







作业一:
第一步:下载KenLM或者SRILM工具,下载中文或英文10万个句子的语料库。
第二步:使用KenLM或SRILM工具,跑出自己的语言模型,将输出的概率表截图粘贴到word文档中。
第三步:从下载的语料库中选择20个句子(自己造句也行),比较手算概率和模型自动计算概率的差别。
在Kenlm初步使用----评估句子中"a/an"使用情况一文,已经介绍了关于kenlm的初步情况,这里就直接给出作业代码(个人比较懒,所以就没有手算概率,利用代码完成了,句子没给够20句)
import kenlm
import string
import math
path = "res_2.arpa"
contents = [
"Every story has an end, but in life, every end is a new beginning.",
"The worst way to miss someone is to be sitting right beside them knowing you can’t have them",
"Better to light one candle than to curse the darkness."
"Success is going from failure to failure without losing enthusiasm",
]
def pro(path):
model = kenlm.Model(path)
fp = open("output.txt", "w+", encoding="utf-8")
for i in range(len(contents)):
fp.write("第{}题:\r\n".format(i + 1))
# 提取内容中的句子,并统一小写、去除标点符号、切分单词形成列表
sentence = contents[i].lower().strip(string.punctuation)
# print('P1('+contents[i]+')=',model.score(sentence))
line = "P1(" + contents[i] + ")=" + str(model.score(sentence)) # 模型算的概率
fp.write(line + "\r\n")
sentence = "".join(k for k in sentence if k not in string.punctuation)
# 概率
pros = [score for score, _, _ in model.full_scores(sentence)]
sentence_list = sentence.split()
sentence_list = ["<s>"] + sentence_list + ["</s>"]
# 最大的单词长度
length = len(max(sentence_list, key=len))
# p2输出字符串
p2 = ""
for j in range(len(sentence_list) - 1):
p_b_a = (
"p("
+ sentence_list[j + 1].rjust(length)
+ "|"
+ sentence_list[j].ljust(length)
+ ")"
)
p_ab = "p(" + sentence_list[j + 1] + "|" + sentence_list[j] + ")"
# 打印 p (b | a)
# print(p_b_a,' = ','{:.10f}'.format(math.pow(10,pros[j])))
line = p_b_a + " = " + "{:.10f}".format(math.pow(10, pros[j]))
fp.write(line + "\r\n")
if j == 0:
p2 = p_ab
else:
p2 += "*" + p_ab
# print('P2('+contents[i]+')=',p2,'=',math.pow(10,sum(pros)))
line = (
"P2(" + contents[i] + ")=" + p2 + "=" + str(math.pow(10, sum(pros)))
) # 手动概率
fp.write(line + "\r\n")
line = "PPL(" + contents[i] + ")=" + str(model.perplexity(contents[i])) # 困惑度
