







 本文介绍如何使用Python的lxml库中的XPath功能进行网页数据抓取,包括基础操作如提取文本和属性,进阶操作如定位特定元素,以及实际案例应用,通过爬取软科中国两岸四地大学排名网站来演示数据提取、处理和保存流程。
本文介绍如何使用Python的lxml库中的XPath功能进行网页数据抓取,包括基础操作如提取文本和属性,进阶操作如定位特定元素,以及实际案例应用,通过爬取软科中国两岸四地大学排名网站来演示数据提取、处理和保存流程。
1.基础操作
from lxml import etree
html1 = '''
<div>
<ul class='first-ul'>
<li class='first-li'>
<a href='http://www.baidu.com'>baidu</a>
<a href='http://www.163.com'>netease</a>
</li>
</ul>
</div>
'''
#print(html1)
etree_html = etree.HTML(html1) #自动补全网页格式,并解析为xpath能解析的命令
result = etree.tostring(etree_html) #查看自动补全后的网页
#print(etree_html)
#print(result)
"""
/ 提取父节点
// 提取子孙节点
.. 提取父亲节点
"""
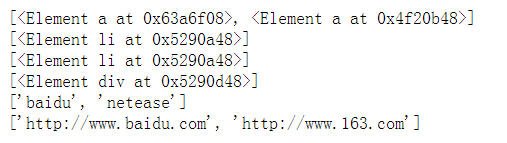
result_0 = etree_html.xpath('//ul//a') #查找ul的间接子孙节点a
result_1 = etree_html.xpath('//li[@class="first-li"]') #查找class为first_li的节点
result_2 = etree_html.xpath('//ul/li') #查找ul下的直接子节点li
result_3 = etree_html.xpath('//ul/..') #查找ul的父节点div
result_4 = etree_html.xpath('//ul//a/text()') #提取文本信息
result_5 = etree_html.xpath('//ul//a/@href') #提取属性信息
print(result_0)
print(result_1)
print(result_2)
print(result_3)
print(result_4)
print(result_5)
2.进阶操作
result_6 = etree_html.xpath('//ul/li[2]/a/@href') #找ul内第2个li
result_7 = etree_html.xpath('//ul/li[last()-1]/a/@href') #找倒数第二个
result_8 = etree_html.xpath('//*[contains(@class,"first")]') #找class属性中包含first的
result_9 = etree_html.xpath('//*[starts-with(@class,"first")]') #找class以first开头的
print(result_6)
print(result_7)
print(result_8)
print(result_9)

3.应用举例
以爬取网页http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html《软科中国两岸四地大学排名 2019》为例
步骤说明:
(1)请求网页
(2)解析网页
(3)保存数据
import requests
import re
import csv
from lxml import etree
#请求网页开始
url = 'http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html'
ua = {'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}
resp = requests.get(url,headers = ua)
print(resp.status_code)
#print(resp.text) #直接打印文本
print(resp.content.decode('utf-8')) #二进制编码 再转为utf-8编码
html = resp.content.decode('utf-8')
#请求网页结束
#解析网页开始
e_html = etree.HTML(html)
#1.提取标题
title = e_html.xpath('//title/text()')
#2.提取大学排名表
university_index = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[1]/text()')
