




 本文详细介绍了HashMap的内部结构,包括数组+链表+红黑树的组合,以及Node节点的存储方式。讨论了关键参数如初始容量、加载因子、扩容临界值的作用,并阐述了构造函数的三种形式。重点解析了put方法中的hash算法和寻址算法,解释了为何容量必须为2的n次方以及如何通过位运算提高效率。此外,还提及了get、remove方法的工作原理,以及当链表长度达到8时转换为红黑树的情况。
本文详细介绍了HashMap的内部结构,包括数组+链表+红黑树的组合,以及Node节点的存储方式。讨论了关键参数如初始容量、加载因子、扩容临界值的作用,并阐述了构造函数的三种形式。重点解析了put方法中的hash算法和寻址算法,解释了为何容量必须为2的n次方以及如何通过位运算提高效率。此外,还提及了get、remove方法的工作原理,以及当链表长度达到8时转换为红黑树的情况。
1、底层结构是 数组 + 单向链表 + 红黑树 (jdk8之后),之前是数组 + 链表
底层是,用node节点组成的数组

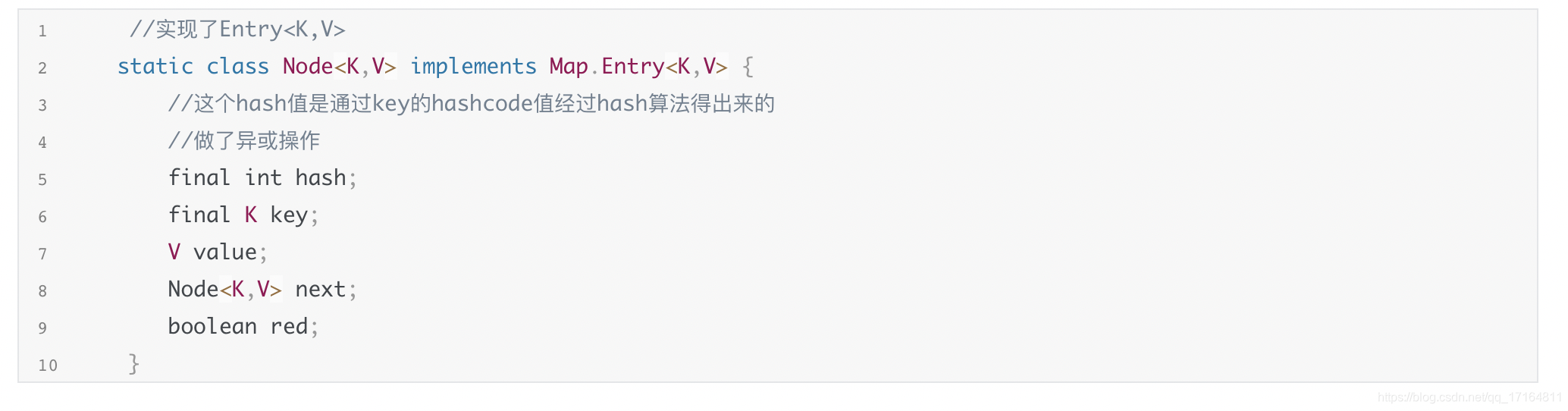
2、基于<key, value>对存储数据,数据会被封装成一个Node<K,V>节点,会存放它的hash值、key值、value值、next指针。
3、几个关键参数
- 初始容量

- 默认加载因子是0.75;

- 扩容临界值(容量*加载因子);
- 这个东西不只是干了这个事,还有另一个作用
- 在使用构造函数创建hashmap时,如果指定了容量,那构造函数里就要算出一个数来,必须是2的n次方 ,就是tableSizeFor方法。但是构造函数完成后也只是创建一个空数组,只有在第一次放数据时才会初始化容量,所以构造函数那里必须要保存计算出来的数。等到第一次放数据的时候用。threshold就是这个大小,构造函数阶段会算出这数的值。为什么用这个数保存数组大小,我觉得是作者觉得既然构造阶段数组没有初始化,那临界值也没什么意义,就临时当数组初始大小,等待put的时候给数组初始化,然后那时再回归他本身的意义,扩容临界值。

- size是集合当前大小

4、构造函数有三种
- 无参

- 一个参数

- 两个参数

5、put(K,V)方法,hash算法 和 hash寻址算法
- put的时候,先通过hash算法处理hashcode,然后通过寻址算法定位到该元素在数组的位置,然后判断应该放在数组还是链表或者红黑树中
- hash算法