fp.write(line + "\r\n\r\n")
# print()
fp.close()
pro(path)
效果图:
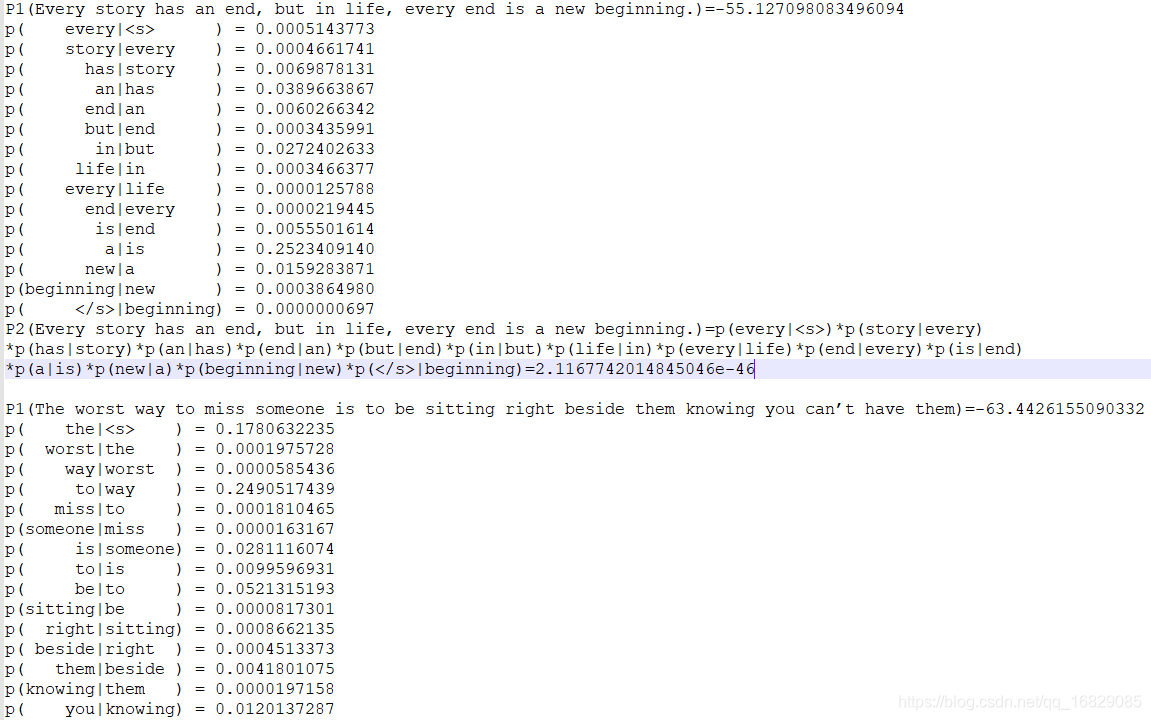
作业二:
使用Python,实现困惑度的计算。
import jieba
import string
# 把句子变成<BOS>...<EOS>的形式
def addIdentifier(sentence):
if sentence.endswith('。'):
sentence = sentence[:-1]
# 添加标志符
sentence = sentence.replace("。", 'EOSBOS')
sentence = 'BOS' + sentence + 'EOS'
return sentence
# 统计1-gram和2-gram词频
def wordFrequency(sentence, one_gram_dict, two_gram_dict):
# 判断dicts是否传入字典
if not isinstance(one_gram_dict, dict) or not isinstance(
two_gram_dict, dict):
raise Exception('one_gram_dict and two_gram_dict need be a dict')
jieba.suggest_freq("BOS", True)
jieba.suggest_freq("EOS", True)
# 分词
word_lists = list(jieba.cut(sentence, HMM=False))
# 过滤
for v in word_lists:
if v in string.punctuation:
word_lists.remove(v)
length = len(word_lists)
# 统计词频
for i, k in enumerate(word_lists):
one_gram_dict[k] = one_gram_dict.get(k, 0) + 1
if i < length - 1:
two_word = ''.join(word_lists[i:i + 2])
two_gram_dict[two_word] = two_gram_dict.get(two_word, 0) + 1
return word_lists
def perplexity(sentence, one_gram_dict, two_gram_dict):
sentence_cut = list(jieba.cut(sentence))
# 去除BOS
V = len(one_gram_dict) - 1
sentence_len = len(sentence_cut)
p = 1 # 概率初始值
k = 1 # ngram 的平滑值,平滑方法:Add-1 Smoothing
for i in range(sentence_len - 1):
two_word = "".join(sentence_cut[i:i + 2])
p *= (two_gram_dict.get(two_word, 0) +
k) / (one_gram_dict.get(sentence_cut[i], 0) + k * V)
return pow(1 / p, 1 / sentence_len)
# 基于2-gram求句子困惑度
def main():
# 语料库
corpus = "John read Moby Dick。Mary read a different book。She read a book by Herman。"
corpus_ifi = addIdentifier(corpus)
one_gram_dict, two_gram_dict = {}, {}
wordFrequency(corpus_ifi, one_gram_dict, two_gram_dict)
sentence = 'Mary read Moby Dick by Herman'
per = perplexity(sentence, one_gram_dict, two_gram_dict)
print(per)
if __name__ == "__main__":
main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