#3.提取大学名
university_name = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[2]/a/div/text()')
#4.提取地区
university_location = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[3]/text()')
#5.提取总分
university_score = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[4]/text()')
#6 提取其他分数
university_score_other = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[@class="hidden-xs"]/text()')
#解析网页结束
#保存数据开始
#存入txt文件
list_university=[]
for i in range(100):
d1 = {
'排名':university_index[i],
'大学名称':university_name[i],
'区域':university_location[i],
'总分':university_score[i],
'其他评分':university_score_other[i*7:i*7+7]
}
list_university.append(d1)
#print(list_university)
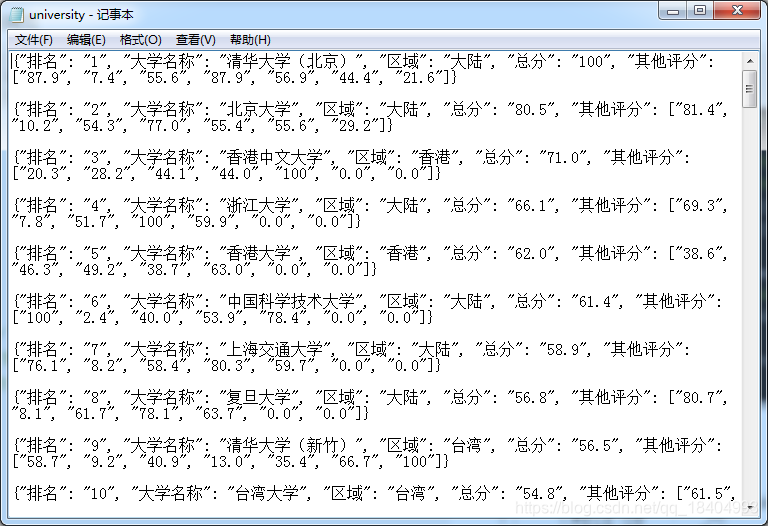
with open(r'C:\Users\HP\Desktop\university.txt','a',encoding='utf-8') as df:
for one in list_university:
df.write(json.dumps(one,ensure_ascii=False)+'\n\n')
#存入csv
#剥离其他评分
dict_university_new=[]
for i in list_university:
temp={
'排名':i['排名'],
'大学名称':i['大学名称'],
'区域':i['区域'],
'总分':i['总分'],
'研究生比例':i['其他评分'][0],
'留学生比例':i['其他评分'][1],
'师生比':i['其他评分'][2],
'博士学位授权总量':i['其他评分'][3],
'博士学位授权师均':i['其他评分'][4],
'校友获奖总量':i['其他评分'][5],
'校友获奖生均':i['其他评分'][6]
}
dict_university_new.append(temp)
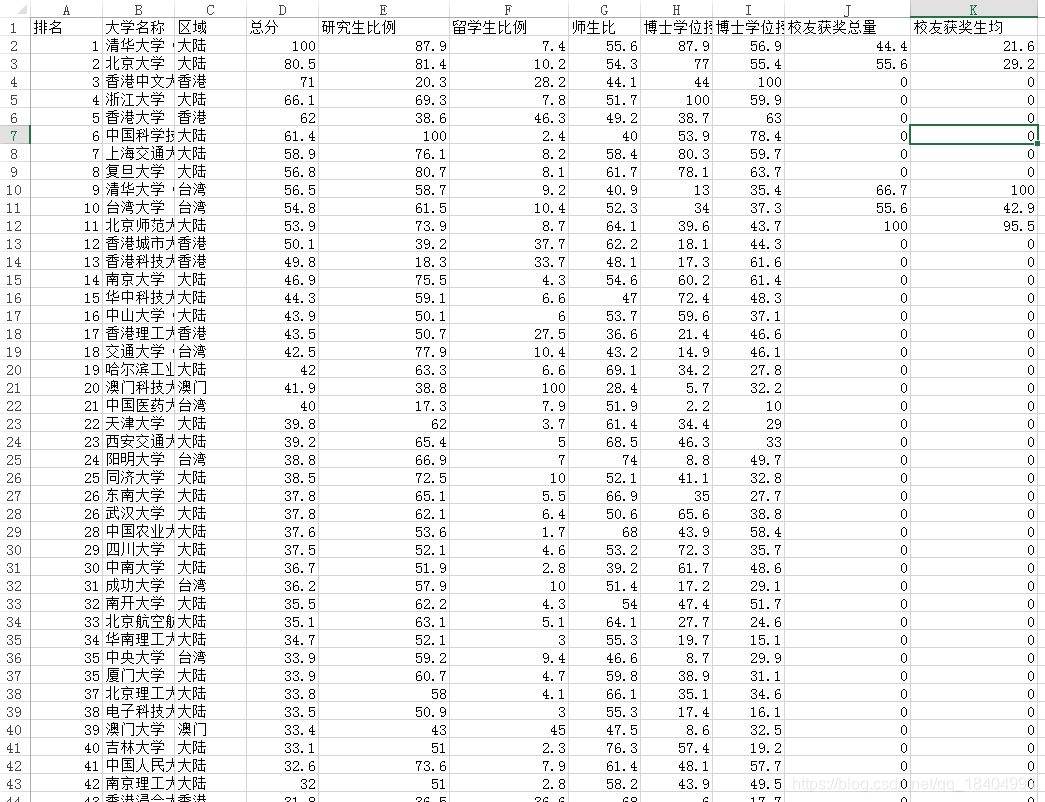
with open(r'C:\Users\HP\Desktop\university.csv','a',encoding='gbk',newline='') as cf:
writer = csv.DictWriter(cf,fieldnames = ['排名','大学名称','区域','总分','研究生比例','留学生比例','师生比','博士学位授权总量','博士学位授权师均','校友获奖总量','校友获奖生均'])
writer.writeheader()
writer.writerows(dict_university_new)
#保存数据结束
结果:
4.模块化改善代码
import requests
import re
import csv
from lxml import etree
import time
#请求页面
def request_pages(urls):
ua = {'User-Agent':'User-Agent:Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'}
resp = requests.get(url,headers = ua)
print(resp.status_code)
#print(resp.text) #直接打印文本
#print(resp.content.decode('utf-8')) #二进制编码 再转为gbk编码
html = resp.content.decode('utf-8')
return html
#解析页面
def decode_pages(html):
e_html = etree.HTML(html)
#1.提取标题
title = e_html.xpath('//title/text()')
#2.提取大学排名表
university_index = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[1]/text()')
