







简介
mongodb是基于分布式文件存储的数据库,由c++编写,为WEB应用提供可扩展的高性能数据存储解决方案。
mongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
mongodb优势
易扩展:数据之间没有关系,数据很容易扩展
大数据量,高性能:nosql数据库具有非常高的读写性能,尤其在大数据量的情况下。因为它是无关系性的,数据库的结构很简单
灵活的数据模式:nosql无需事先为要存储的数据建立字段,nosql随时可以定义存储的数据格式。而在mysql中增删字段是很麻烦的事情。
安装
1、ubuntu安装最新版本的MongoDB
sudo apt-get install -y mongodb-org
2、mac安装
a.进入 /usr/local
cd /usr/local
b.下载
sudo curl -O https://fastdl.mongodb.org/osx/mongodb-osx-ssl-x86_64-4.0.9.tgz
c. 解压
sudo tar -zxvf mongodb-osx-ssl-x86_64-4.0.9.tgz
d.重命名为 mongodb 目录
sudo mv mongodb-osx-x86_64-4.0.9/ mongodb
e.安装完成后,我们可以把 MongoDB 的二进制命令文件目录(安装目录/bin)添加到 PATH 路径中:
export PATH=/usr/local/mongodb/bin:$PATH
运行 MongoDB
1、首先我们创建一个数据库存储目录 /data/db:
sudo mkdir -p /data/db
2、启动 mongodb,默认数据库目录即为 /data/db:
sudo mongod
3、如果你的数据库目录不是/data/db,可以通过 --dbpath 来指定。
sudo mongod --dbpath=/data/db
mongodb数据类型
1、Object ID:文档ID。
每个文档都有一个_id属性,保证每个文档的唯一性。mongodb会为每个文档提供一个_id属性,类型为Object ID
Object ID是一个12字节的16进制数。前四个字节为当前时间戳;接下来的3个字节是机器id;接下来的两个字节是mongodb的服务进程id;最后3个字节是简单的增量值。
2、String: 字符串,必须是有效的utf-8
3、Boolean:存储布尔值,true或者false
4、Integer: 整数可以是32位或者64位,取决于服务器
5、Double: 存储浮点数
6、Arrays: 数组或者列表,多个值存储到一个键
7、Object:用于嵌入式文档,即一个值对应一个文档
8、Null:存储null值
9、Timestamp:时间戳,表示从1970-1-1到现在的总秒数
10、Date:存储当前日期或时间的UNIX时间格式。
创建日期
new Date(‘2017-12-05’)
数据库操作
查询所有的数据库
show dbs 或者show databases
