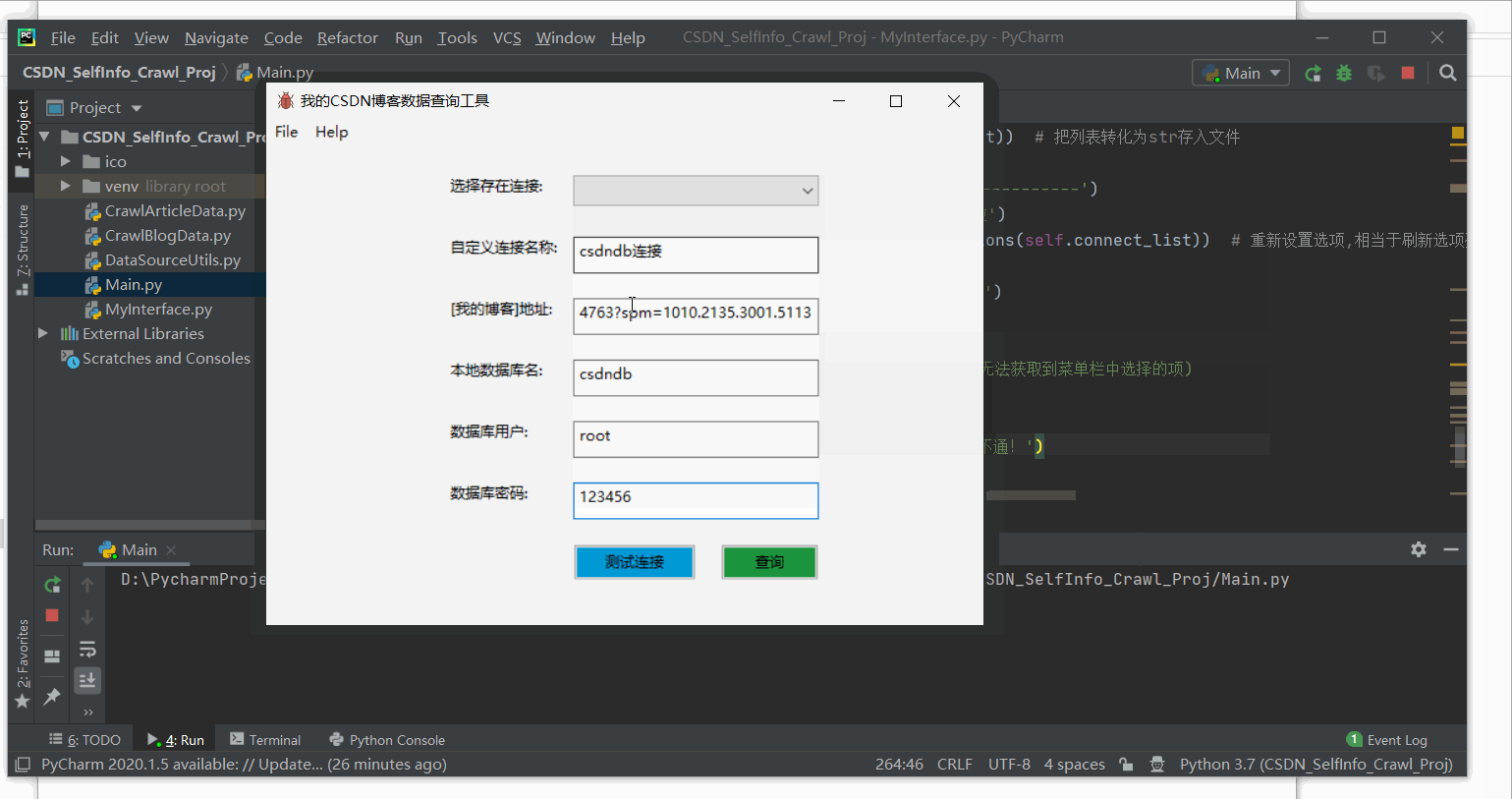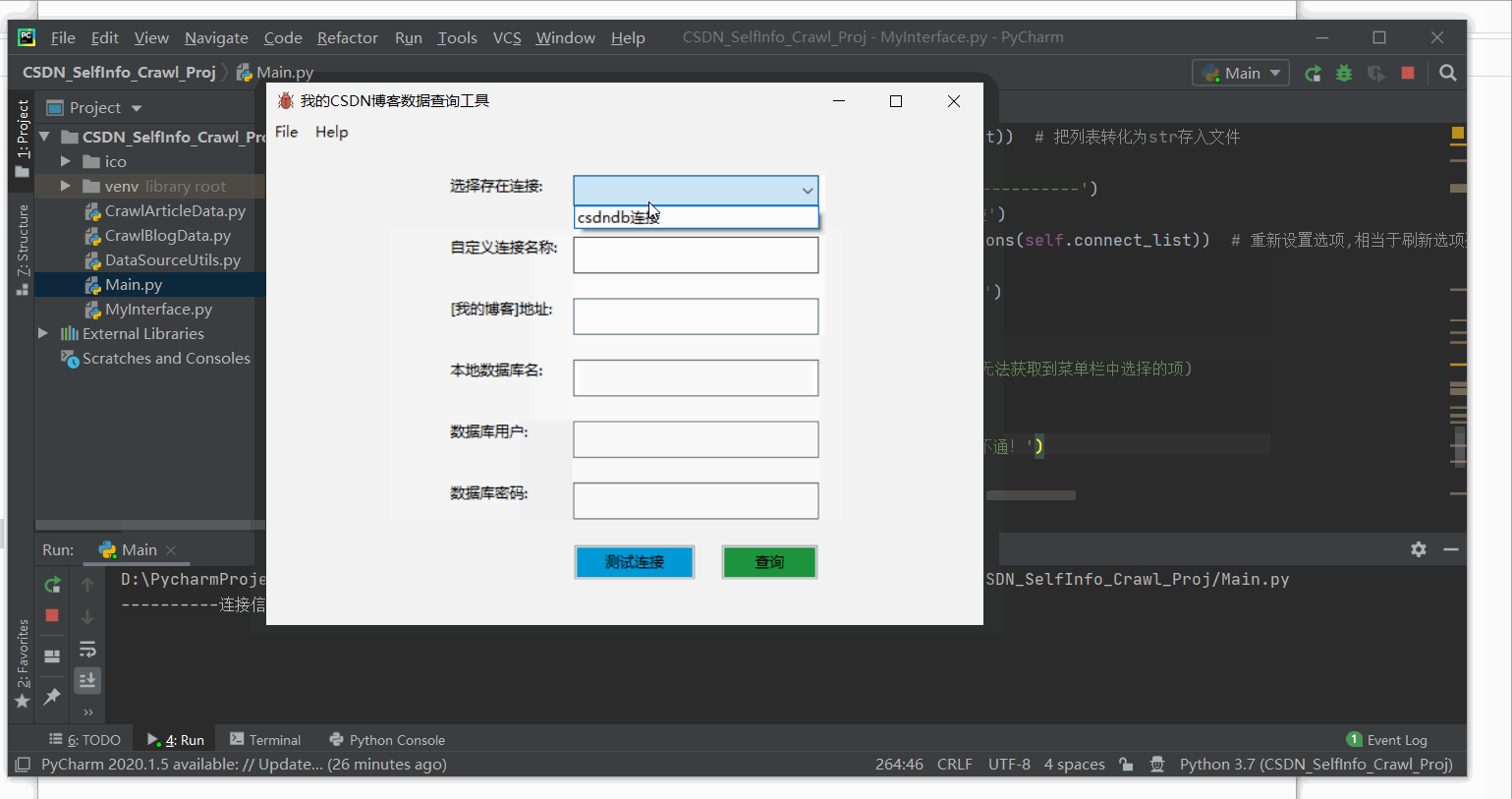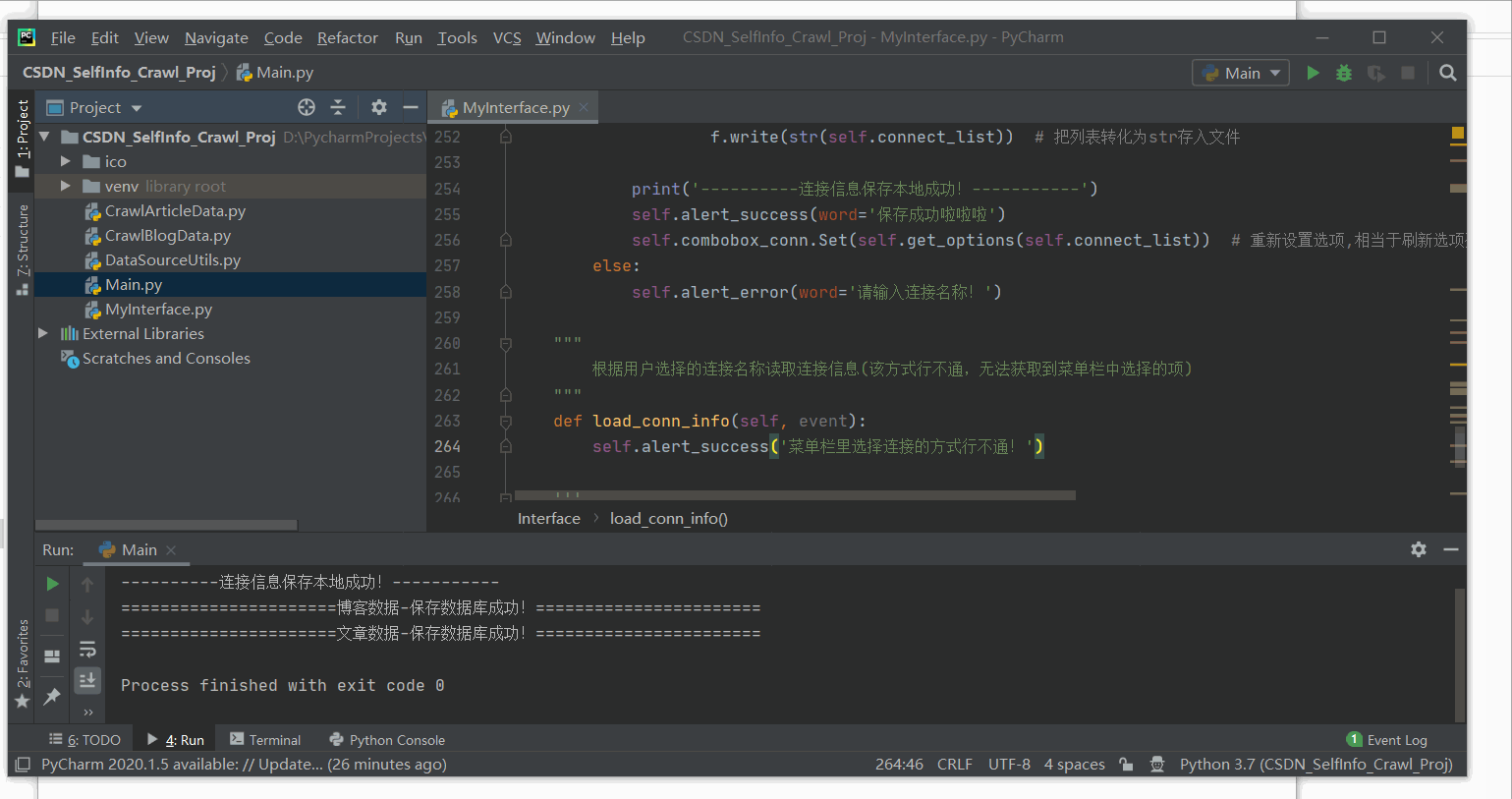
二、涉及模块
- urllib
- bs4下的BeautifulSoup
- wxPython
- pymysql
- re
- time
- webbrowser
- os
三、功能说明
在上一个版本(上一个版本传送门)的基础上,对代码结构进行了调整,同时添加了一些新的功能,添加功能如下:
1. 增加对个人博客文章信息的爬取
- 文章信息表会默认创建到您所输入的本地数据库中
- 爬取的文章相关数据包括:文章id、文章标题、文章类型、文章链接、发布时间、文章浏览量
- 至于对文章数据如何加工后分析,后续会提供我自己使用的分析方法。当然有数据库基础的小伙伴建议可以自行创建视图分析
2. 添加保存连接信息功能
- 连接信息默认会保存在本地磁盘的 d:/blog_connection.txt 文件中
- 保存连接信息的支持使用快捷键 Ctrl + S
- 保存时若存在重名的连接信息,会更新之前的信息(重名是指 自定义的连接名称 重复),否则会直接新增一条连接信息
- 已添加的连接信息,会即时的显示在面板的下拉列表选项中
- 若手动干预连接信息文件d:/blog_connection.txt,可能会导致程序加载报错
四、代码实现
1、入口/启动代码
import wx
from MyInterface import Interface
class MyApp(wx.App):
def OnInit(self):
frame = Interface(None, -1, '我的优快云博客数据查询工具')
frame.Show(True)
return True
app = MyApp(0)
app.MainLoop()
2、GUI界面开发
import os
import wx
import webbrowser as brower
from CrawlArticleData import ArticleData
from CrawlBlogData import BlogData
from DataSourceUtils import DataSourceUtils as dsUtils
"""
图形化界面
"""
class Interface(wx.Frame):
def __init__(self, parent, id, title):
super(Interface, self).__init__(parent, id, title)
# 设置窗口宽高
self.SetSize(wx.Size(600, 450))
# 设置界面的图标
self.SetIcon(wx.Icon('ico/crawl.ico', wx.BITMAP_TYPE_ICO))
# 默认启动后窗口位置为屏幕居中
self.Centre()
self.qt = None
self.link = None
self.save = None
self.select = wx.Menu()
# 绘制面板
self.panel = wx.Panel(self, -1)
w = self.GetSize().width
h = self.GetSize().height
# 向面板添加静态标签
label_combobox_conn = wx.StaticText(self.panel, -1, "选择存在连接:", pos=((w - 300)/2, (h - 300)/2 - 50))
label_conn_name = wx.StaticText(self.panel, -1, "自定义连接名称:", pos=((w - 300)/2, (h - 300)/2))
