





 本文讲述了在使用PyTorch训练数据集后,遇到param文件显示问题的原因——版本冲突。通过更新torch和torchvision到1.10.2版本,解决了文件格式问题,并详细说明了如何重新转换为ONNX和bin文件。
本文讲述了在使用PyTorch训练数据集后,遇到param文件显示问题的原因——版本冲突。通过更新torch和torchvision到1.10.2版本,解决了文件格式问题,并详细说明了如何重新转换为ONNX和bin文件。
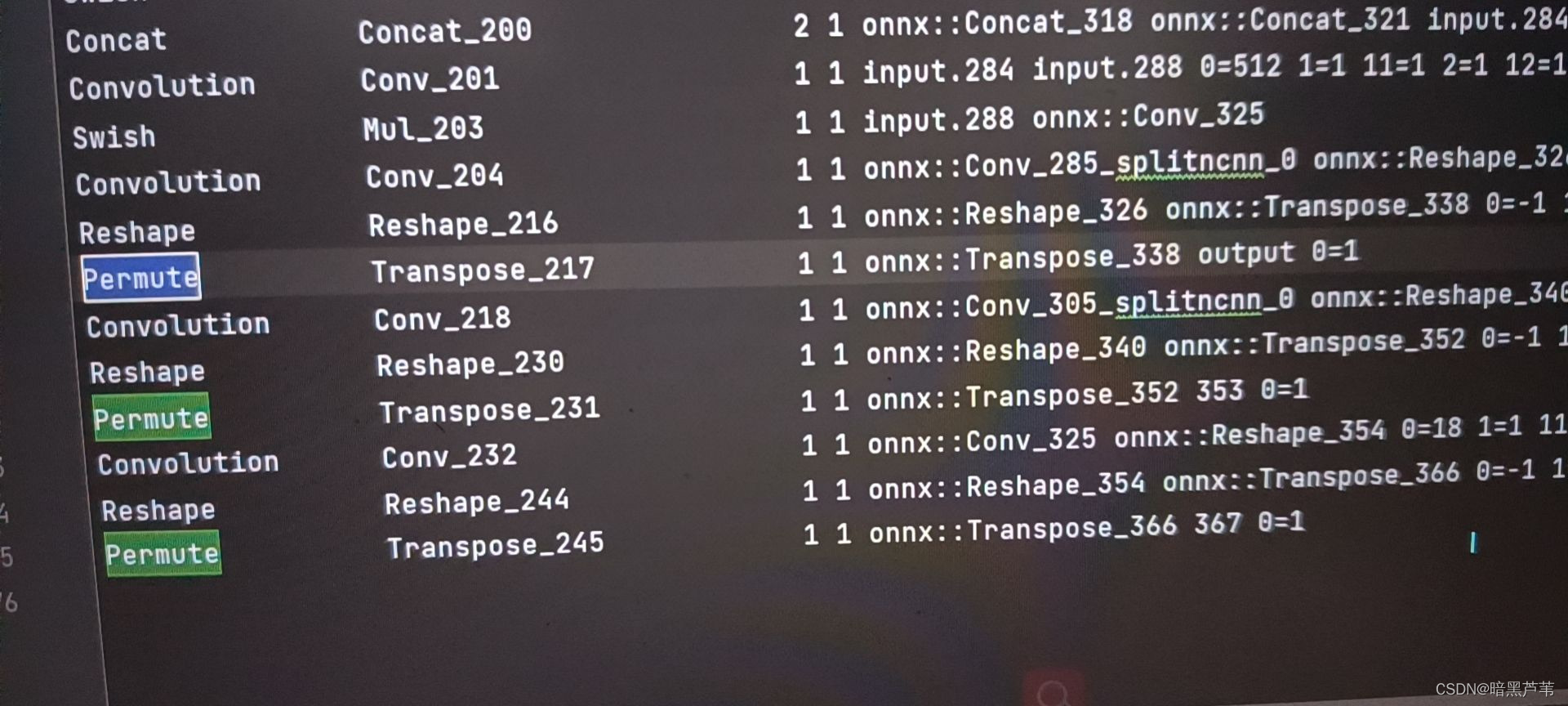
如图,我在我训练自己数据集后转换为param和bin文件后param文件如图,右侧第三列本该为数字确出现了如图的问题;
原因:pytorch版本的问题
解决方法:pip install torch==1.10.2 (torch版本更换后,也需要更换对应版本的torchvision)
然后再由pt文件重新转为onnx文件,再转为bin和param文件后,param文件就正常了

如图,我在我训练自己数据集后转换为param和bin文件后param文件如图,右侧第三列本该为数字确出现了如图的问题;
原因:pytorch版本的问题
解决方法:pip install torch==1.10.2 (torch版本更换后,也需要更换对应版本的torchvision)
然后再由pt文件重新转为onnx文件,再转为bin和param文件后,param文件就正常了
 1642
5912
351
2519
1642
5912
351
2519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























