




GeoMesa-Kafka(GeoServer中创建GeoMesa-Kafka数据存储并发布图层)
前言
1.必须已经在集群中安装了GeoMesa-Kafka(CDH6.2.1集群中安装geomesa-kafka 3.1.0),并且在geoserver中安装了GeoMesa-Kafka的插件(geoserver中安装GeoMesa-Kafka插件)
2.这里模拟100万车辆的位置。使用GeoMesa-Kafka插入100万辆车辆的位置信息,然后再geoserver上创建存储发布图层,查看图层,测试查询速度。
一、生成100万车辆信息插入到kafka
schema的创建
//在这里可以理解为表名
final String sftName = "cars8";
//这里描述表结构,字段有car(表示车牌),dtg(时间),geom(位置信息)
final String sftSchema = "car:String,dtg:Date,*geom:Point:srid=4326";
SimpleFeatureType sft = SimpleFeatureTypes.createType(sftName, sftSchema);
ds.createSchema(sft);
生成并写入
FeatureWriter<SimpleFeatureType, SimpleFeature> writer = ds.getFeatureWriterAppend(sft.getTypeName(), Transaction.AUTO_COMMIT);
SimpleFeature toWrite = writer.next();
//生成100万车辆
for (int i = 1; i <= 1000000; i++) {