label_url = wx.StaticText(self.panel, -1, "[我的博客]地址:", pos=((w - 300)/2, (h - 300)/2 + 50))
label_dbname = wx.StaticText(self.panel, -1, "本地数据库名:", pos=((w - 300)/2, (h - 300)/2 + 100))
label_user = wx.StaticText(self.panel, -1, "数据库用户:", pos=((w - 300)/2, (h - 300)/2 + 150))
label_pwd = wx.StaticText(self.panel, -1, "数据库密码:", pos=((w - 300)/2, (h - 300)/2 + 200))
# label_select_conn下拉框
# 先读取本地连接信息列表,将连接信息存入列表属性中
self.connect_list = self.read_local_connect()
self.combobox_conn = wx.ComboBox(self.panel, -1, size=(200, 30), pos=((w - 300) / 2 + 100, (h - 300) / 2 - 50),
choices=self.get_options(self.connect_list),
style=wx.CB_READONLY)
# label_conn_name文本输入框
self.entry_conn_name = wx.TextCtrl(self.panel, -1, size=(200, 30), pos=((w - 300)/2 + 100, (h - 300)/2))
# label_url文本输入框
self.entry_url = wx.TextCtrl(self.panel, -1, size=(200, 30), pos=((w - 300)/2 + 100, (h - 300)/2 + 50))
# label_dbname文本输入框
self.entry_dbname = wx.TextCtrl(self.panel, -1, size=(200, 30), pos=((w - 300)/2 + 100, (h - 300)/2 + 100))
# label_user文本输入框
self.entry_user = wx.TextCtrl(self.panel, -1, size=(200, 30), pos=((w - 300) / 2 + 100, (h - 300) / 2 + 150))
# label_pwd文本输入框
self.entry_pwd = wx.TextCtrl(self.panel, -1, size=(200, 30), pos=((w - 300) / 2 + 100, (h - 300) / 2 + 200))
# 面板中添加按钮
left, top = self.entry_pwd.Position
self.but_test_connect = wx.Button(self.panel, -1, "测试连接", size=(100, 30), pos=(left, top + 50))
self.but_search = wx.Button(self.panel, -1, "查询", size=(80, 30), pos=(left + 120, top + 50))
# 设置按钮的颜色
self.but_test_connect.SetBackgroundColour("#009ad6")
self.but_search.SetBackgroundColour("#1d953f")
