






 本文详细介绍如何使用Docker在CentOS7上安装配置JDK8,并创建自定义网络,通过映射端口和IP地址搭建包含Master和两个Slave节点的Hadoop集群。步骤包括创建用户组、设置SSH免密登录、下载并配置Hadoop,最后启动和验证HDFS集群运行状态。
本文详细介绍如何使用Docker在CentOS7上安装配置JDK8,并创建自定义网络,通过映射端口和IP地址搭建包含Master和两个Slave节点的Hadoop集群。步骤包括创建用户组、设置SSH免密登录、下载并配置Hadoop,最后启动和验证HDFS集群运行状态。
基于centos7-jdk8镜像安装 centos7-jdk8一个安装jdk的镜像,也可以空白容器自己装。
创建master容器,50070和8088,8080是用来在浏览器中访问hadoop yarn spark #WEB界面,这里分别映射到物理机的50070和8088,8080端口
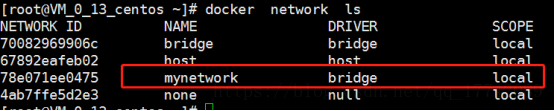
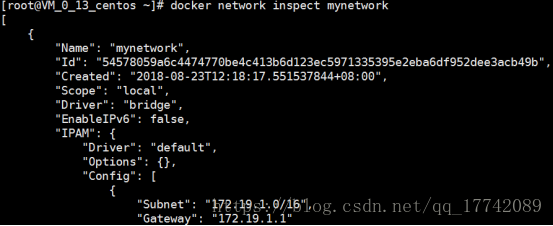
创建自定义网段
docker network create –driver bridge –subnet=172.19.1.0/16 –gateway=172.19.1.1 mynetwork
可以看到新的配置
创建三个节点 为了方便操作映射22端口
master
docker run -d -P -p 50070:50070 -p 8088:8088 -p 8080:8080 -p 1023:22 –name master -h master –network=mynetwork –ip 172.19.1.4 –add-host slave01:172.19.1.5 –add-host slave02:172.19.1.6 tiankuokuo/jdk8
创建slave01容器,在容器host文件,添加hostname,并配置其他节点主机名称和IP地址
docker run -d -P -p 1024:22 –name slave01 -h slave01 –network=mynetwork –ip 172.19.1.5 –add-host master:172.19.1.4 –add-host slave02:172.19.1.6 tiankuokuo/jdk8
创建slave02容器
docker run -d -P -p 1025:22 –name slave02 -h slave02 –network=mynetwork –ip 172.19.1.6 –add-host master:172.19.1.4 –add-host slave01:172.19.1.5 tiankuokuo/jdk8
分别进入容器创建用户组
groupadd hadoop
useradd hadoop -g hadoop
设置密码
passwd hadoop
mkdir -p /usr/local/hadoop
mkdir -p /usr/local/park
chown -R hadoop:hadoop /usr/local/hadoop
配置ssh免密登录
切换账号
su hadoop
ssh-keygen
ssh-copy-id -i /home/hadoop/.ssh/id_rsa -p 22 hadoop@master
ssh-copy-id -i /home/hadoop/.ssh/id_rsa -p 22 hadoop@slave01
ssh-copy-id -i /home/hadoop/.ssh/id_rsa -p 22 hadoop@slave02
下载hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
在hadoop-env.s 中配置JAVA_HOME

在slaves中配置子节点主机名
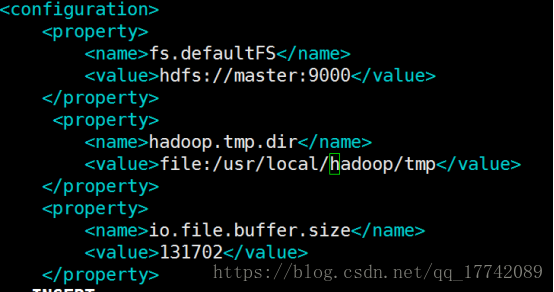
修改core-site.xml
修改hdfs-site.xml
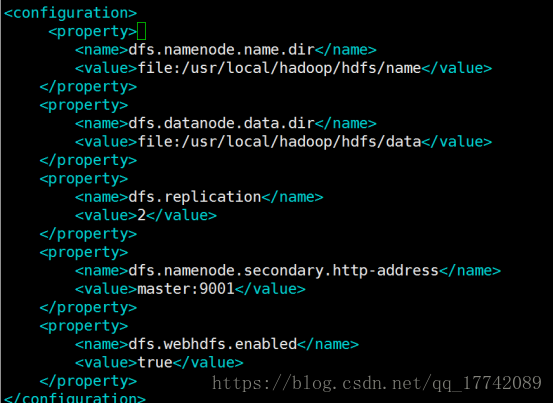
修改mapred-site.xml cp mapred-site.xml.template mapred-site.xml
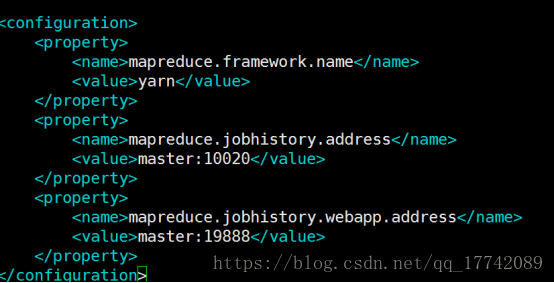
修改yarn-site.xml
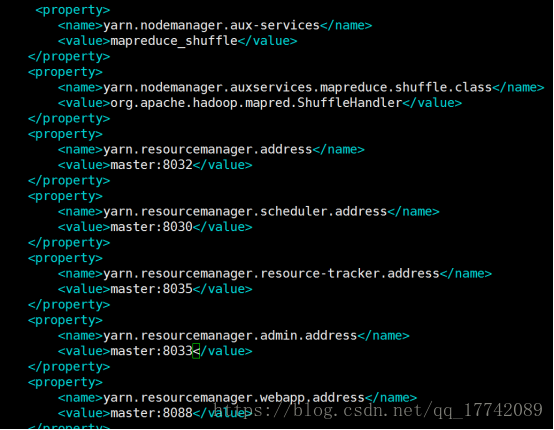
master容器配置的hadoop目录分别分发到slave01,slave02节点
scp -r hadoop-2.7.7/ slave01:/usr/local/hadoop/
scp -r hadoop-2.7.7/ slave02:/usr/local/hadoop/
设置 hadoop 环境变量

