









接口数据的处理:
- 直接通过浏览器请求查看返回数据:
- 查询基金实时信息:
http://fundgz.1234567.com.cn/js/{fundcode}.js
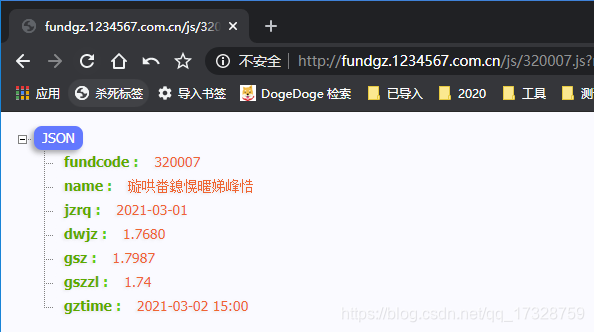
返回接口数据说明:
代码:fundcode
名称:name
净值日期:jzrq
单位净值:dwjz
估算值:gsz
估算增长率:gszzl
估值时间:gztime
我们需要的是“估算值”,使用requests请求接口后,直接返回对应的gszzl即可。def apiData(fundcode = 320007): logging.info(f'请求最新基金估值数据, 基金代码{fundcode}') headers ={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36" } url = f'http://fundgz.1234567.com.cn/js/{fundcode}.js' res = requests.get(url, headers = headers) logging.debug(f'get fund data from api {url}') if res.status_code == 200 : data = res.json()['gszzl'] else: data = res.text logging.debug(f'fund data {data}') return data - 查询置顶时间段的基金信息:
https://fundf10.eastmoney.com/F10DataApi.aspx?type={type}&code={fundcode}&page={i}&sdate={sdate}&edate={edate}&per={per}
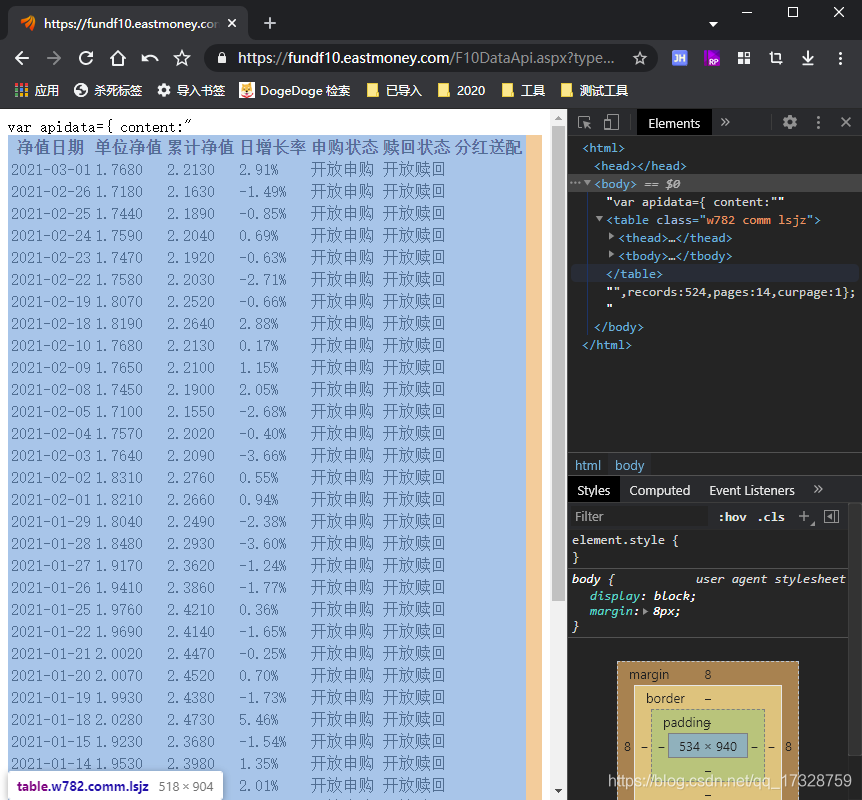
因为接口返回数据不能直接解析为json格式,但是通过浏览器开发工具查看返回的数据结构时,发现content数据是一个table结构。因此我们可以直接使用pandas.read_html方法直接读取这个表格的数据。
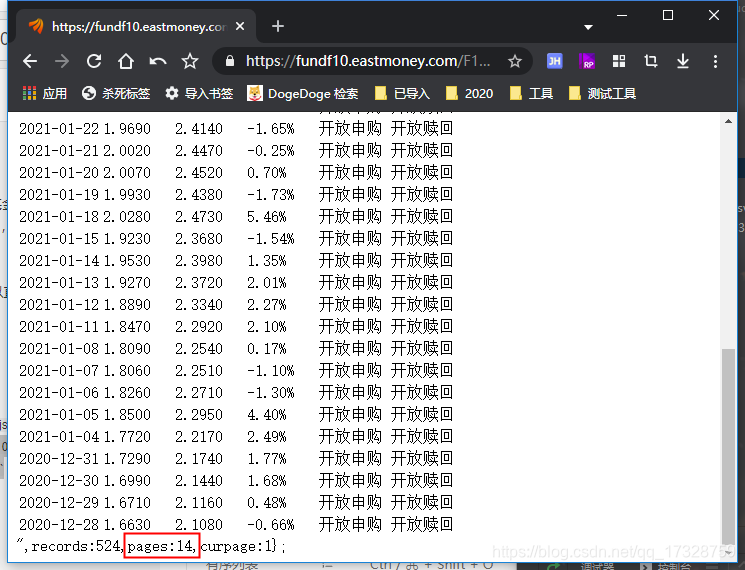
接口返回的数据最后可以看到共有14页的数据,需要使用一个循环读取所有的数据。pandas.read_html方法只能读取页面的表格数据,不能获取翻页数据,所以在调用pandas.read_html方法前,需要先获取所有数据的页数。url = f'https://fundf10.eastmoney.com/F10DataApi.aspx?type={type}&code={fundcode}&sdate={sdate}&edate={edate}&per={per}' res = requests.get(url) res_index = res.text.rindex('"') + 2 res = res.text.replace('};', '') res = res[res_index:] res = res.split(':') pages = int(res[-2].split(',')[0]) + 1