# 给按钮绑定事件
self.Bind(wx.EVT_BUTTON, self.on_test_connect, self.but_test_connect)
self.Bind(wx.EVT_BUTTON, self.on_search, self.but_search)
# 给下拉选项添加监听事件
self.Bind(wx.EVT_COMBOBOX, self.on_combobox, self.combobox_conn)
# 设置全局变量
self.url = ''
self.db_name = ''
self.db_user = ''
self.user_pwd = ''
self.conn_name = ''
self.init_ui()
"""
读取本地连接信息文件
"""
@staticmethod
def read_local_connect():
conn_list = []
if os.path.exists('d:/blog_connection.txt'):
with open('d:/blog_connection.txt', 'r', encoding='utf-8') as f:
conn_list = eval(f.read())
return conn_list
"""
创建菜单栏
"""
def init_ui(self):
menubar = wx.MenuBar()
'''设置菜单'''
# file菜单
file = wx.Menu()
# file.Append(101, '&Save Connect', 'Save Connection to Local') # file菜单-选项1
self.save = wx.MenuItem(file, 101, '&Save Connect\tCtrl+S', 'Save Connection to Local')
file.Append(self.save) # file菜单-选项1
file.AppendSeparator() # 分割线
# 设置连接信息二级菜单
options = wx.Menu()
for opt in self.connect_list:
opt = wx.MenuItem(options, 1021, opt['conn_name'], 'Select Connection From Local List')
self.select.Append(opt)
# 给每一个连接选项添加监听事件
self.Bind(wx.EVT_MENU, self.load_conn_info, opt)
self.select.AppendSeparator()
file.Append(102, '&Select Connect', self.select) # file菜单-选项2
file.AppendSeparator()
self.qt = wx.MenuItem(file, 103, '&Quit\tCtrl+Q', 'Quit the Application') # file菜单-选项3
self.qt.SetBitmap(wx.Bitmap('ico/quit.ico', wx.BITMAP_TYPE_ICO)) # 设置退出的icon
file.Append(self.qt)
# help菜单
help = wx.Menu()
self.link = wx.MenuItem(help, 201, '&About', 'About Introduction') # file菜单-选项3
help.Append(self.link)
# 菜单加到菜单栏
menubar.Append(file, '&File')
menubar.Append(help, '&Help')
