







散列表是字典类型性能出众的根本原因。
3.1 泛映射类型
collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为dict何其他类似的类型定义形式接口。
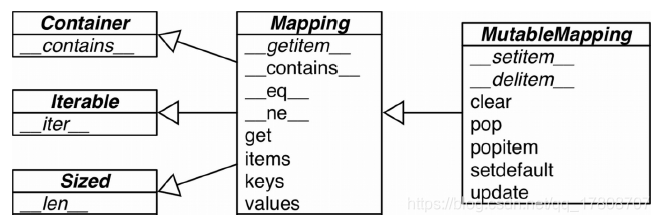
标准库中的所有映射类型都是利用dict来实现的,因此它们有个共同的限制,即只有可散列(hashable)的数据类型才能用作这些映射里的键。
可散列类型:如果一个对象是可散列的(hashable),那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__()方法。另外可散列对象还要有__eq__()方法,这样才可与其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的。
原子不可变数据类型都是可散列类型。对于元组,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
创建字典的一些方法:
>>> a=dict(one=1,two=2,three=3)
>>> b={'one':1,'two':2,'three':3}
>>> c=dict(zip(['one','two','three'],[1,2,3]))
>>> d=dict([('two',2),('one',1),('three',3)])
>>> e=dict({'Three':3,'two':2,'one':1})
3.2 字典推导
操作如下:
>>> message=[(1,'a'),(2,'b'),(3,'c')]
>>> dic_message={index:num for num,index in message}
>>> dic_message
{'a': 1, 'b': 2, 'c': 3}
3.4 映射的弹性键查询
有时为了方便起见,就算某个键在映射里不存在,也希望在通过这个键读取值的时候能得到一个默认值。有两个途径可达到这个目的,一个是通过defaultdict,另一个是定义一个dict子类,然后在子类中实现__missing__方法。
1 defaultdict:处理找不到键的一个选择
defaultdict有一个default_factory方法,是在__missing__函数中被调用的函数,用以给未找到的元素设置值。实际上,default_factory并不是一个方法,而是一个可调用对象,其值在defaultdict初始化时由用户设定。如下示例:
>>> d=defaultdict(str)
>>> d['a']=1
>>> d['b']
''
>>> d
defaultdict(<class 'str'>, {'a': 1, 'b': ''})
这里创建一个defaultdict,其default_factory为str构造方法,当一个键并没有对应的值时,会默认分配一个空字符串。
2.特殊方法__missing__
__getitem__方法让字典能用d[k]的形式返回键k对应的值。当__getitem__方法找不到对应键时,__missing__方法会被调用。__missing__方法只会被__getitem__调用。
参看如下示例:
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key,str):
raise KeyError(key)
return self[str(key)]
def get(self,key,default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()
StrKeyDict0继承了dict。
在__missing__方法中,如果找不到的键本身是字符串,则抛出KeyError;若找不到的键不是字符串,那将其转换为字符串再进行查找。
get(k,[default])方法用于查找某个键对应的值。若没有键k,则返回None或者default。
在覆盖(override)的get方法中,将查找工作用self[key]的形式委托给__getitem__,这样在宣布查找失败前,还能通过__missing__再给某个键一次机会;如果抛出KeyError,那说明__missing__也失败了,于是返回default。
__contains__方法用于检查k是否在d中。用于"k in d"的调用形式。在覆盖(override)的方法中,先按照传入键的原本值来查找,如果没找到,再str()方法把键转换成字符串再查找一次。
上述类的应用如下所示:
>>>d=StrKeyDict0([('2','two'),('4','four')])
>>>d['2']
'two'
>>>d[4]
'four'
>>>d[1]
Traceback (most recent call last):
.................
.................
KeyError: '1'
>>>d.get('2')
'two'
>>>d.get(4)
'four'
>>>d.get(1,'N/A')
'N/A'
>>>2 in d
True
>>>1 in d
False
3.5 字典的变种
本节总结了标准库里collections模块中,除了defaultdict之外的不同映射类型。
collections.OrderedDict
有序字典。这个类型在添加键时会保持顺序,因此键的迭代次序总是一致的。OrderedDict的popitem方法默认删除并返回的是字典中最优一个元素。但若将其last参数设置为False,则删除并返回第一个被添加的元素。如下示例:
>>> my_ordict=OrderedDict([('a',1),('b',2),('c',3)])
>>> my_ordict
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> my_ordict.keys()
odict_keys(['a', 'b', 'c'])
>>> my_ordict.popitem()
('c', 3)
>>> my_ordict.popitem(last=False)
('a', 1)
collections.ChainMap
该类型可容纳数个不同的映射对象,然后在进行查找操作时,这些对象会被当做一个整体被逐个查找,知道键被找到为止。此功能在给有嵌套作用于的语言做解释器时很有用,可以用一个映射对象来代表一个作用域的上下文。
collections.Counter
这个映射类型会给键准备一个整数计数器。每次更新一个键时都会增加这个计数器,所以这个类型可用来给可散列表对象计数,或者是当成多重集来用——多重集合就是集合里的元素可以出现不止一次。Counter实现了+和-运算符用于合并记录,还有像most_common([n])这类很有用的方法。most_common([n])会按照次序返回映射里最常见的n个键和它们的计数。
下面的小例子利用Counter来计算单词中各个字母出现的次数:
>>> from collections import Counter
>>> ct=Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(2)
[('a', 10), ('z', 3)]
collections.UserDict
这个类其实就是把标准dict用纯Python又实现一遍,用于让用户继承写子类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









