







 本文深入探讨了Redis的持久化机制,包括RDB和AOF两种方式。RDB通过定期快照保存数据,适用于全量备份和快速重启。AOF则记录每次写操作,保证数据实时性,但可能导致文件膨胀。在两者同时开启时,服务器重启优先恢复AOF数据。此外,文章还介绍了RDB的文件结构、生成与加载原理,以及AOF的同步策略、保存、载入和重写过程。
本文深入探讨了Redis的持久化机制,包括RDB和AOF两种方式。RDB通过定期快照保存数据,适用于全量备份和快速重启。AOF则记录每次写操作,保证数据实时性,但可能导致文件膨胀。在两者同时开启时,服务器重启优先恢复AOF数据。此外,文章还介绍了RDB的文件结构、生成与加载原理,以及AOF的同步策略、保存、载入和重写过程。
以下内容基于redis3.0版本
一、持久化WWH
1、什么是持久化?
将redis数据以某一 种/多种方式,从内存写入磁盘,避免宕机导致数据丢失。
2、持久化方式
RDB (Redis DataBase)
• rdb 保存的是dump.rdb文件
• 在指定的时间间隔内将内存中的数据集快照写入磁盘;
• 恢复时是将快照文件直接读到内存里。
• 触发条件:
save <seconds> <changes> # save 900 1 //900秒内至少有1个key被改变
# save 300 100 //300秒内至少有10个key被改变
# save 60 10000 //60秒内至少有10000个key被改变
动态停止所有RDB保存规则的方法:
redis-cli config set save ""
rdbcompression yes //rdb文件压缩
rdbchecksum yes// CRC64校验数据,后续原理部分会提及
dbfilename dump.rdb //定义持久化数据库文件名
dir ./ //存放路径
AOF(Append Only File)
• Aof保存的是appendonly.aof文件
• 以日志的形式来记录每个写操作,只追加不改写 ;
• 恢复时读取指令逐步执行完成以恢复数据。
appendonly yes // 是否开启
appendfilename “appendonly.aof” //文件名
//写入方式,默认每秒
# appendfsync always
appendfsync everysec