# 程序中创建菜单栏
self.SetMenuBar(menubar)
# self.Centre()
# 给退出按钮绑定事件
self.Bind(wx.EVT_MENU, self.on_quit, self.qt)
# 给帮助按钮绑定事件
self.Bind(wx.EVT_MENU, self.on_link, self.link)
# 给保存连接按钮绑定事件
self.Bind(wx.EVT_MENU, self.on_save, self.save)
# 显示图形化界面
self.Show()
'''
定义一个消息弹出框的函数
'''
def alert_error(self, word=""):
dlg = wx.MessageDialog(None, word, u"警告", wx.YES_NO)
if dlg.ShowModal() == wx.ID_YES:
# self.Close(True)
pass
dlg.Destroy()
'''
定义一个消息弹出框的函数
'''
def alert_success(self, word=""):
dlg = wx.MessageDialog(None, word, u"提示", wx.YES_NO)
if dlg.ShowModal() == wx.ID_YES:
pass
dlg.Destroy()
'''
测试连接方法
'''
def on_test_connect(self, event, is_alert=True):
# 连接到本地数据库
self.db_name = self.entry_dbname.GetValue()
self.db_user = self.entry_user.GetValue()
self.user_pwd = self.entry_pwd.GetValue()
# 判断,查看用户名和密码名是否为空 ,当密码或用户名为空时会出现会导致出错
if self.db_name and self.db_user and self.user_pwd:
try:
conn = dsUtils.connect_default_host_port(self.db_name, self.db_user, self.user_pwd)
if is_alert: # 只有测试连接的时候才会弹出成功的提示
self.alert_success('连接成功!')
return True
except Exception as e:
print(e)
self.alert_error('连接失败!')
return False
finally:
conn.close() # 关闭连接
else:
self.alert_error(word='存在未填写信息!')
return False
'''
查询方法
'''
def on_search(self, event):
self.url = self.entry_url.GetValue()
if self.url == '':
self.alert_error('URL不能为空!')
return False
flag = self.on_test_connect(event, is_alert=False)
if flag: # 成功连接,则执行查询操作
blog_obj = BlogData(url=self.url
, db_name=self.db_name
, user=self.db_user
, pwd=self.user_pwd)
is_success = blog_obj.main() # 执行博客数据查询与插入
article_obj = ArticleData(url=self.url
, db_name=self.db_name