-
- ps:hashcode是int型,4个字节,一个字节8个bit,一共32位
- 先定义个变量: key的hashcode右移 16位,其实就是把原来的hashcode值的高16位放到低16位,高16位补0。然后画图讲解:

-
- 相当于拿hashcode的低16为和高16位做异或操作(不一样的为1,一样的为0),让高16位也参与到运算中(正常来说集合的大小是不会特别大的,2的16次幂就6万多了,虽然hashmap允许的最大值是2的30次幂),所以,hash值的后16位90%的情况下都不会参与运算。但是现在高16位和低16位异或后,低16位就同时保留了高低两部分的特征,降低hash冲突。
- 为什么说可以降低hash冲突,因为如果两个key,解析的hashcode可能低16为一样的,但是如果这么异或一下,就不一样了
- 相当于拿hashcode的低16为和高16位做异或操作(不一样的为1,一样的为0),让高16位也参与到运算中(正常来说集合的大小是不会特别大的,2的16次幂就6万多了,虽然hashmap允许的最大值是2的30次幂),所以,hash值的后16位90%的情况下都不会参与运算。但是现在高16位和低16位异或后,低16位就同时保留了高低两部分的特征,降低hash冲突。
- 寻址算法:

-
- 寻址算法,会拿经过hash算法的hashcode 跟 (数组大小 - 1),做与操作,这样做相当于对数组大小取模,但是效率上要比取模高的多,直接做位运算省去了转成10进制的步骤,但是这么做有一个前提,集合大小必须是2的n次方
-
- 这里解释下为什么 只有集合大小是2的n次方,他们与操作才等同于取模
-
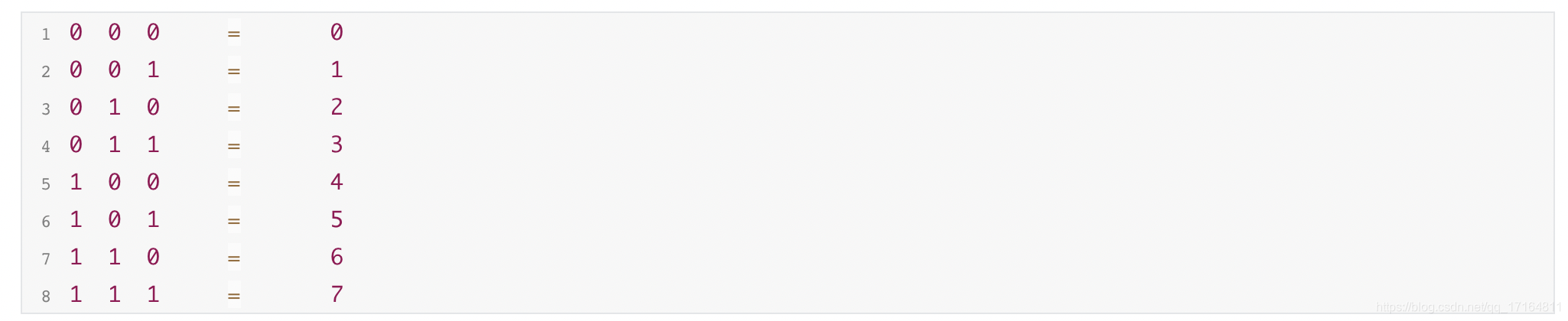
- 假设,数组大小为 (2的3次方 - 1 ) = 7
- 那么,二进制表示,就是 1 1 1
- 与操作的意思是,只有两边都是1,才是1
- 因为,数组大小为7,二进制 1 1 1,前面都是0补全的
- 那么,hashcode的二进制除了后3位,其他的就没意义了,因为要做与操作,而数组的前面都是0,不管hashcode前面是1还是0,都没有用,做完与操作就是0
- 那么hashcode的有效长度只有后三位,共有8种情况
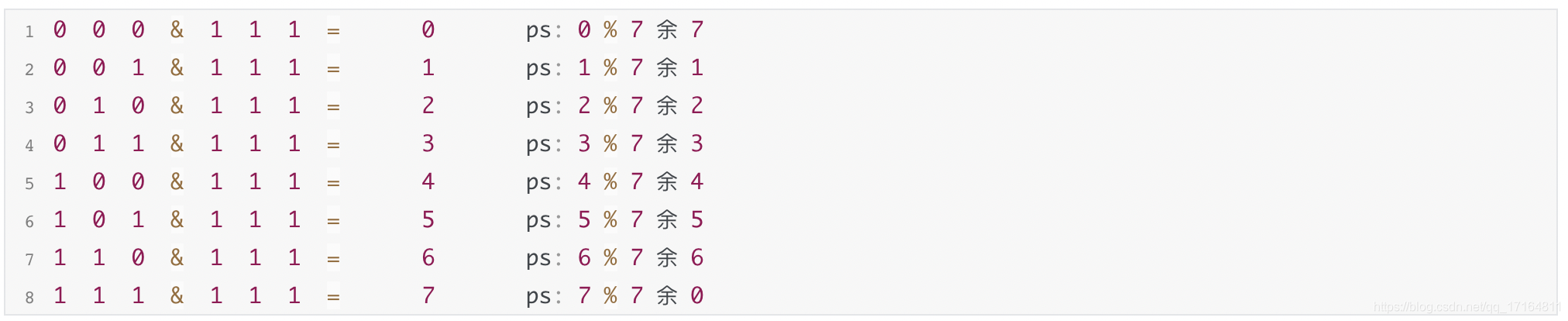
-
- 跟数组大小的二进制 1 1 1做与操作,那就是
-
- 发现没有,这样就跟取模是一个效果。
-
- 如果不设成2的n次方,那数组的二进制就有可能是 0 1 0 ,那hashcode的有效值就变成1位了,那数组中有的地方一直没元素,有的地方一直冲突
- 判断该元素存放在哪里
-
- 如果hash寻址之后,这个位置的元素为null,那么直接放里