# appendfsync no
no-appendfsync-on-rewrite no //
auto-aof-rewrite-percentage 100 //重写基准百分比
auto-aof-rewrite-min-size 64mb //重写基准
重写
命令:bgrewriteaof
Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
3、持久化对比
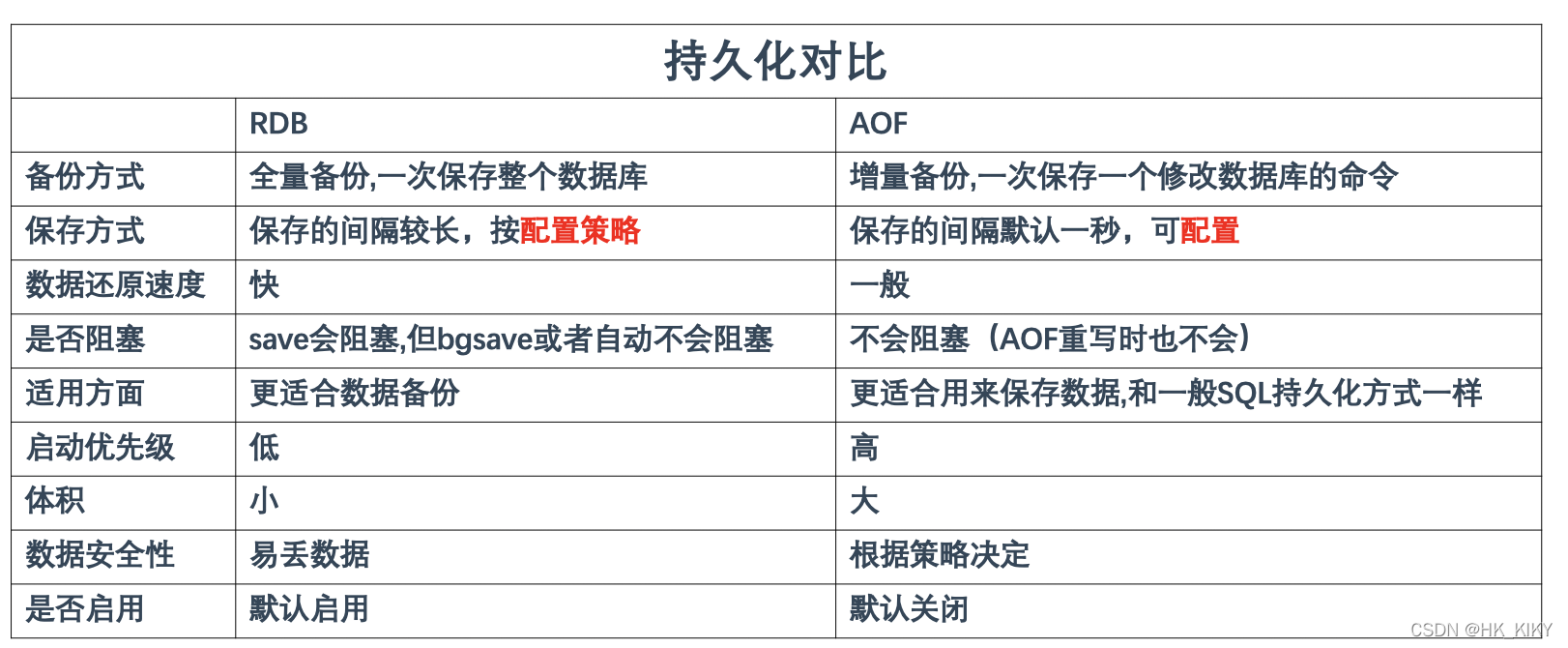
同时开启两种持久化方式:
在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.
RDB的数据不实时,同时使用两者时服务器重启也只会找AOF文件。那要不要只使用AOF呢?作者建议不要,因为RDB更适合用于备份数据库(AOF在不断变化不好备份),快速重启,而且不会有AOF可能潜在的bug,留着作为一个万一的手段。
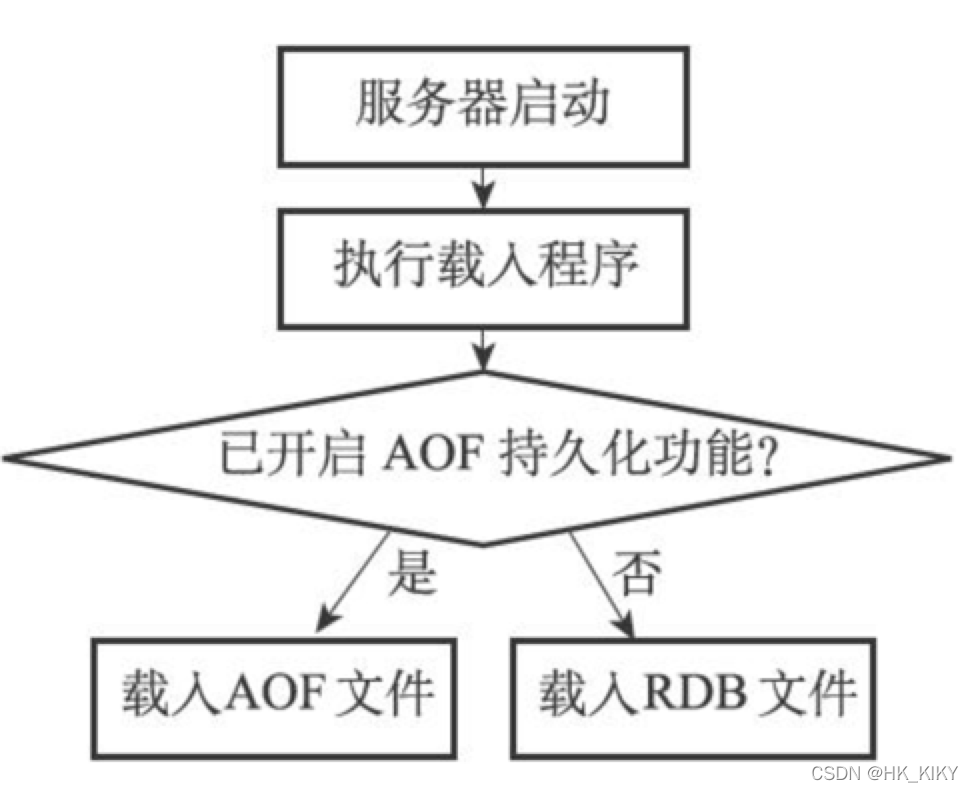
二、持久化原理
持久化分为:文件生成、文件加载;接下来先了解文件格式,有利于了解文件生成、文件加载。