, user=self.db_user
, pwd=self.user_pwd
, blog_account=blog_obj.get_blog_user().get('blog_account')
, blog_alias=blog_obj.get_blog_user().get('blog_alias'))
is_success2 = article_obj.main()
if is_success and is_success2:
self.alert_success('查询并保存本地数据库成功,可前往查看呦')
else:
self.alert_error('查询出错了!')
'''
退出窗口
'''
def on_quit(self, event):
self.Close()
'''
帮助方法
'''
def on_link(self, event):
brower.open('https://blog.youkuaiyun.com/qq_19314763/article/details/110951204')
'''
保存连接信息到本地
'''
def on_save(self, event):
# 将连接信息赋值到self对象中
self.conn_name = self.entry_conn_name.GetValue()
self.url = self.entry_url.GetValue()
self.db_name = self.entry_dbname.GetValue()
self.db_user = self.entry_user.GetValue()
self.user_pwd = self.entry_pwd.GetValue()
if self.conn_name != '':
flag = False
for conn in self.connect_list:
if conn['conn_name'] == self.conn_name:
flag = True
# 如果已经存在该名称的连接,则进行修改操作
conn['url'] = self.url
conn['db_name'] = self.db_name
conn['db_user'] = self.db_user
conn['user_pwd'] = self.user_pwd
break
if flag is False: # 不存在,则直接新增
with open('d:/blog_connection.txt', 'w', encoding='utf-8') as f:
info_dict = {'conn_name': self.conn_name, 'url': self.url, 'db_name': self.db_name, 'db_user': self.db_user, 'user_pwd': self.user_pwd}
self.connect_list.append(info_dict)
f.write(str(self.connect_list)) # 把列表转化为str存入文件
print('----------连接信息保存本地成功!-----------')
self.alert_success(word='保存成功啦啦啦')
self.combobox_conn.Set(self.get_options(self.connect_list)) # 重新设置选项,相当于刷新选项列表
else:
self.alert_error(word='请输入连接名称!')
"""
根据用户选择的连接名称读取连接信息(该方式行不通,无法获取到菜单栏中选择的项)
"""
def load_conn_info(self, event):
self.alert_success('菜单栏里选择连接的方式行不通!')
