







1. 基本方法
1.1 模型并行
网络较大时采用.
将网络层拆分开放到GPUn中进行训练
1.1.1 切分方式
两种切分方式:行切分、列切分。目标:找到最优的切分方式,减少训练过程中的通信次数
1.1.2 缺点
- 网络中并不是所有节点都可以进行模型并行拆分,因此在内存优化的效果上1+1<< 2
- 每个GPU中部分网络层的权重参数都需要保存下来,需要保存多份ckpt
1.1.3 改进
- 流水线并行
基于模型并行,一个batch结束前开始下一个batch,以充分利用计算资源。将模型按层进行切分,将不同的层放入不同的GPU,训练的时候数据像流水一样在GPU上进行流动
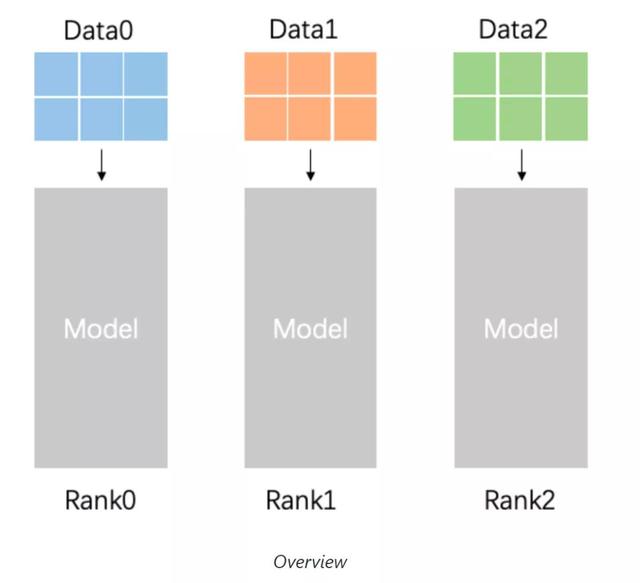
1.2 数据并行
数据集较大时采用.
1.2.1 理解
将数据切分成n块,分发给n个GPU并行处理,每个GPU上都有完整的模型,独立计算出各自的梯度后进行平均同步,并将同步后的梯度在每个节点独立修正模型.
最后在n个GPU上会得到n个相同的模型.
1.2.2 实现方法
Horovod开源框架(后续学习)
- 参数服务器
进行数据并行分布式训练的每个计算单元(GPU)把各自计算的梯度发送给参数服务器,参数服务器把梯度汇总后计算平均值再返回每个计算单元.这样每个计算单元把平均后的参数各自更新模型.


















 1525
1525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









