







1 介绍
-
Dice
https://en.wikipedia.org/wiki/Sørensen–Dice_coefficient
交集*2 除以 (并集+交集),最小为0,最大为1 -
jaccard
交集 除以 并集,最小为0,最大为1 -
Overlap
交集 除以 最小的那个面积,最小为0,最大为0 -
Intersection over Union (IoU)



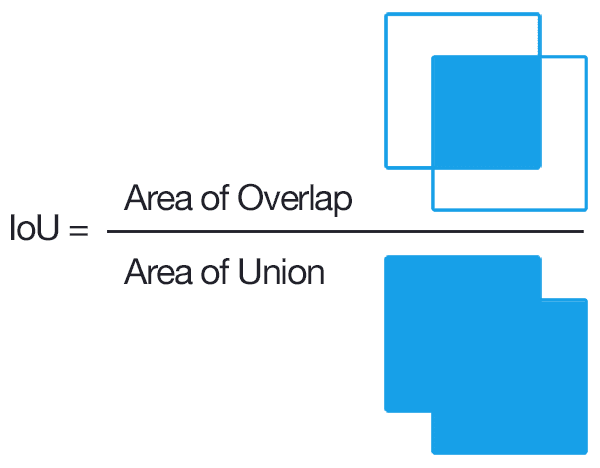
true positive / (true positive + false positive + false negative)
值的范围也是0到1,所以与jaccard系数的区别是什么?
事实上,iou就是jaccard?
下面提供了计算的方式
https://stackoverflow.com/questions/48260415/pytorch-how-to-compute-iou-jaccard-index-for-semantic-segmentation
kaggle评判规则解读
https://www.kaggle.com/pestipeti/explanation-of-scoring-metric
- 总体意思
不同iou阈值下的精度,例如iou=0.5时,满足这个iou>=0.5的,就代表被找到了,然后可以算出一个精度,这样,每一个iou的大小都大于0.9了,就代表iout=0.9是精度为1了,还是比较难达到的,所以可以看出这个mean iou还是可以衡量平均水平的,
参考:
https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
https://en.wikipedia.org/wiki/Overlap_coefficient
https://en.wikipedia.org/wiki/Sørensen–Dice_coefficient
https://en.wikipedia.org/wiki/Jaccard_index

















 726
726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