'''
根据用户选择的连接名称读取连接信息
'''
def on_combobox(self, event):
selected_conn_name = event.GetString() # 拿到选择的连接名称
# 根据连接名称将相关连接信息赋值到对应的输入框中
for conn in self.connect_list:
if conn['conn_name'] == selected_conn_name:
self.entry_conn_name.SetValue(conn['conn_name'])
self.entry_url.SetValue(conn['url'])
self.entry_dbname.SetValue(conn['db_name'])
self.entry_user.SetValue(conn['db_user'])
self.entry_pwd.SetValue(conn['user_pwd'])
'''
根据连接信息列表,提取出连接信息名称列表,作为下拉框的选项内容
'''
@staticmethod
def get_options(conn_list):
conn_name_list = []
for conn in conn_list:
conn_name_list.append(conn['conn_name'])
return conn_name_list
3、爬取博客信息
import urllib.request as request
import urllib.error as error
import time
from bs4 import BeautifulSoup
import re
from DataSourceUtils import DataSourceUtils as dsUtils
class BlogData:
def __init__(self, url, db_name, user, pwd):
self.url = url
self.db_name = db_name
self.db_user = user
self.user_pwd = pwd
self.account = ''
self.alias = ''
# self.main()
"""
爬取整个HTML页面
"""
def download(self, crawl_url, num_retries=3):
# 设置用户代理
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36',
}
# 设置请求的URL
req = request.Request(crawl_url, headers=headers)
try:
# 开始爬取整个HTML代码
crawl_html = request.urlopen(req).read().decode("utf-8")
# 此处异常用于处理,csdn服务器异常后导致爬取失败
except error.URLError as e:
print("download error:", e.reason)
crawl_html = None
if num_retries > 0:
if hasattr(e, "code") and 500 <= e.code <= 600:
time.sleep(5000) # 主线程睡眠5s后再重新访问,最多访问3次,也就是如果程序开始执行10s后,csdn服务器始终未正常启动,则此次爬取失败
return self.download(crawl_url, num_retries-1)
return crawl_html
"""
解析HTML获取页面上的10组数据
"""
def parse_page(self, page_html):
# 声明一个包含10组key的字典data_dict
data_dict = {'积分': '', '粉丝': '', '获赞': '', '评论': '', '收藏': ''
, '原创': '', '周排名': '', '总排名': '', '访问': '', '等级': ''
, '账号': '', '昵称': ''}
# 开始解析html
soup = BeautifulSoup(page_html, "html.parser")
# 解析class='text-center'的所有<dl>标签列表
# 方式一
# dl_list = soup.find_all(name='div', attrs={'class': re.compile('text-center')})
# 方式二
dl_list = soup.find_all('dl', class_='text-center')
# 遍历dl标签列表,获取到每一个dl标签,将目标数值存入字典data_dict
for dl in dl_list:
# print(dl)
dd_name = dl.select('dd')[0].text # 读取该dl标签的子标签dd的文本内容
dd_title = dl.get('title') # 读取该dl标签的title属性值
for k in data_dict.keys(): # 遍历data_dict字典,将匹配的数值存入字典中
if dd_name == k:
data_dict[k] = dd_title
# 获取账号和昵称信息
self_info_list = soup.find_all('a', id='uid') # 根据id获取a标签元素
self.alias = self_info_list[0].get('title')
self.account = self_info_list[0].select('span')[0].get('username')
data_dict.update({"账号": self.account, "昵称": self.alias})
# data_dict添加爬取时间的信息
data_dict.update({"爬取时间": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())})
return data_dict
"""
判断表是否存在
"""
def table_exists(con, table_name): # 这个函数用来判断表是否存在
sql = "show tables;"
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall('(\'.*?\')', str(tables))
table_list = [re.sub("'", '', each) for each in table_list]
if table_name in table_list:
return 1 # 存在返回1
else:
return 0 # 不存在返回0
'''
将字典数据存入数据库
'''
def save_to_mysql(self, data_obj):
# db = input('请输入本地数据库名:')
# username = input('请输入数据库用户名:')
# password = input('请输入数据库密码:')
# 连接数据库
conn = dsUtils.connect_default_host_port(self.db_name, self.db_user, self.user_pwd)
# 建立游标,用于数据库插入
cursor = conn.cursor()
# # 校验数据库是否存在博客数据记录表
# table_count = table_exists(conn, '优快云_SELF_BLOG_DATA')
# # 如果数据库不存在该表,则创建
# if table_count == 0:
sql_create = """CREATE TABLE IF NOT EXISTS `csdn_self_blog_data` (
`id` bigint NOT NULL AUTO_INCREMENT,
`account` varchar(100) DEFAULT NULL,
`alias` varchar(100) DEFAULT NULL,
`grade` int DEFAULT NULL,
`count_fan` int DEFAULT NULL,
`count_thumb` bigint DEFAULT NULL,
`count_comment` bigint DEFAULT NULL,
`count_star` int DEFAULT NULL,
`count_original` int DEFAULT NULL,