查看当前的数据库
db
切换数据库
use new_db
数据库存在时切换数据库,不存在时新建数据库
删除当前的数据库
db.dropDataBase()
集合操作
mongodb的集合类似于mysql的表
创建集合
1、不需要手动创建集合,第一次写集合时集合会被自动创建出来
2、手动创建集合,命令:db.createCollection(name, options)
比如:db.createCollection(“stu_table” ,{capped:true,size:10})
capped=false 表示不设置上限;
capped=true 表示设置上限,需设置size大小。
size单位是"字节",超过限制后面的字节会将前面的字节更新掉。
类型于创建数据库表
查看集合
show collections
删除集合
db.集合名称.drop()
增删改查
新增数据
1、db.集合名.insert({“name”:“as”,“age”:10})
示例: db.test01.insert({“name”:“as”,“age”:10})
类似于在数据库表test01中新增了一条记录。
_id重复会报错
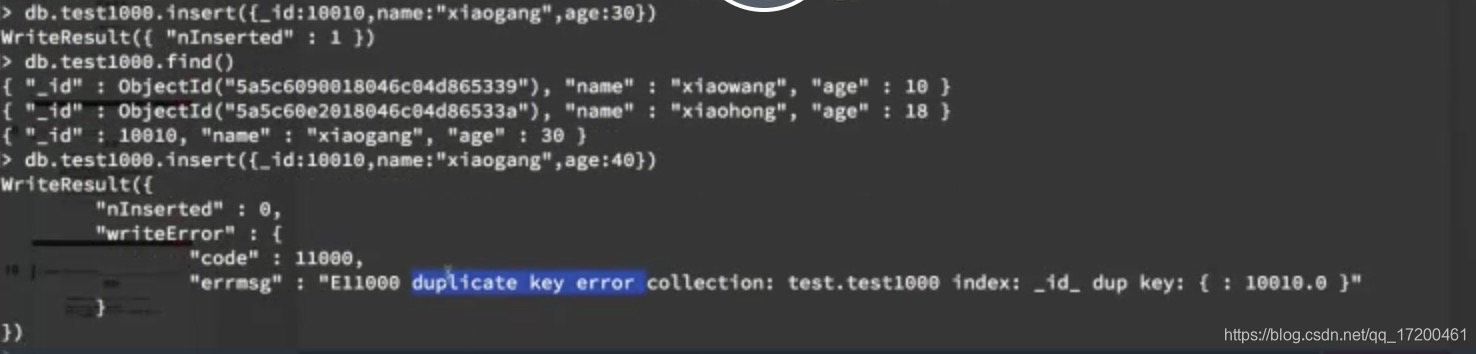
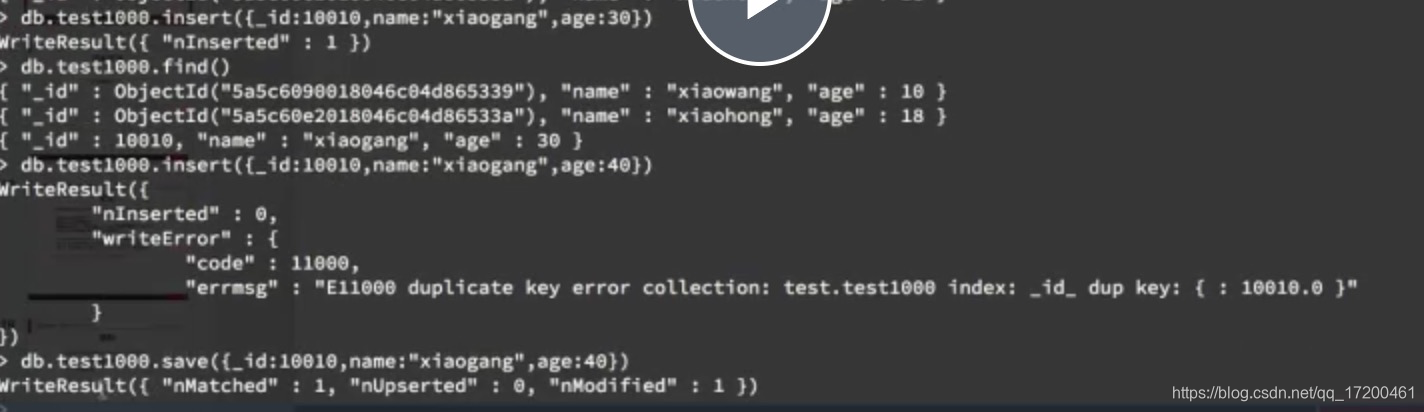
2、db.集合名.save({“name”:“as”,“age”:10})
和insert类似,不同之处在于_id一样时会修改记录的值,不会报错
删除数据
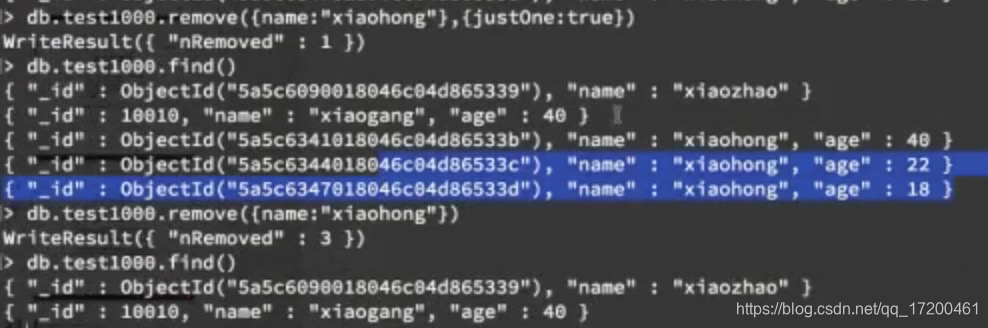
1、db.集合名.remove(条件,{justone:true})
db.test01.remove({name:“xiaoyg”})
2、justone=true或者1 ,则只删除一条数据;默认为false,可删除多条
更新数据
1、db.集合名.update(条件,更新内容),默认只更新一条数据。
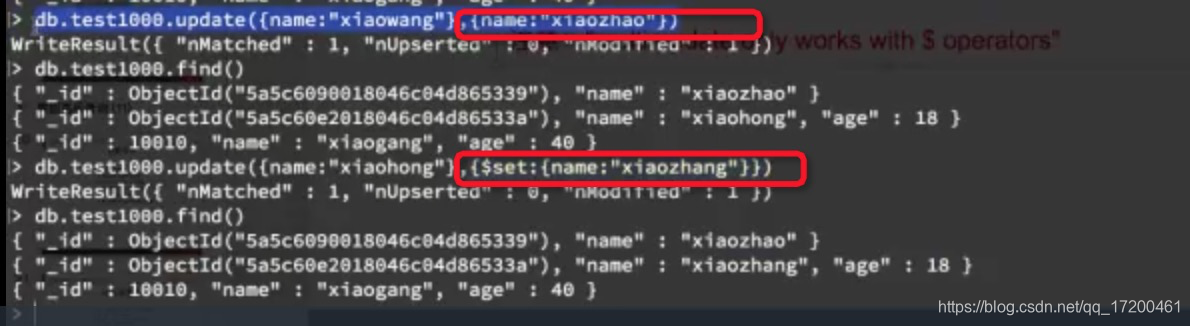
2、替换某条记录 {“name”,“xiaozhao”}
db.test01.update({“name”:“xiaoming”}, {“name”,“xiaozhao”})
会将name='xiaoming’的这条记录的值替换成{“name”,“xiaozhao”},原先的字段会丢失
3、更新某个字段的值 {KaTeX parse error: Expected 'EOF', got '}' at position 24: …me","xiaozhao"}}̲ db.test01.upda…set:{“name”,“xiaozhao”}})
$set 会指定修改某个字段的值。
4、更新全部数据 {multi:true}
db.test01.update({“name”:“xiaoming”}, {$set:{“name”,“xiaozhao”}, {multi:true}})
查找数据
1、find({条件文档})