1、RDB原理
(1)RDB文件结构
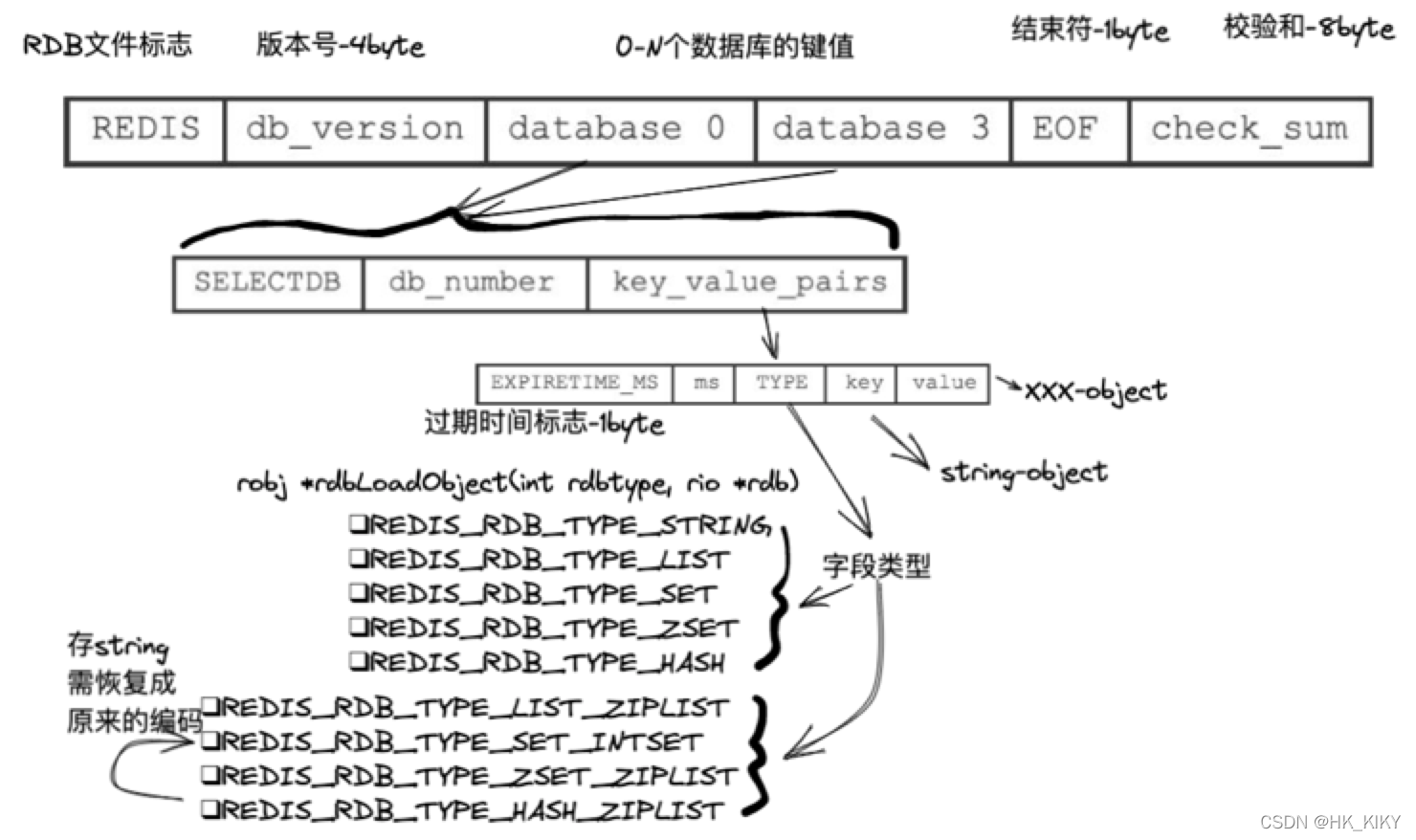
RDB文件保存的是二进制数据。
校验和是程序通过对REDIS、db_version、databases、EOF四个部分的内容进行计算得出的。
服务器在载入RDB文件时,会将载入数据所计算出的校验和与check_sum所记录的校验和进行对比,以此来检查RDB文件是否有出错或者损坏的情况出现。
(2)RDB生成&载入
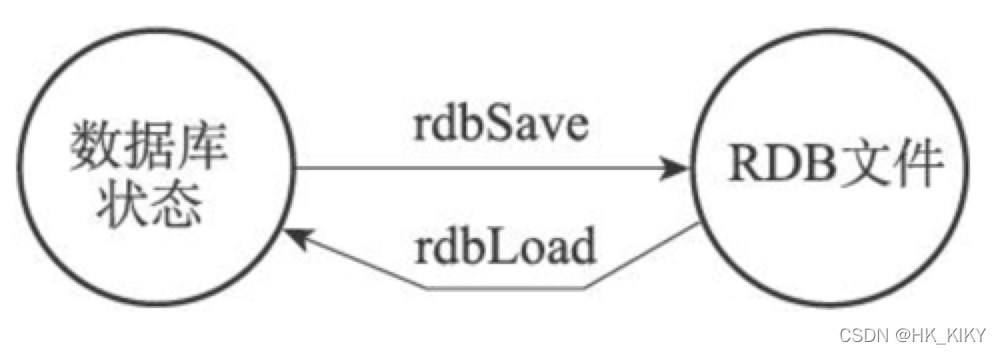
生成
• rdbsave 生成rdb
• 命令:SAVE(阻塞)、BGSAVE(非阻塞)
• rdbLoad 载入,启动自动载入,阻塞
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。

Redis.conf
save配置实际
是执行bgsave
创建RDB文件的实际工作由rdb.c/rdbSave函数完成
Save\bgsave 不能同时执行
自动间隔性保存
• 触发条件:
save <seconds> <changes> # save 900 1 //900秒内至少有1个key被改变 99
# save 300 100 //300秒内至少有10个key被改变
# save 60 10000 //60秒内至少有10000个key被改变
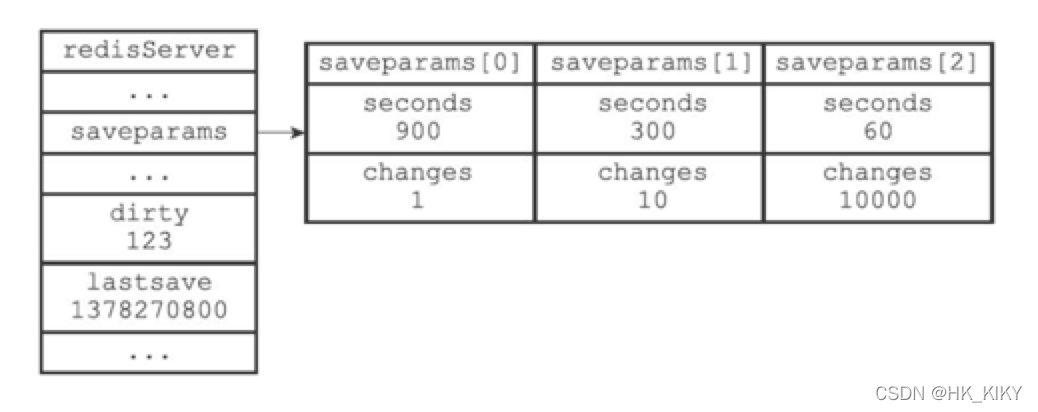
struct redisServer {
// 数据库
redisDb *db;
/* Save points array for RDB */
struct saveparam *saveparams;
// 自上次 SAVE 执行后,数据库被修改次数
long long dirty;
// 最后一次完成 SAVE 的时间
time_t lastsave;
…
}
// 服务器的保存条件(BGSAVE 自动执行的条件)
struct saveparam {
// 多少秒之内
time_t seconds;
// 发生多少次修改
int changes;
};保存逻辑
看代码rdb.c
rdbSave
rdbSaveKeyValuePair
rdbSaveObject

载入
载入涉及文件解析、执行
rdbLoad