- 将获得的接口数据进行保存:
- 保存多个基金的估值数据。直接使用pandas.to_csv将数据保存。
# 创建一个名为 cls_name 的新数据类,字段为 fields 中定义的字段 FundData = make_dataclass('FundData', [('datetime', str),('fundcode', int), ('name', str), ('gszzl', float)]) # 实例化数据类 FundDataList = [] for fundcode in fundcodes : s = apiData(fundcode) # 填充数据类 FundDataList.append(FundData(time_, fundcode, s['name'], s['gszzl'])) # 将数据类保存的pandas.DataFrame data_DataFrame = pd.DataFrame(FundDataList) # 通过变量判断是否是第一次写数据,第一次写数据时带上表头 if count == 0: # 使用loggging打印日志 logging.debug('第一次写文件,保存列名') data_DataFrame.to_csv(f'funddatas{datetime.now().strftime("%Y%m%d")}.csv', mode='a+', index=False, header=True) else: logging.debug('不是第一次写文件,不保存列表') data_DataFrame.to_csv(f'funddatas{datetime.now().strftime("%Y%m%d")}.csv', mode='a+', index=False, header=False) - 保存基金历史单位净值数据。因为直接使用了pandas.read_html方法获取数据,所以不需要再次对接口数据进行处理,直接可以把数据使用pandas.to_csv方法存储到csv文件。在csv数据存储操作中,因为有翻页,需要添加循环读取数据,同时还需要判断文件是否是第一读取。
logging.info(f'数据写入{my_file}') for i in range(1, pages): url = f'https://fundf10.eastmoney.com/F10DataApi.aspx?type={type}&code={fundcode}&page={i}&sdate={sdate}&edate={edate}&per={per}' res = pd.read_html(url, encoding='utf-8')[0] if my_file.exists(): # 判断文件/目录是否存在 res.to_csv(my_abs_path, mode='a+', index=False, header=False) else: res.to_csv(my_abs_path, mode='a+', index=False)
- 保存多个基金的估值数据。直接使用pandas.to_csv将数据保存。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









