




 本文通过数据分析揭示了全球多个国家的食品平均糖分、盐分含量及食品添加剂使用情况,利用Python的Pandas库进行数据清洗、统计和可视化,展示了各国食品营养成分的差异。
本文通过数据分析揭示了全球多个国家的食品平均糖分、盐分含量及食品添加剂使用情况,利用Python的Pandas库进行数据清洗、统计和可视化,展示了各国食品营养成分的差异。
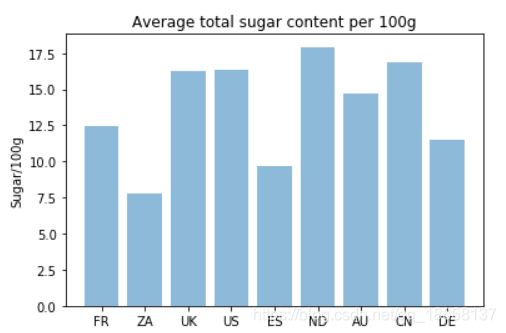
First check:how much sugar a number of countries take in
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据并将 countries数据全部转为小写 .str.lower() 方法
world_food_facts = pd.read_csv('FoodFacts.csv')
world_food_facts.countries = world_food_facts.countries.str.lower()
# 取平均值
def mean(l):
return float(sum(l)) / len(l)
# 去掉缺失值
world_sugars = world_food_facts[world_food_facts.sugars_100g.notnull()]
#print(world_sugars)
# 只统计特定国家,转为 list 数据结构,因为有些国家名字不同,用list容易相加,方便最后统计平均值
def return_sugars(country):
return world_sugars[world_sugars.countries == country].sugars_100g.tolist()
# Get list of sugars per 100g for some countries
fr_sugars = return_sugars('france') + return_sugars('en:fr')
za_sugars = return_sugars('south africa')
uk_sugars = return_sugars('united kingdom') + return_sugars('en:gb')
us_sugars = return_sugars('united states') + return_sugars('en:us') + return_sugars('us')
sp_sugars = return_sugars('spain') + return_sugars('españa') + return_sugars('en:es')
nd_sugars = return_sugars('netherlands') + return_sugars('holland')
au_sugars = return_sugars('australia') + return_sugars('en:au')
cn_sugars = return_sugars('canada') + return_sugars('en:cn')
de_sugars = return_sugars('germany')
countries = ['FR', 'ZA', 'UK', 'US', 'ES', 'ND', 'AU', 'CN', 'DE']
# 取均值
sugars_l = [mean(fr_sugars),
mean(za_sugars),
mean(uk_sugars),
mean(us_sugars),
mean(sp_sugars),
mean(nd_sugars),
mean(au_sugars),
mean(cn_sugars),
mean(de_sugars)]
# 可视化
y_pos = np.arange(len(countries))
plt.bar(y_pos, sugars_l, align='center', alpha=0.5)
plt.title('Average total sugar content per 100g')
plt.xticks(y_pos, countries)
plt.ylabel('Sugar/100g')
plt.show()
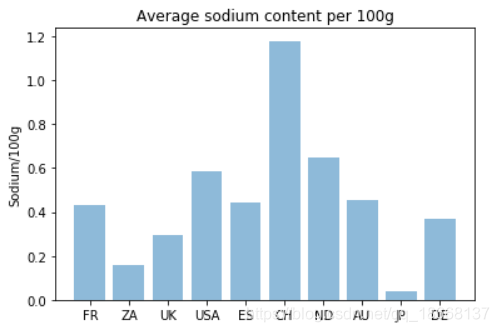
second check:how much salt do we eat
ps,最后将结果转为Series并对values进行排序 sort_values()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
world_food_facts = pd.read_csv('FoodFacts.csv')
world_food_facts.countries = world_food_facts.countries.str.lower()
def mean(l):
return float(sum(l)) / len(l)
world_sodium = world_food_facts[world_food_facts.sodium_100g.notnull()]
def return_sodium(country):
return world_sodium[world_sodium.countries == country].sodium_100g.tolist()
# Get list of sodium per 100g for some countries
fr_sodium = return_sodium('france') + return_sodium('en:fr')
za_sodium = return_sodium('south africa')
uk_sodium = return_sodium('united kingdom') + return_sodium('en:gb')
us_sodium = return_sodium('united states') + return_sodium('en:us') + return_sodium('us')
sp_sodium = return_sodium('spain') + return_sodium('españa') + return_sodium('en:es')
ch_sodium = return_sodium('china')
nd_sodium = return_sodium('netherlands') + return_sodium('holland')
au_sodium = return_sodium('australia') + return_sodium('en:au')
jp_sodium = return_sodium('japan') + return_sodium('en:jp')
de_sodium = return_sodium('germany')
countries = ['FR', 'ZA', 'UK', 'USA', 'ES', 'CH', 'ND', 'AU', 'JP', 'DE']
sodium_l = [mean(fr_sodium),
mean(za_sodium),
mean(uk_sodium),
mean(us_sodium),
mean(sp_sodium),
mean(ch_sodium),
mean(nd_sodium),
mean(au_sodium),
mean(jp_sodium),
mean(de_sodium)]
y_pos = np.arange(len(countries))
s1 = pd.Series(sodium_l,index = countries)
print(s1.sort_values())
