







 本文介绍了Bi-LSTM-CRF模型在命名实体识别(NER)中的作用,阐述了BiLSTM层如何输出单词的类别得分,以及CRF层如何通过学习训练集中的限制来提高预测准确性。没有CRF层时可能出现的问题,以及CRF层如何通过发射和转移得分来学习有效序列。最后,讨论了CRF损失函数和计算所有路径得分的方法。
本文介绍了Bi-LSTM-CRF模型在命名实体识别(NER)中的作用,阐述了BiLSTM层如何输出单词的类别得分,以及CRF层如何通过学习训练集中的限制来提高预测准确性。没有CRF层时可能出现的问题,以及CRF层如何通过发射和转移得分来学习有效序列。最后,讨论了CRF损失函数和计算所有路径得分的方法。
第1节 介绍
1.介绍
Bi-LSTM-CRF算法是目前最为流行的NER算法。
BiLSTM和CRF可以看做NER模型中的两个不同层
1.1 开始之前
假设我们有一个数据集,其中有两种实体类别:Person和Organization。对于每一个类别又分为开始单词和中间单词,所以就有了5种类别。
- B-Person (Person的第一个单词)
- I- Person (Person的中间单词)
- B-Organization (Organization的第一个单词)
- I-Organization (Organization的中间单词)
- O (其他实体)
比如xxx是包含5个单词的句子 w0,w1,w2,w3,w4w0,w1,w2,w3,w4w0,w1,w2,w3,w4.其中[w0,w1w_0,w_1w0,w1]是Person实体, [w2,w3w_2,w_3w2,w3] 是Organization实体,其他是“O”.
1.2 BiLSTM-CRF model
- 首先,句子x中的每一个单词都会被表示成一个向量,这个向量包含单词的character embedding 以及word embedding. 这里的character embedding随机初始化.word embedding通常来自一个预训练的word embedding文件. 所以的embeddings都会在训练过程中微调
- 然后,BiLSTM-CRF模型的输入是这些embeddings,输出是句子x的所以单词的预测标签.

我们需要知道BiLSTM这一层输出结果的意义
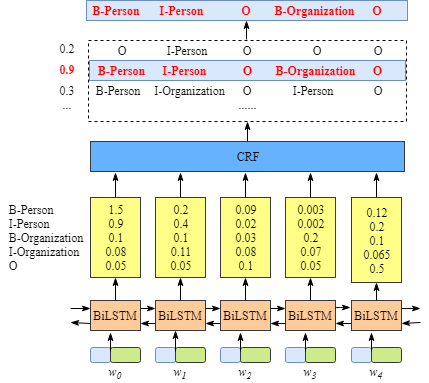
上图说明BiLSTM的输出是该单词对应每一个类别的scores。举例来说,对于
w0,BiLSTM节点的输出是1.5 (B-Person), 0.9 (I-Person), 0.1 (B-Organization), 0.08 (I-Organization) 以及0.05 (O). 这些score作为CRF layer的输入.
然后所有的BiLSTM blocks预测的score都会被喂到CRF layer. CRF layer中,在所有的label sequence选择预测得分最高的序列作为最佳答案.
1.3 如果没有CRF layer会怎么样
你可能会发现,如果没有CRF Layer,也可以只用BiLSTM来训练NER模型
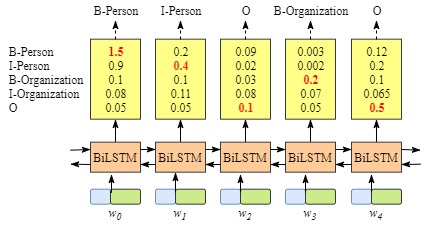
由于每个word的BiLSTM的输出是labe得分情况. 可以选择每个单词中得分最高的label作为结果。
例如,对于单词ω0\omega_0ω0, “B-Person”得分最高(1.5), 因此可以选择“B-Person” 作为预测label.
尽管这里可以得到正确的预测结果,但是在有些如下面的情况中,

很显然,预测的labels是不对的。“I-Organization I-Person”以及 “B-Organization I-Person”.因为两个不同类别的中间词不可能挨着等等
1.4 CRF layer 可以学到训练集中的限制
CRF layer 可以对最终的预测labels添加一些限制来确保结果是有效的. 这些限制可以由CRF layer在训练过程中自动的训练数据集中学到.
这些限制可以是
- 句子的第一个单词应该是“B-“或 “O”,不可能是 “I-“
- “B-label1 I-label2 I-label3 I-…”, 在这个模式中, label1, label2, label3 应该是同一个实体label.例如 “B-Person I-Person”是可以的, “B-Person I-Organization” 无效
- “O I-label” 不合法。命名实体的开始应该是 “B-“ 而不是 “I-“
添加了这些限制之后,预测结果中的无效序列会大幅减少
小结
接下来会分析CRF loss function来解释为什么CRF layer 可以学到训练数据中的这些限制。
第二节 CRF 层
在CRF层的损失函数中有两种类型的score,这两种类型的score是CRF layer的关键部分.
2.1 Emission score