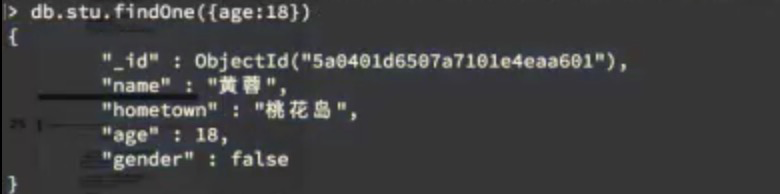
2、findOne() 查询,只返回第一条数据
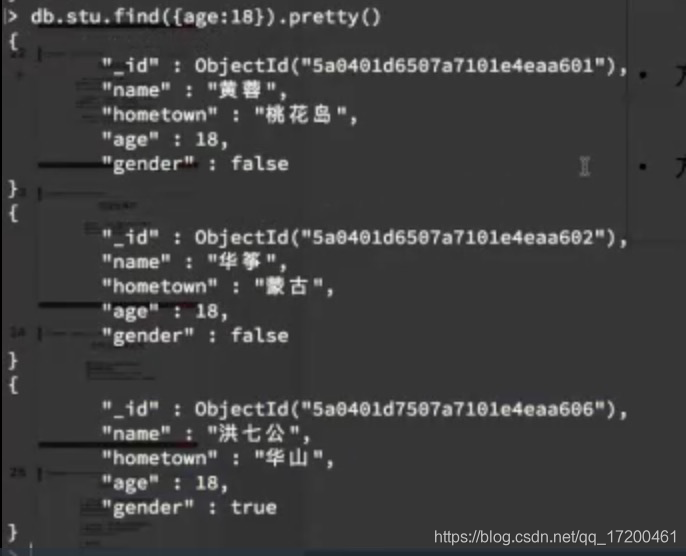
3、find.pretty() 将结果格式化,美化输出结果
高级查询
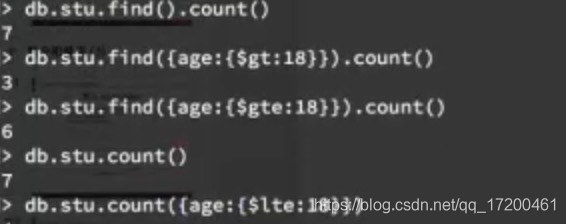
比较运算
| $lt小于 | $lte小于等于 | $gt大于 | $gte大于等于 | KaTeX parse error: Expected '}', got 'EOF' at end of input: …stu.find({age:{gte:18}})

范围运算
$in $nin

逻辑运算
$or ,默认是and

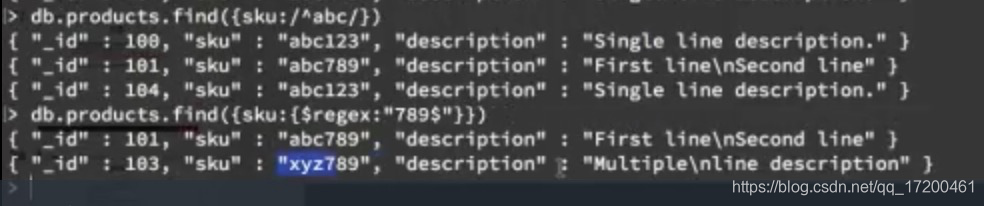
正则表达式
// 或者$regex
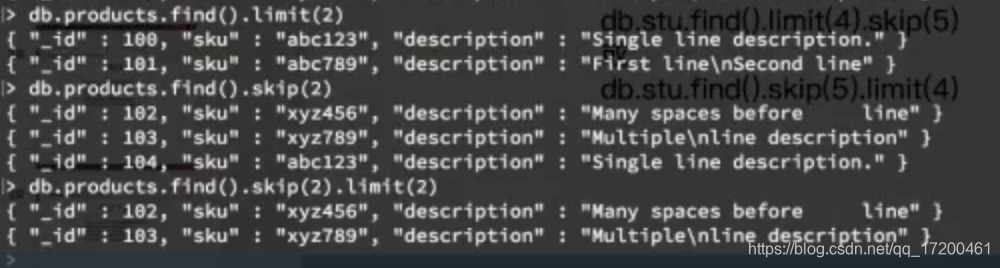
分页
limit() 用于读取指定数量的文档
skip() 用于跳过指定数量的文档
自定义查询
$where
db.student.find(
{
$where:function()
{return this.age>30;}
}
)
投影
在查询到的返回结果中,只选择必要的字段
db.集合名.find({},{字段名:1}) 1表示显示,0表示不显示。 _id默认为显示,如果需要不显示设置为_id:0