SimpleFeatureBuilder builder = new SimpleFeatureBuilder(sft);
//模拟车牌
String car = "闽A U"+i;
builder.set("car", car);
builder.set("dtg", new Date());
//在纬度范围(5 - 50),经度范围(90 - 146)生成
double latv = getRandom(500, 5000)/100.0;
double lngv = getRandom(9000, 14600)/100.0;
double lat = new BigDecimal(String.valueOf(latv)).doubleValue();
double lng = new BigDecimal(String.valueOf(lngv)).doubleValue();
String point = "POINT ("+lng+ " " +lat+")";
builder.set("geom",point);
builder.featureUserData(Hints.USE_PROVIDED_FID, Boolean.TRUE);
SimpleFeature feature = builder.buildFeature(car);
toWrite.setAttributes(feature.getAttributes());
((FeatureIdImpl) toWrite.getIdentifier()).setID(feature.getID());
toWrite.getUserData().put(Hints.USE_PROVIDED_FID, Boolean.TRUE);
toWrite.getUserData().putAll(feature.getUserData());
writer.write();
}
// 关闭流
writer.close();
在kafka中查看是否有数据了
命令行查看
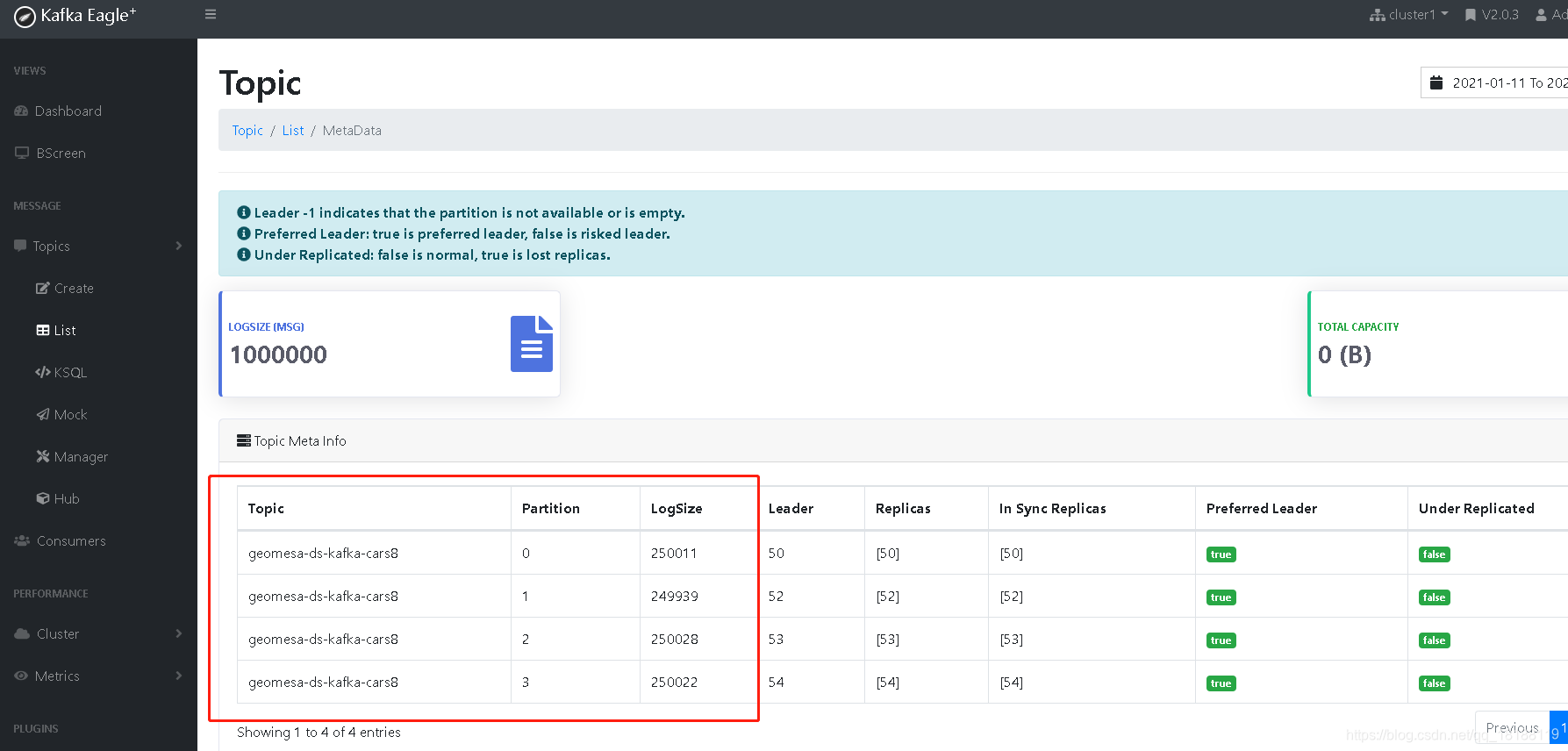
进入kafka的数据存储路径(cdh 6.2.1的话是在/var/local/kafka/data),查看有一个geomesa-ds-kafka-cars8开头的,这就是刚刚生成的。topic的名字为geomesa-ds-kafka-cars8。

kafka图形化界面查看
这里我们安装的是kafka eagle。
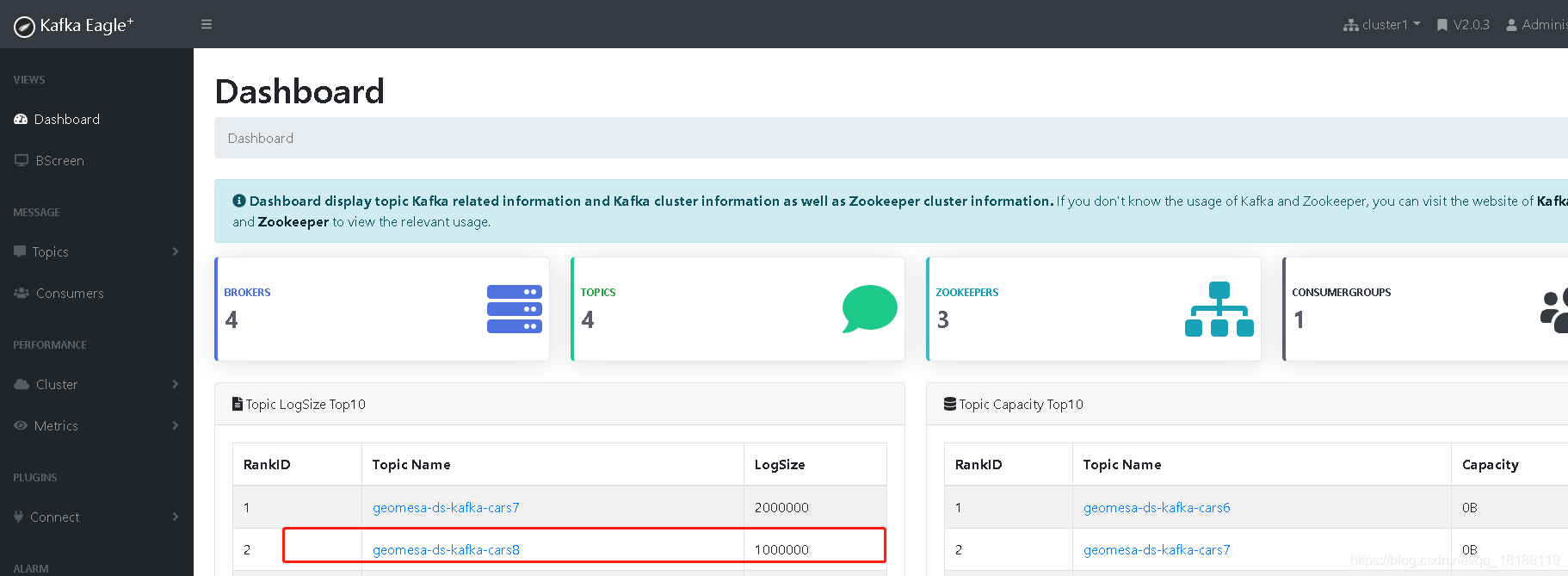
我这里有4台机器,partition给的也是4。
二、geoserver中发布