rdbLoadObject

1、AOF原理
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤。
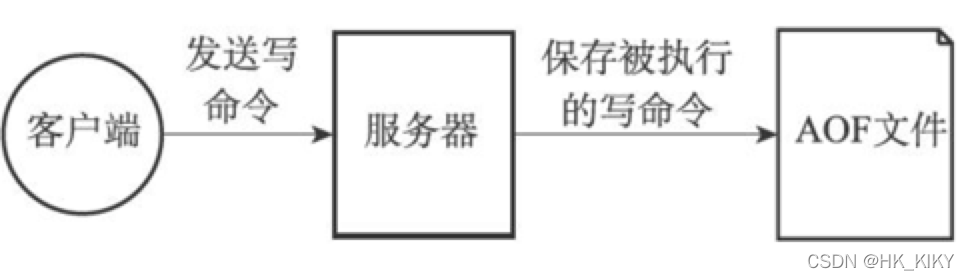
AOF是以命令的方式存储;写入AOF文件,实际是写入操作系统的文件缓存;同步则是操作系统缓存落地到磁盘。
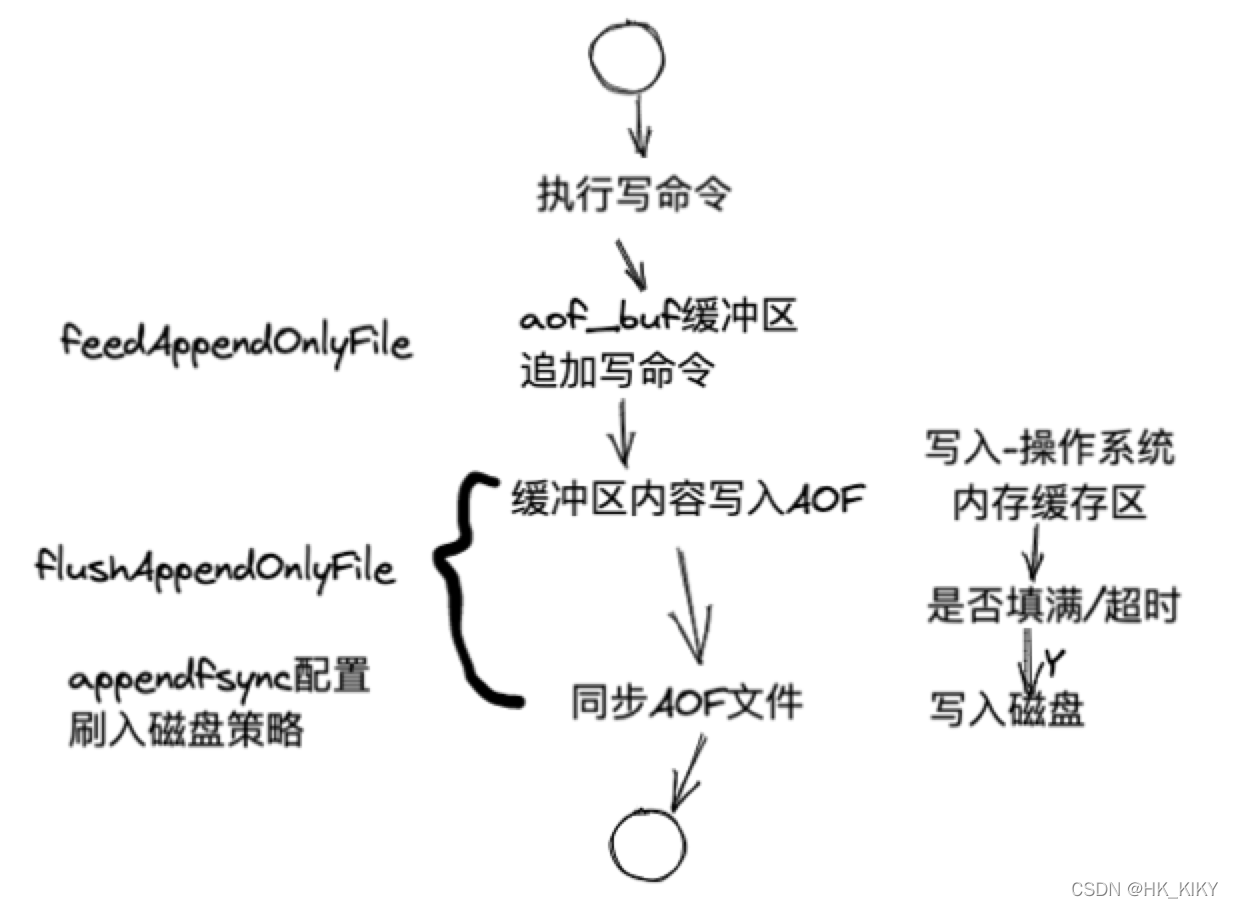
(1)AOF-同步策略

(2)AOF-保存
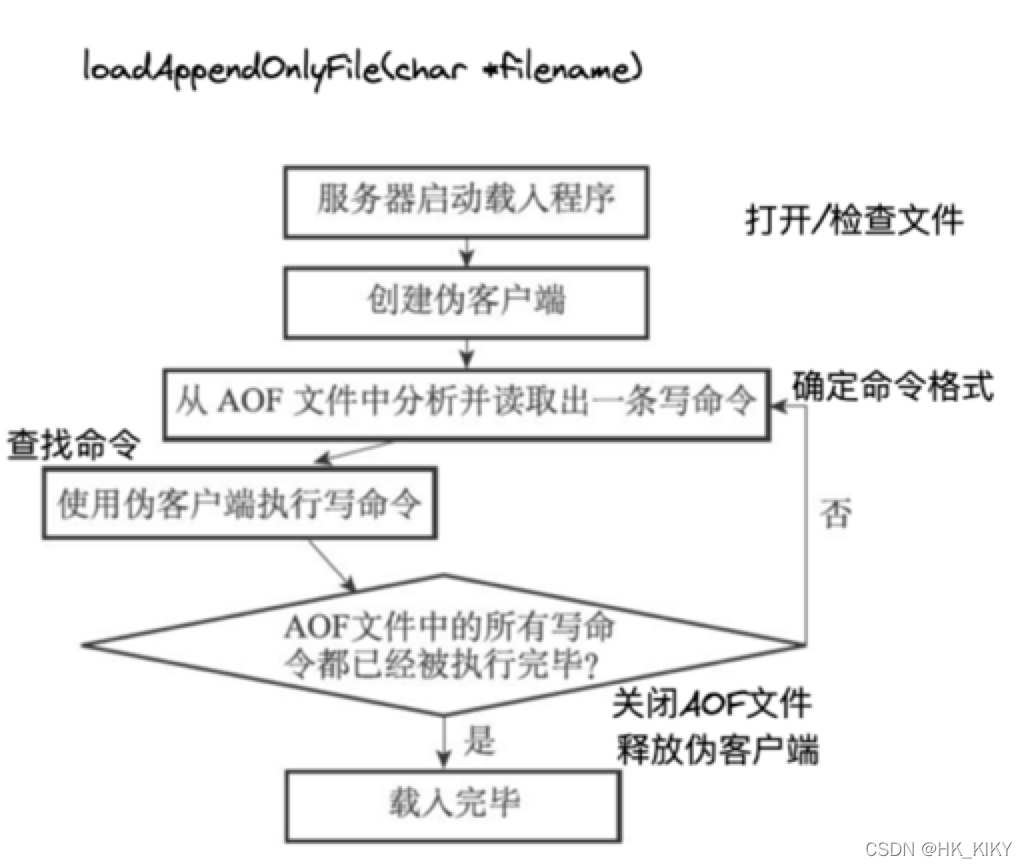
(3)AOF-载入
(4)AOF-重写
为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能。
BGREWEITEAOF
AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。
首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF重写功能的实现原理。