`rank_week` bigint DEFAULT NULL,
`rank_all` bigint DEFAULT NULL,
`count_scan` bigint DEFAULT NULL,
`blog_level` varchar(100) DEFAULT NULL,
`crawl_time` datetime DEFAULT NULL,
`start_hour` int DEFAULT NULL,
`end_hour` int DEFAULT NULL,
`crawl_date` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
"""
cursor.execute(sql_create)
# print('==========表创建完成=========')
# 创建SQL语句并往数据库插入数据
curr_date = time.strftime("%Y-%m-%d", time.localtime())
curr_time = data_obj['爬取时间']
sql_insert = """insert into csdn_self_blog_data(
account, alias, grade, count_fan, count_thumb
,count_comment, count_star, count_original, rank_week, rank_all
,count_scan, blog_level, crawl_time, start_hour, end_hour
,crawl_date)
values( %s, %s, %s, %s, %s
,%s, %s, %s, %s, %s
,%s, %s, %s, %s, %s
,%s)"""
values_list = [data_obj['账号'], data_obj['昵称'], data_obj['积分'], data_obj['粉丝'], data_obj['获赞']
, data_obj['评论'], data_obj['收藏'], data_obj['原创'], data_obj['周排名'], data_obj['总排名']
, data_obj['访问'], data_obj['等级'], curr_time, curr_time[11:13], int(curr_time[11:13]) + 1
, curr_date]
cursor.execute(sql_insert, tuple(values_list))
conn.commit() # 提交请求,不然不会插入数据
conn.close()
print("======================博客数据-保存数据库成功!=======================")
return True
"""
获取用户信息
"""
def get_blog_user(self):
return {'blog_account': self.account, 'blog_alias': self.alias}
"""
主程序
"""
def main(self):
# url = input('请输入您的优快云网站[我的博客]URL地址:')
# url = "https://blog.youkuaiyun.com/qq_19314763?spm=1010.2135.3001.5113" # 使用自己的优快云[我的博客]的URL地址
# 1、获取整个HTML
html = self.download(self.url)
# 2、解析HTML获取目标数据,并存储到字典中
dict_obj = self.parse_page(html)
# 打印字典信息,查看效果使用
# for key, value in dict_obj.items():
# print(key + ' = ' + value)
# 3、将字典数据存入MySQL数据库
return self.save_to_mysql(dict_obj)
4、爬取文章信息
import urllib.request as request
import urllib.error as error
import time
from bs4 import BeautifulSoup
import re
from DataSourceUtils import DataSourceUtils as dsUtils
"""
博客文章爬取类
"""
class ArticleData:
def __init__(self, url, db_name, user, pwd, blog_account, blog_alias):
self.url = url
self.db_name = db_name
self.db_user = user
self.user_pwd = pwd
self.blog_account = blog_account
self.blog_alias = blog_alias
# self.main()
"""
爬取整个HTML页面
"""
def download(self, crawl_url, num_retries=3):
# 设置用户代理
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36',
}
# 设置请求的URL
req = request.Request(crawl_url, headers=headers)
try:
# 开始爬取整个HTML代码
crawl_html = request.urlopen(req).read().decode("utf-8")
# 此处异常用于处理,csdn服务器异常后导致爬取失败
except error.URLError as e:
print("download error:", e.reason)
crawl_html = None
if num_retries > 0:
if hasattr(e, "code") and 500 <= e.code <= 600:
time.sleep(5000) # 主线程睡眠5s后再重新访问,最多访问3次,也就是如果程序开始执行10s后,csdn服务器始终未正常启动,则此次爬取失败
return self.download(crawl_url, num_retries-1)
return crawl_html
"""
解析HTML获取页面的博客文章数据
"""
def parse_page(self, page_html):
# 声明一个空列表data_list
data_list = []
# 开始解析html
soup = BeautifulSoup(page_html, "html.parser")
# 解析class='article-item-box'的所有<div>标签列表
article_item_box_list = soup.find_all('div', class_='article-item-box')
for item in article_item_box_list:
article_id = item.get('data-articleid')
a_tag = item.select('a')[0]
article_url = a_tag.get('href')
# print(a_tags[0].select('span')[0].text) # soup获取子元素方式1
article_type = a_tag.span.text # soup获取子元素方式2
article_title = a_tag.text.replace(' ', '').replace('\n', '').replace(article_type, '')
info = item.select('div')[0].select('span')
publish_time = info[0].text
read_num = info[1].text
item_dict = {}
item_dict.update({'article_id': article_id})
item_dict.update({'article_title': article_title})
item_dict.update({'article_type': article_type})
item_dict.update({'article_url': article_url})
item_dict.update({'publish_time': publish_time})
item_dict.update({'read_num': read_num})