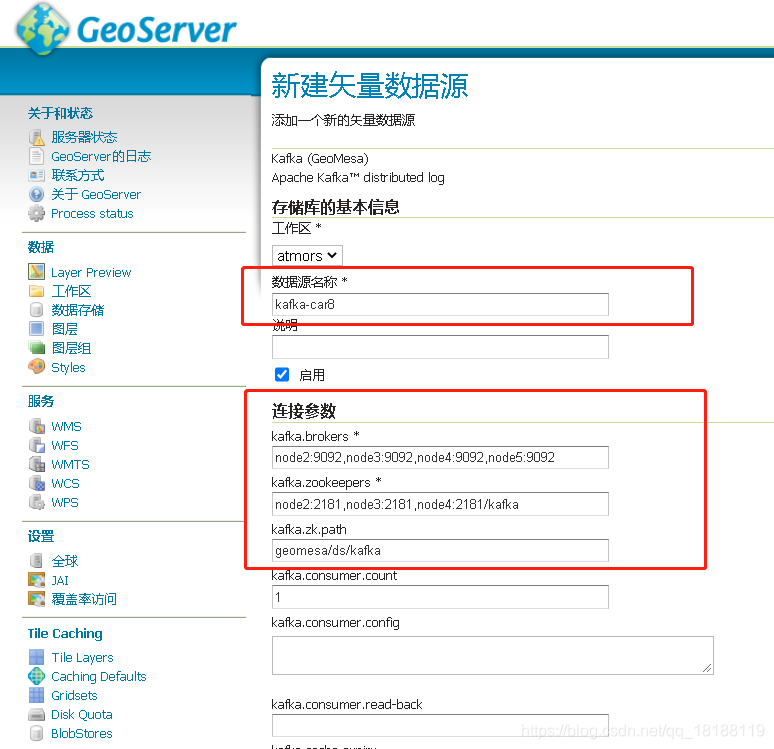
创建存储
点击Kafka(GeoMesa)

填写参数
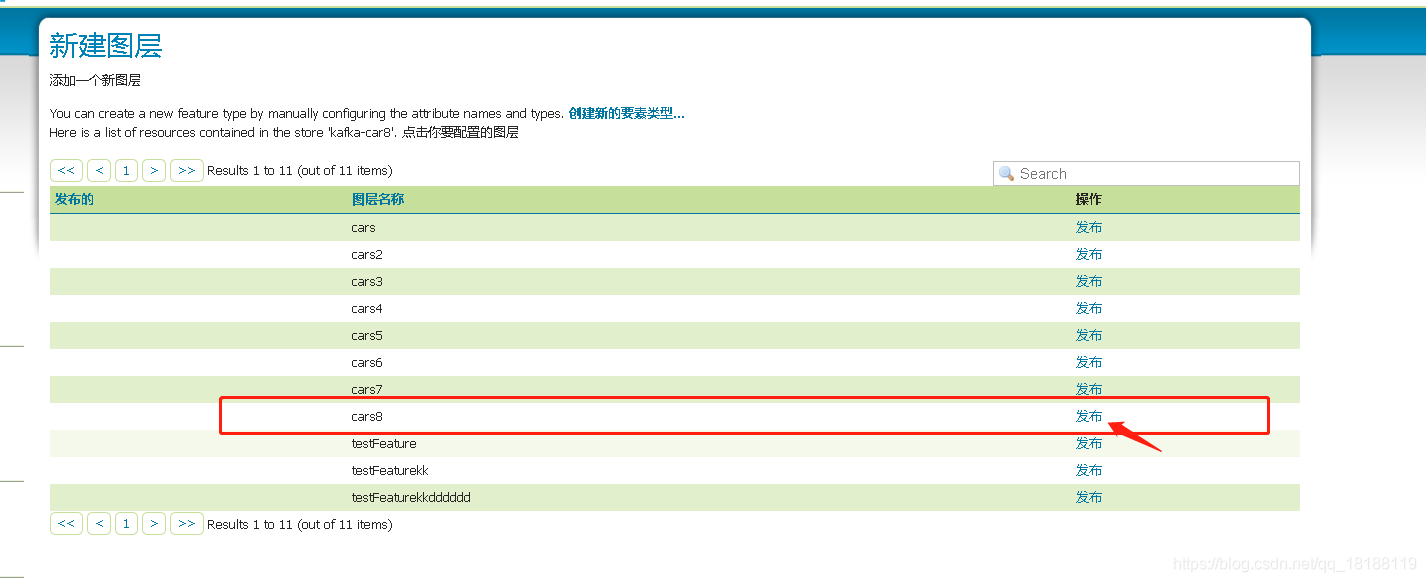
发布图层
点击发布
发布参数设置,整简单点,设置下图层名,以及计算一下图层数据的边框范围
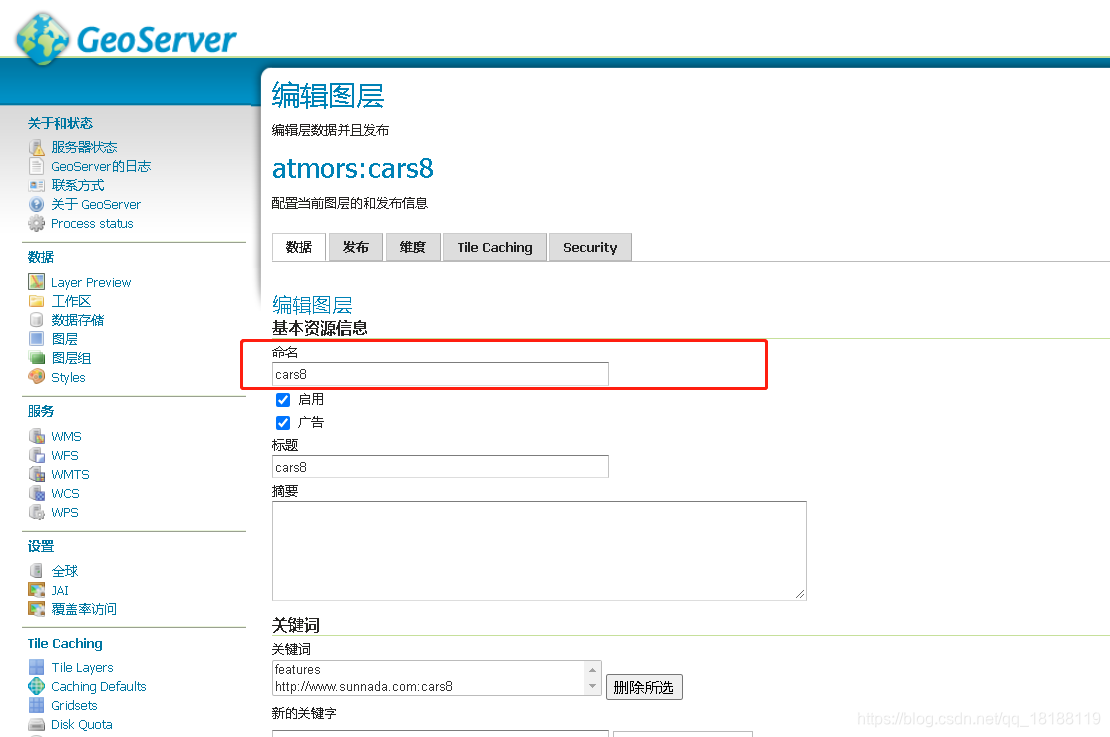
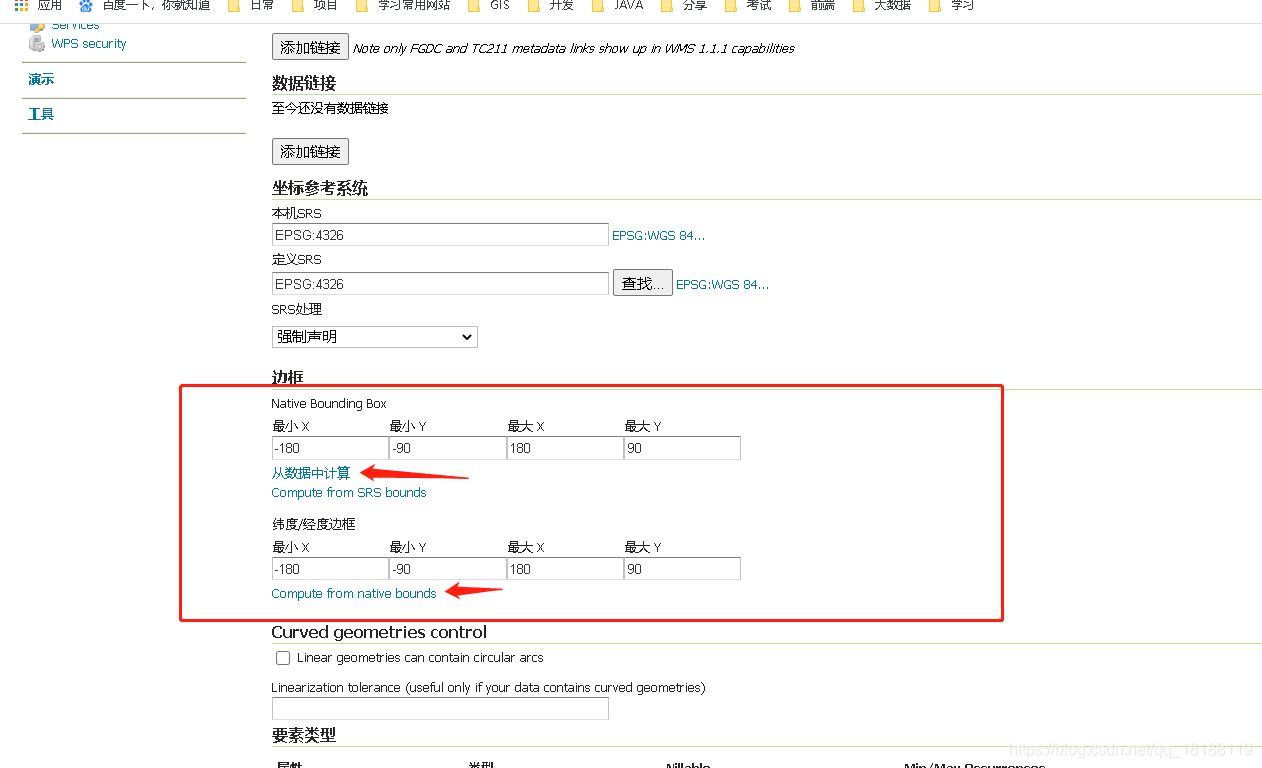
点击保存后就可以去预览图层了
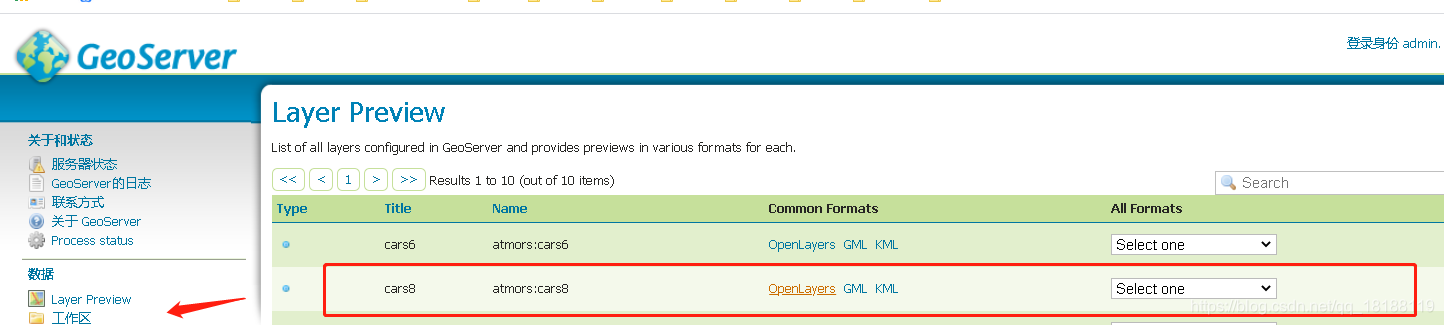
点击openlayers,咦发现什么都没有。这里就是涉及到了很多的参数设置,这里就不详细展开了,这里面涉及到很多kafka的知识。这里是因为我们geoserver相当于实现消费者,
