




 本文介绍了Stacking模型融合的方法,通过5折交叉验证训练基础模型,将预测值作为新特征输入到第二层模型中。讨论了n_jobs、n_estimators、max_depth等参数,并强调了特征重要性和模型多样性对提升评分的重要性。
本文介绍了Stacking模型融合的方法,通过5折交叉验证训练基础模型,将预测值作为新特征输入到第二层模型中。讨论了n_jobs、n_estimators、max_depth等参数,并强调了特征重要性和模型多样性对提升评分的重要性。
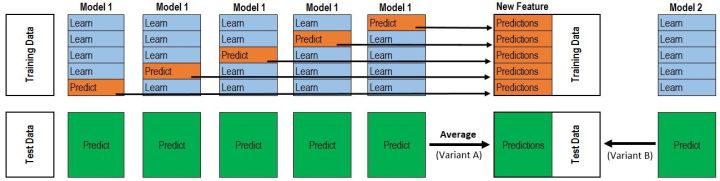
第一层:
训练数据:通过5-fold切分数据集分别训练和测试,将model1的预测值保存为P1,作为model2的训练数据。
测试数据:通过每次训练的model1预测所有的测试数据,然后取平均值得到T1。
如果第一层有三个模型,则得到预测值矩阵(P1, P2, P3)和 预测值矩阵 (T1, T2, T3)。
第二层:
预测值矩阵(P1, P2, P3)作为训练集,预测值矩阵 (T1, T2, T3)作为测试集。
import pandas as pd
import numpy as np
import re
import sklearn
import xgboost as xgb
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline # 使用jupyter notebook
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
# Going to use these 5 base models for the stacking
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
from sklearn.model_selection import KFold
# Some useful parameters which will come in handy later on
ntrain = train.shape[0]
ntest = test.shape[0]
SEED = 0 # for reproducibility
NFOLDS = 5 # set folds for out-of-fold prediction
kf = KFold(n_splits=NFOLDS, random_state=SEED)
# Class to extend the Sklearn classifier
class SklearnHelper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def train(self, x_train, y_train):
self.clf.fit(x_train, y_train)
def predict(self, x):
return self.clf.predict(x)
def fit(self,x,y):
return self.clf.fit(x,y)
def feature_importances(self,x,y):
print(self.clf.fit(x,y).feature_importances_)
def get_oof(clf, x_train, y_train, x_test):
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
# np.empty()返回一个随机元素的矩阵
oof_test_skf = np.empty((NFOLDS, ntest))
for i, (train_index, test_index) in enumerate(kf.split(oof_train)):
x_tr = x_train[train_index]
y_tr = y_train[train_index]
x_te = x_train[test_index]
clf.train(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
# k则验证之后会产生[k x ntest]个验证集
oof_test_skf[i, :] = clf.predict(x_test)
# 按列取平均值
oof_test[:] = oof_test_skf.mean(axis=0)
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
# Random Forest classifier
# Extra Trees classifier
# AdaBoost classifer
# Gradient Boosting classifer
# Support Vector Machine
# Put in our parameters for said classifiers
# Random Forest parameters
rf 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









