




在EXCEL中快速找出在表格中重复的数据,并将数据显示出来的方法如下:
1.打开excel文件,选中需要核对数据的一列。
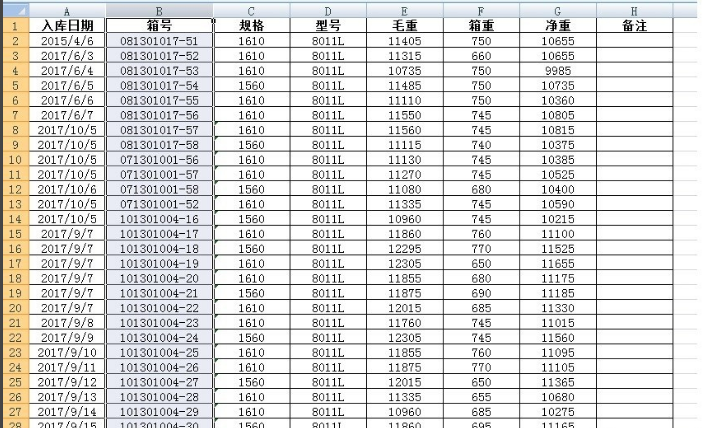
2.点击开始选项卡-然后点击-条件格式,弹出的菜单中点击-突出显示单元格规则。
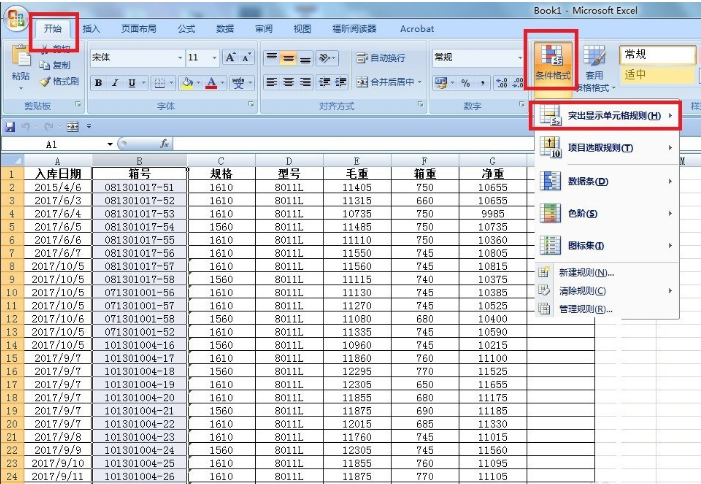
3.在弹出的菜单中选择重复值

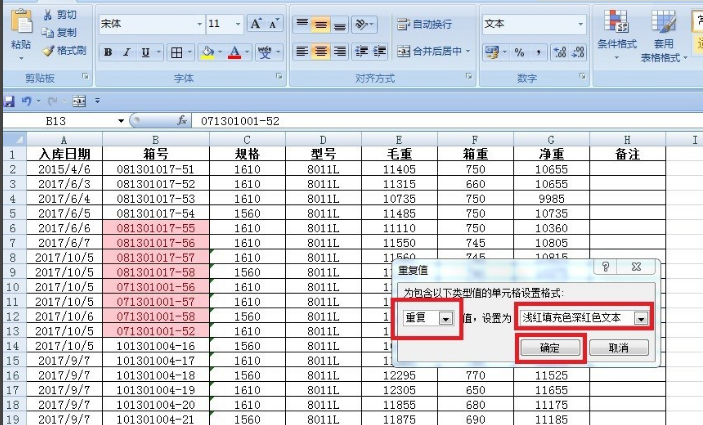
4.在弹出的对话框中选择[重复值]设置为[浅红色填充深红色文本],根据自己喜好设置,点击确定之后深红色部分为有重复的数据。
5.如果在对话框中选择[唯一]值,设置[黄色填充深黄色文本],点击确定之后,黄色填充的数据为唯一的数值。

 Excel快速查找重复数据技巧
Excel快速查找重复数据技巧
 本文介绍了一种在Excel中高效查找重复数据的方法,通过使用条件格式中的突出显示单元格规则,可以轻松地将重复数据标记出来。只需几个简单的步骤,即可让数据一目了然。
本文介绍了一种在Excel中高效查找重复数据的方法,通过使用条件格式中的突出显示单元格规则,可以轻松地将重复数据标记出来。只需几个简单的步骤,即可让数据一目了然。
在EXCEL中快速找出在表格中重复的数据,并将数据显示出来的方法如下:
1.打开excel文件,选中需要核对数据的一列。
2.点击开始选项卡-然后点击-条件格式,弹出的菜单中点击-突出显示单元格规则。
3.在弹出的菜单中选择重复值
4.在弹出的对话框中选择[重复值]设置为[浅红色填充深红色文本],根据自己喜好设置,点击确定之后深红色部分为有重复的数据。
5.如果在对话框中选择[唯一]值,设置[黄色填充深黄色文本],点击确定之后,黄色填充的数据为唯一的数值。
 980
1948
3万+
980
1948
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