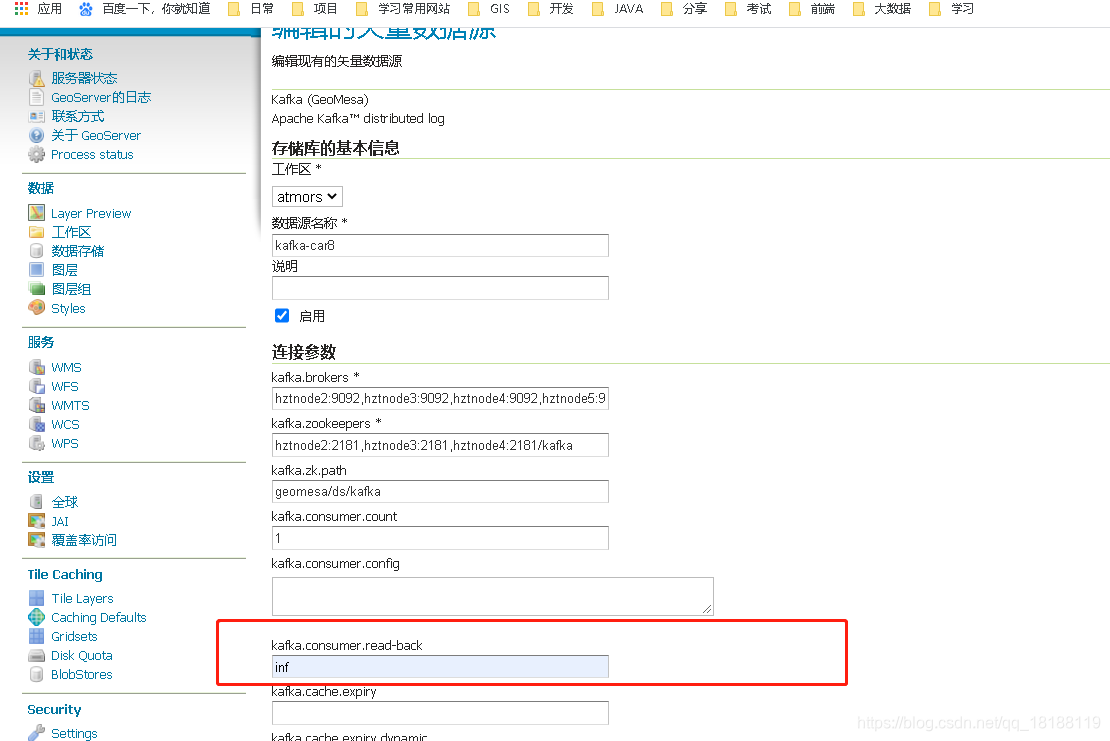
我们是先生产后创建的消费者。这里我们修改一下创建存储的时候的一个参数kafka.consumer.read-back为 inf,这个意思是读取这个topic中的所有数据。或者也可以重新生产数据。

修改参数
查看图层
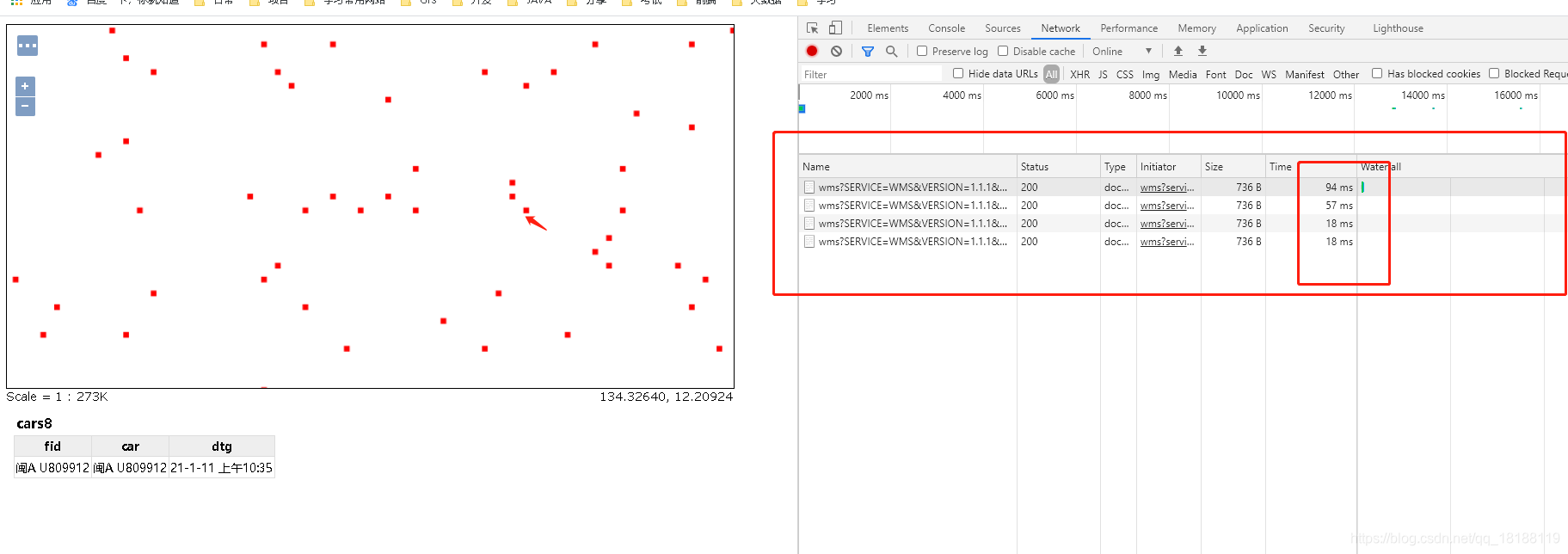
重新查看,图层,100万点密密麻麻显示着。。

放大点击查询某个车辆的信息
查询数据是相当快的。
总结
1.这里知识简单的测试一下,其中还有很多细节可以研究。kafka的知识要事先具备。
2.欢迎互相学习,交流讨论,本人的微信:huangchuanxiaa。


















 2152
2152





 到【灌水乐园】发言
到【灌水乐园】发言