#3.提取大学名
university_name = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[2]/a/div/text()')
#4.提取地区
university_location = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[3]/text()')
#5.提取总分
university_score = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[4]/text()')
#6 提取其他分数
university_score_other = e_html.xpath('//div[@class="news-text"]//tbody/tr/td[@class="hidden-xs"]/text()')
#存入列表
list_university=[]
for i in range(len(university_index)):
d1 = {
'排名':university_index[i],
'大学名称':university_name[i],
'区域':university_location[i],
'总分':university_score[i],
'其他评分':university_score_other[i*7:i*7+7]
}
list_university.append(d1)
print("解析成功:%s"%(title[0]))
return list_university,title
#保存txt
def save_to_txt(list_university,title):
with open(r'C:\Users\HP\Desktop\{}.txt'.format(title[0].strip()),'a',encoding='utf-8') as df:
for one in list_university:
df.write(json.dumps(one,ensure_ascii=False)+'\n\n')
#保存csv
def save_to_csv(list_university,title):
#剥离其他评分
dict_university_new=[]
for i in list_university:
temp={
'排名':i['排名'],
'大学名称':i['大学名称'],
'区域':i['区域'],
'总分':i['总分'],
'研究生比例':i['其他评分'][0],
'留学生比例':i['其他评分'][1],
'师生比':i['其他评分'][2],
'博士学位授权总量':i['其他评分'][3],
'博士学位授权师均':i['其他评分'][4],
'校友获奖总量':i['其他评分'][5],
'校友获奖生均':i['其他评分'][6]
}
dict_university_new.append(temp)
with open(r'C:\Users\HP\Desktop\{}.csv'.format(title[0].strip()),'w',encoding='gbk',newline='') as cf:
writer = csv.DictWriter(cf,fieldnames = ['排名','大学名称','区域','总分','研究生比例','留学生比例','师生比','博士学位授权总量','博士学位授权师均','校友获奖总量','校友获奖生均'])
writer.writeheader()
writer.writerows(dict_university_new)
if __name__ == '__main__':
#注意:2015以及以前的网页结构发生变化,需要修改解析规则
for i in range(2016,2020):
url = "http://www.zuihaodaxue.com/Greater_China_Ranking%d_0.html"%(i)
#url = 'http://www.zuihaodaxue.com/Greater_China_Ranking2019_0.html'
time.sleep(2) #间隔为2s
html = request_pages(url)
list_university = decode_pages(html)
#print(list_university)
save_to_txt(list_university[0],list_university[1])
save_to_csv(list_university[0],list_university[1])


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