第一个是emission score,这些emission score来自于BiLSTM layer. 如下图所示比如w0w_0w0作为B-Person标签的得分是1.5.
为了方便,给一种label一个index
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
使用xiyjx_{iy_j}xiyj来表示emission score。i是单词的index,yjy_jyj是label的index。例如在上图中,xi=1,yj=2=xw1,B−Organization=0.1x_{i=1,y_j=2}=x_{w_1,B−Organization}=0.1xi=1,yj=2=xw1,B−Organization=0.1表示w1作为B-Organization的得分是 0.1.
2.2 Transition score
使用 tyiyjt_{y_iy_j}tyiyj来表示transition score。举例tB−Person,I−Person=0.9t_{B−Person,I−Person}=0.9tB−Person,I−Person=0.9表示标签转移B-Person -> I-Person的概率是0.9.因此。有了保存所有labels之间score矩阵。
加入START和END来使转移矩阵更加健壮。START表示句子的开始,END表示句子的结束。
这里有一个转移矩阵

我们可以看到转移矩阵可以学到一些有用的限制条件
- 句子的开始应该是 “B-“ 或 “O”,而不是 “I-“(从START到I-Person或I-Organization的得分非常低)
- “B-label1 I-label2 I-label3 I-…”, 在这个模式中, label1, label2, label3 应该是同一个实体label.例如 “B-Person I-Person”是可以的(例如 “B-Organization”到“I-Person” 仅仅是0.0003)
- “O I-label” 不合法(tO,I−PERSONt_{O,I-PERSON}tO,I−PERSON的得分非常低)
那么如何得到 transition matrix呢
实际上 transition matrix是BiLSTM-CRF model的一个参数。在你开始训练模型之前,可以随机初始化。所有的random score会在训练过程中自动更新
说明CRF layer可以自己学习这些约束,不需要手动建立约束。矩阵会随着迭代过程更加合理。
2.3 CRF loss function
CRF loss function由真实路径得分和和所有可能路径的总分组成. 真实路劲应该具有在可能路径中有最高的分数。
例如数据中有下面的label:
| Label | Index |
|---|---|
| B-Person | 0 |
| I-Person | 1 |
| B-Organization | 2 |
| I-Organization | 3 |
| O | 4 |
| START | 5 |
| END | 6 |
有一个有5个单词的句子,可能的路径可能是
- START B-Person B-Person B-Person B-Person B-Person END
- START B-Person I-Person B-Person B-Person B-Person ENDSTART B-Person I-Person B-Person B-Person B-Person END
- ……
- START B-Person I-Person O B-Organization O END10) START B-Person I-Person O B-Organization O END
- ……
- O O O O O O O
假设每一条路径有一个score PiP_iPi,一共有 N条路径,所以总得分是Ptotal=P1+P2+…+PN=eS1+eS2+…+eSNP_{total}=P_1+P_2+…+P_N=e^{S1}+e^{S2}+…+e^{SN}Ptotal=P1+P2+…+PN=eS1+eS2+…+eSN
假设第4条路径是真实路径,那么P10P_{10}P10应该在所有的可能路径中占据最大的比例
下面给出loss function。
LossFunction=PrealpathP1+P2+…+PNLossFunction = \frac{P_{realpath}}{P_1+P_2+…+P_N}LossFunction=P1+P2+…+PNPrealpath
在训练过程中,更新BiLSTM-CRF 的参数,使得真实路径的比重保持不断增加
现在的问题是:
- 如何定义一条路径的score
- 如何计算所有路径的总score
- 计算总score时,需要列出所有可能的路径吗?(不需要)
2.4 Real Path Score
显然在所有可能的路径中有一条真实的路径。
例如真实的路径是“START B-Person I-Person O B-Organization O END”. 其他不正确的路径有“START B-Person B-Organization O I-Person I-Person B-Person”.
eSie^{Si}eSi是第i条路径的得分.
在训练过程中,crf loss function只需要两个score:真实路径的得分和其他可能路径的总得分.真实路径的得分在所有可能路径得分中的比重会不断增加。
真实路径得分是通过eSie^{S_i}eSi计算得到
现在我们关注如何计算SiS_iSi.
以这条真实路径“START B-Person I-Person O B-Organization O END”来举个例子
- 这条句子中有5个单词w1,w2,w3,w4,w5w1,w2,w3,w4,w5w1,w2,w3,w4,w5
- 增加两个额外的单词来表示句子的开始和结束w0,w6w0,w6w0,w6
- SiS_iSi由两个部分组成 Si=EmissionScore+TransitionScoreS_i=EmissionScore+TransitionScoreSi=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