排序
sort() 1是升序,-1是降序
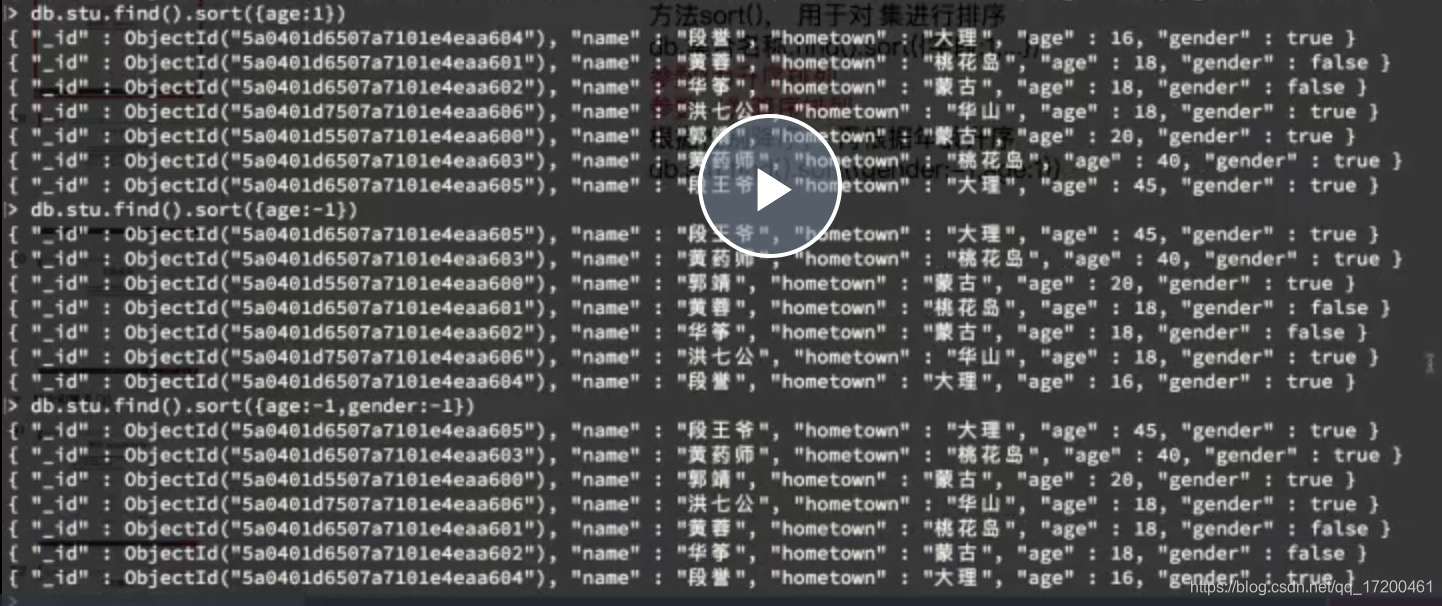
统计个数
count()
消除重复
db.集合名.distinct()
数据备份
mongodump -h dbhost:post -d dbname -o dbdirectory
-h:服务器地址,也可以指定端口号
-d:需要备份的数据库名称
-o: 备份的数据存放位置
数据恢复
mongorestore -h dbhost -d dbname —dir dbdirectory
-h: 服务器地址
-d :需要恢复的数据库实例
—dir:备份数据所在的位置
索引
· 索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
· 这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
· 索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
· 创建索引: db.collection.createIndex(keys, options)
· 示例:db.col.createIndex({“title”:1});
Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
· 复合索引示例:为多个字段设置索引
db.col.createIndex({“title”:1,“description”:-1})

1、查看集合索引
db.col.getIndexes()
2、查看集合索引大小
db.col.totalIndexSize()
3、删除集合所有索引
db.col.dropIndexes()
4、删除集合指定索引
db.col.dropIndex(“索引名称”)
聚合
· 聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
· 聚合的语法:db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