data_list.append(item_dict)
return data_list
"""
判断表是否存在
"""
def table_exists(con, table_name): # 这个函数用来判断表是否存在
sql = "show tables;"
con.execute(sql)
tables = [con.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'", '', each) for each in table_list]
if table_name in table_list:
return 1 # 存在返回1
else:
return 0 # 不存在返回0
'''
将data_list列表数据存入数据库
'''
def save_to_mysql(self, data_list):
# 连接数据库
conn = dsUtils.connect_default_local()
# 建立游标,用于数据库插入
cursor = conn.cursor()
# 如果表不存在,先创建表
sql_create = """CREATE TABLE IF NOT EXISTS `csdn_blog_article_data` (
`id` bigint NOT NULL AUTO_INCREMENT,
`account` varchar(100) DEFAULT NULL,
`alias` varchar(100) DEFAULT NULL,
`article_id` bigint DEFAULT NULL,
`article_title` varchar(200) DEFAULT NULL,
`article_type` varchar(50) DEFAULT NULL,
`article_url` varchar(200) DEFAULT NULL,
`publish_time` varchar(32) DEFAULT NULL,
`read_num` int DEFAULT NULL,
`start_hour` int DEFAULT NULL,
`end_hour` int DEFAULT NULL,
`crawl_date` date DEFAULT NULL,
`crawl_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
"""
cursor.execute(sql_create)
# 遍历列表,分别执行插入操作
for dict_obj in data_list:
self.insert_to_db(cursor, dict_obj)
conn.commit() # 提交请求,不然不会插入数据
dsUtils.close(cursor, conn)
print("======================文章数据-保存数据库成功!=======================")
return True
"""
将字典数据插入数据库
"""
def insert_to_db(self, cursor, data_obj):
# 创建SQL语句并往数据库插入数据
curr_date = time.strftime("%Y-%m-%d", time.localtime())
curr_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
start_hour = curr_time[11:13]
end_hour = int(start_hour) + 1
sql_insert = """insert into csdn_blog_article_data(
account, alias, article_id, article_title
,article_type, article_url, publish_time, read_num
,start_hour, end_hour, crawl_date, crawl_time)
values( %s, %s, %s, %s
,%s, %s, %s, %s
,%s, %s, %s, %s)"""
values_list = [self.blog_account, self.blog_alias, data_obj['article_id'], data_obj['article_title']
, data_obj['article_type'], data_obj['article_url'], data_obj['publish_time'], data_obj['read_num']
, start_hour, end_hour, curr_date, curr_time]
cursor.execute(sql_insert, tuple(values_list))
"""
主程序
"""
def main(self):
# url = input('请输入您的优快云网站[我的博客]URL地址:')
# url = "https://blog.youkuaiyun.com/qq_19314763?spm=1010.2135.3001.5113" # 使用自己的优快云[我的博客]的URL地址
# 1、获取整个HTML
html = self.download(self.url)
# 2、解析HTML获取目标数据,并存储到列表中
dict_list = self.parse_page(html)
# 3、将字典数据存入MySQL数据库
return self.save_to_mysql(dict_list)
# 单独测试
# url = 'https://blog.youkuaiyun.com/qq_19314763?spm=1011.2124.3001.5113'
# db_name = 'csdndb'
# user = 'root'
# user_pwd = '123456'
# is_success = ArticleData(url, db_name, user, user_pwd, 'qq_19314763', '迟到_啦')
# print(is_success)
5、数据源工具类
import pymysql
"""
数据源工具类
"""
class DataSourceUtils:
@staticmethod
def connect_default_local():
conn = pymysql.connect(
host="127.0.0.1",
port=3306, # 端口号
user='root', # 数据库用户
password='123456', # 数据库密码
database='csdndb' # 要连接的数据库名称
)
return conn
@staticmethod
def connect_default_host_port(db_name, db_user, user_pwd):
conn = pymysql.connect(
host='127.0.0.1',
port=3306, # 端口号
user=db_user, # 数据库用户
password=user_pwd, # 数据库密码
database=db_name # 要连接的数据库名称
)
return conn
@staticmethod
def connect_default_port(host, db_name, db_user, user_pwd):
conn = pymysql.connect(
host=host,
port=3306, # 端口号
user=db_user, # 数据库用户
password=user_pwd, # 数据库密码
database=db_name # 要连接的数据库名称
)
return conn
@staticmethod
def connect_all_params(host, port, db_name, db_user, user_pwd):
conn = pymysql.connect(
host=host,
port=port, # 端口号
user=db_user, # 数据库用户
password=user_pwd, # 数据库密码
database=db_name # 要连接的数据库名称
)
return conn
@staticmethod
def close(cursor, conn):
cursor.close()
conn.close()
6、完整代码
前往下载



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