分发到slave01、slave02节点
scp -r ~/.bashrc slave01:~/
scp -r ~/.bashrc slave02:~/
source ~/.bashrc
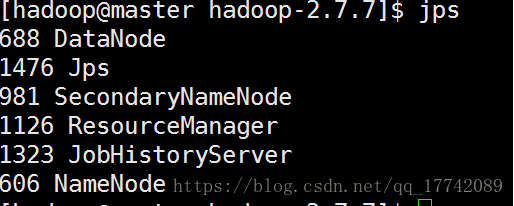
**启动HDFS集群,验证是否搭建成功
初始化**
hdfs namenode -format
启动
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
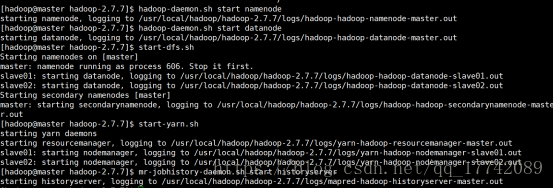
master
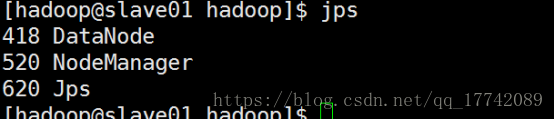
Slave01
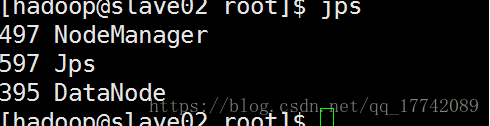
Salve02
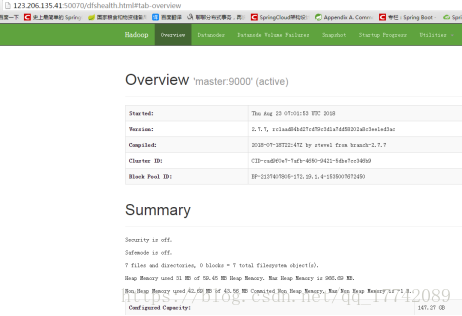
http://master ip:50070/
http://master ip:8088/
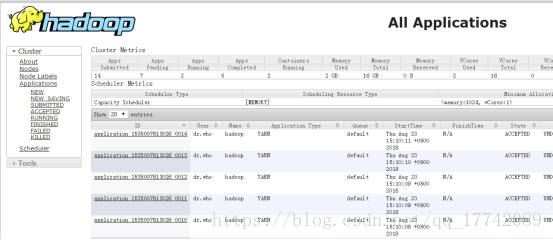
**测试验证
创建目录**
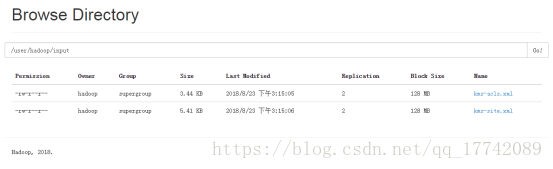
hdfs dfs -mkdir -p /user/hadoop/input
上传文件,把现有的一些配置文件上传到刚刚创建的目录中
hdfs dfs -put /usr/local/hadoop/hadoop-2.7.7/etc/hadoop/kms*.xml /user/hadoop/input
mapreduce 操作
hadoop jar /usr/local/hadoop/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep /user/hadoop/input /user/hadoop/output ‘dfs[a-z.]+’

















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