- 如果这个位置的元素不为空,会走一个遍历,这个元素的.next,为null停
- 进入循环之后,先判断,hash值是否相等(即使hash值不相等,也可能定位到同一个位置),key的equals是否相等,如果满足这两个条件,说明这两个元素的key是一样的,直接替换掉,循环break
- 如果那两个条件不成立,说明hash冲突,那么会一直循环到最后一个元素,如果没有一个元素符合上述两个条件,那么最后一个元素的next指向本次插入的元素
- 本次put操作暂不考虑红黑树情况,下节讲,当链表的大小长度大于等于8的时候,会字段转换成红黑树
- 如果不转红黑树,当链表过长的时候,时间复杂度会变成O(n)
6、HashMap 如何保证容量一直是2的N次方,如果构造函数传的不是2的n次方呢?
- hashMap有一个tableSizeFor方法,会保证集合的容量是2的N次方,大小是比入参值大,并且离入参值最近的2的N次方那个数
- 如入参:0 容量:0
- 入参:1 容量:1
- 入参:2 容量:2
- 入参:3 容量:4
- 入参:4 容量:4
- 入参:5 容量:8
代码

- | ,或操作, 0和1,则为1
- >>> , 无符号右移(这个其实用 >> 和用 >>> 没什么区别)
- 第6行,自己右移一位和自己做或操作
- 第7行,自己右移两位和自己做或操作
- 第8行,自己右移4位和自己做或操作
- 一直到第10行,都是
- 那么,加起来,一共右移了35位
- 总结下,这个算法要做的事是啥,就是要把2进制的,把你从最高位开始,后面的全变成1,最后返回结果又加1,就变成2的n次方了
- 刚开始为什么要减一呢,就是为了临界值,如果你传的已经是2的n次方了,如果不减一,算出来的就是16了(把8的二进制,后面都变成1,结果又加1,就变成16了),如果减一,那就是7,把7的后面都变成1,再加1,那是8。所以最开始第5行,先减一
- 如果还没看懂看下面的
6、get(Key),hash寻址
hash寻址,寻址到了判断 hash值 和equals , 如果有链表和数再遍历
7、remove(Key)
寻址到了设为空,size--
8、红黑树是什么
红黑树.note
9、扩容
https://blog.youkuaiyun.com/u013494765/article/details/77837338
===========================下面为拓展=============================
转成红黑树后,会变成TreeNode

- JDK 1.7 的hashMap 在并发情况下导致死循环的问题

















 1187
1187




 到【灌水乐园】发言
到【灌水乐园】发言