因为Redis服务器使用单个线程来处理命令请求,所以如果由服务器直接调用rewriteAppendOnlyFile
函数的话,那么在重写AOF文件期间,服务期将无法处理客户端发来的命令请求。
所以Redis决定将AOF重写程序放到子进程里执行,这样做可以同时达到两个目的:
❑子进程进行AOF重写期间,服务器进程(父进程)可以继续处理命令请求。
❑子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
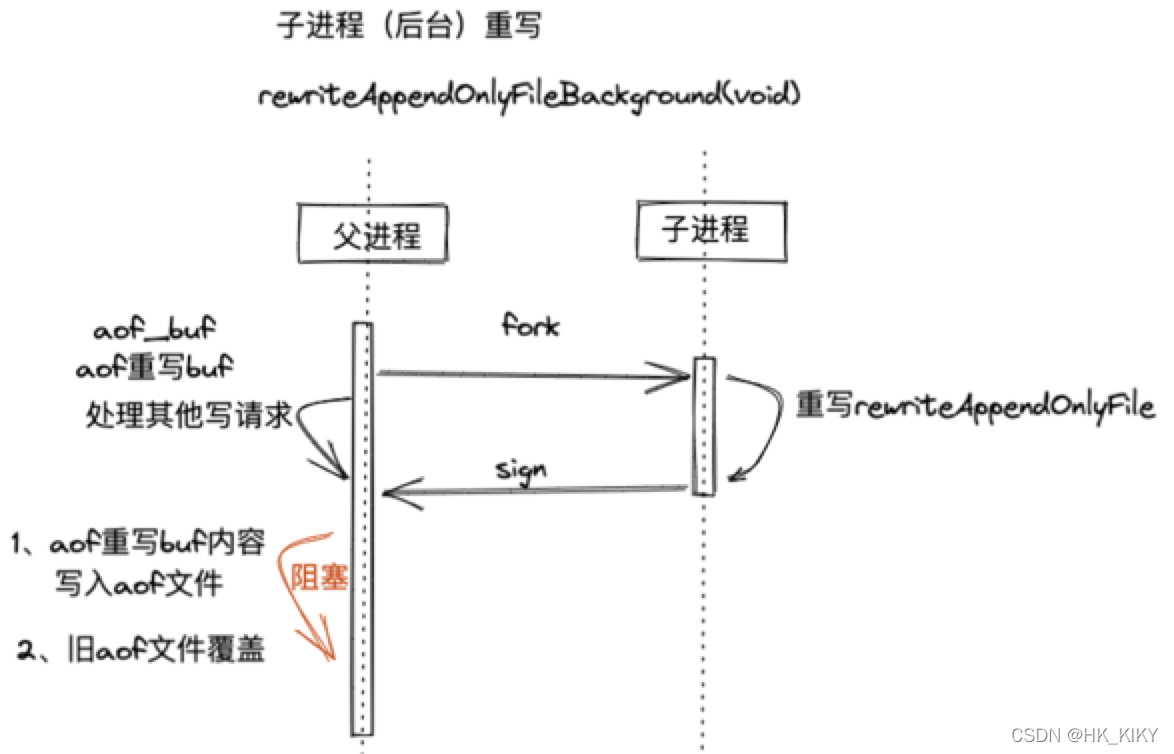

在子进程执行AOF重写期间,服务器进程需要执行以下三个工作:
1)执行客户端发来的命令。
2)将执行后的写命令追加到AOF缓冲区。
3)将执行后的写命令追加到AOF重写缓冲区。
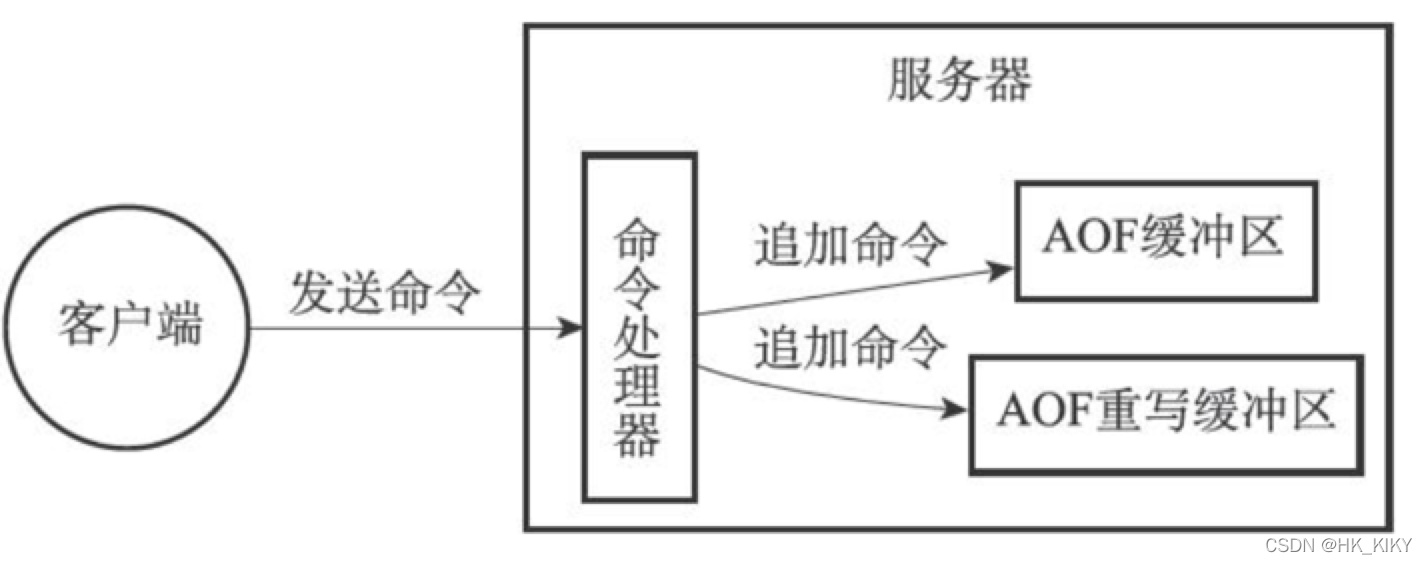
为了解决这种数据不一致问题,Redis服务器设置了一个AOF重写缓冲区。这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区。