plt.bar(y_pos, sodium_l, align='center', alpha=0.5)
plt.title('Average sodium content per 100g')
plt.xticks(y_pos, countries)
plt.ylabel('Sodium/100g')
plt.show()
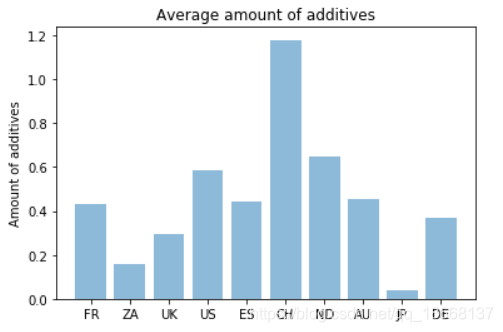
Third check: how many additives r in our food
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
world_food_facts = pd.read_csv('FoodFacts.csv')
world_food_facts.countries = world_food_facts.countries.str.lower()
def mean(l):
return float(sum(l)) / len(l)
world_additives = world_food_facts[world_food_facts.additives_n.notnull()]
def return_additives(country):
return world_additives[world_additives.countries == country].additives_n.tolist()
# Get list of additives amounts for some countries
fr_additives = return_additives('france') + return_additives('en:fr')
za_additives = return_additives('south africa')
uk_additives = return_additives('united kingdom') + return_additives('en:gb')
us_additives = return_additives('united states') + return_additives('en:us') + return_additives('us')
sp_additives = return_additives('spain') + return_additives('españa') + return_additives('en:es')
ch_additives = return_additives('china')
nd_additives = return_additives('netherlands') + return_additives('holland')
au_additives = return_additives('australia') + return_additives('en:au')
jp_additives = return_additives('japan') + return_additives('en:jp')
de_additives = return_additives('germany')
countries = ['FR', 'ZA', 'UK', 'US', 'ES', 'CH', 'ND', 'AU', 'JP', 'DE']
additives_l = [mean(fr_additives),
mean(za_additives),
mean(uk_additives),
mean(us_additives),
mean(sp_additives),
mean(ch_additives),
mean(nd_additives),
mean(au_additives),
mean(jp_additives),
mean(de_additives)]
y_pos = np.arange(len(countries))
plt.bar(y_pos, sodium_l, align='center', alpha=0.5)
plt.title('Average amount of additives')
plt.xticks(y_pos, countries)
plt.ylabel('Amount of additives')
plt.show()
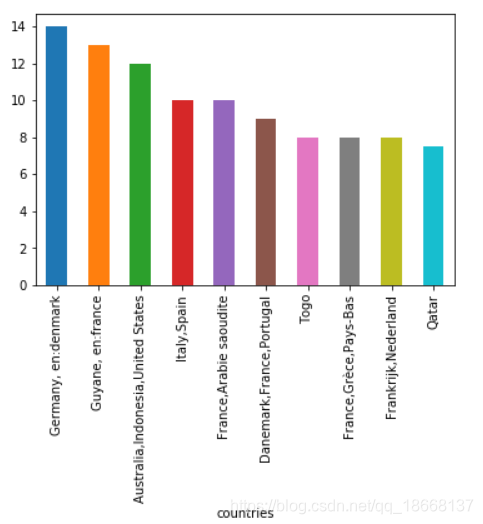
Final,use groupby functionality in pandas to make analysis simply
import zipfile
import os
import pandas as pd
import matplotlib.pyplot as plt
def unzip(zip_filepath, dest_path):
"""
解压zip文件
"""
with zipfile.ZipFile(zip_filepath) as zf:
zf.extractall(path=dest_path)
# 获取数据文件名
def get_dataset_filename(zip_filepath):
with zipfile.ZipFile(zip_filepath) as zf:
return zf.namelist()[0]
def run_main():
"""
主函数
"""
# 声明变量
dataset_path = './data' # 数据集路径
zip_filename = 'open-food-facts.zip' # zip文件名
zip_filepath = os.path.join(dataset_path, zip_filename) # zip文件路径
dataset_filename = get_dataset_filename(zip_filepath) # 数据集文件名(在zip中)
dataset_filepath = os.path.join(dataset_path, dataset_filename) # 数据集文件路径
print('解压zip...', end='')
unzip(zip_filepath, dataset_path)
print('完成.')
# 读取数据
data = pd.read_csv(dataset_filepath, usecols=['countries', 'additives_n'])
# 分析各国家食物中的食品添加剂种类个数
# 1. 数据清理
# 去除缺失数据
data.dropna(inplace=True)
data['countries_en'] = data['countries_en'].str.lower()
# 2. 数据分组统计
country_additives = data['additives_n'].groupby(data['countries_en']).mean()
print(country_additives)
# 3. 按值从大到小排序
result = country_additives[country_additives > 0].sort_values(ascending=False)
# 4. pandas可视化top10
result.iloc[:10].plot.bar()
plt.show()
# 5. 保存处理结果
result.to_csv('./country_additives.csv')
# 删除解压数据,清理空间
if os.path.exists(dataset_filepath):
os.remove(dataset_filepath)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