当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接到该信号之后,会调用一个信号处理函数,并执行以下工作:
1)将AOF重写缓冲区中的所有内容写入到新AOF文件中,这时新AOF文件所保存的数据库状态将和服务器当前的数据库状态一致。
2)对新的AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧两个AOF文件的替换。
信号处理函数执行时会对服务器进程(父进程)造成阻塞
AOF-重写例子
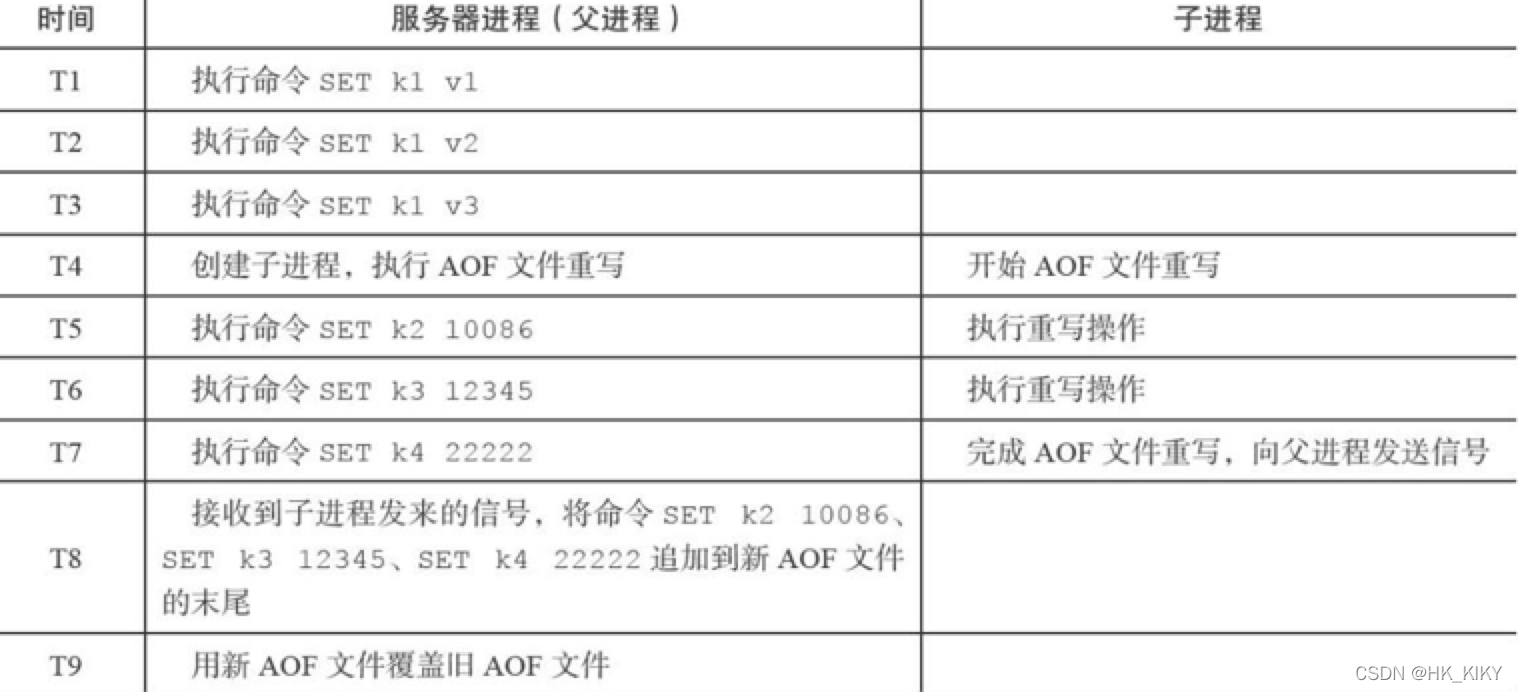
一个AOF文件后台重写的执行过程:
❑当子进程开始重写时,服务器进程(父进程)的数据库中只有k1一个键,当子进程完成AOF文件重写之后,服务器进程的数据库中已经多出了k2、k3、k4三个新键。❑在子进程向服务器进程发送信号之后,服务器进程会将保存在AOF重写缓冲区里面记录的k2、k3、k4三个键的命令追加到新AOF文件的末尾,然后用新AOF文件替换旧AOF文件,完成AOF文件后台重写操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









