







压缩列表ziplist本质上就是一个字节数组,是Redis为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数。Redis的有序集合、散列和列表都直接或者间接使用了压缩列表。当有序集合或散列表的元素个数比较少,且元素都是短字符串时,Redis便使用压缩列表作为其底层数据存储结构。列表使用快速链表(quicklist)数据结构存储,而快速链表就是双向链表与压缩列表的组合。
例如,使用如下命令创建一个散列键并查看其编码。
127.0.0.1:6379> hmset person name zhangsan gender 1 age 22
OK
127.0.0.1:6379> object encoding person
"ziplist"压缩列表的存储结构
Redis使用字节数组表示一个压缩列表,压缩列表结构示意如下图所示。

各字段的含义如下:
- zlbytes:压缩列表的字节长度,占4个字节,因此压缩列表最多有232-1个字节。
- zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节。
- zllen:压缩列表的元素个数,占2个字节。zllen无法存储元素个数超过65535(216-1)的压缩列表,必须遍历整个压缩列表才能获取到元素个数。
- entryX:压缩列表存储的元素,可以是字节数组或者整数,长度不限。entry的编码结构将在后面详细介绍。
- zlend:压缩列表的结尾,占1个字节,恒为0xFF。
假设char * zl指向压缩列表首地址,Redis可通过以下宏定义实现压缩列表各个字段的存取操作。
/* 返回ziplist的总字节数。 */
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
/* 返回ziplist中最后一个项的偏移量。 */
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
/* 返回ziplist的长度,如果无法确定长度,则返回UINT16_MAX。 */
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
/* ziplist头的大小:两个32位整数用于表示总字节数和最后一个项的偏移量。一个16位整数用于表示项数字段。 */
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
/* "end of ziplist"条目的大小,只有一个字节。 */
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
/* 返回ziplist的第一个条目指针。 */
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
/* 使用ziplist头中最后一条条目的偏移量,返回ziplist的最后一条条目指针。 */
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
/* 返回ziplist的最后一个字节的指针,即end of ziplist FF条目的指针。 */
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-ZIPLIST_END_SIZE)了解了压缩列表的基本结构,我们可以很容易地获得压缩列表的字节长度、元素个数等,那么如何遍历压缩列表呢?对于任意一个元素,我们如何判断其存储的是什么类型呢?我们又如何获取字节数组的长度呢?回答这些问题之前,需要先了解压缩列表元素的编码结构,如下图所示。

previous_entry_length字段表示前一个元素的字节长度,占1个或者5个字节,当前一个元素的长度小于254字节时,用1个字节表示;当前一个元素的长度大于或等于254字节时,用5个字节来表示。而此时previous_entry_length字段的第1个字节是固定的0xFE,后面4个字节才真正表示前一个元素的长度。假设已知当前元素的首地址为p,那么p-previous_entry_length就是前一个元素的首地址,从而实现压缩列表从尾到头的遍历。
encoding字段表示当前元素的编码,即content字段存储的数据类型(整数或者字节数组),数据内容存储在content字段。为了节约内存,encoding字段同样长度可变。压缩列表元素的编码如下表所示。
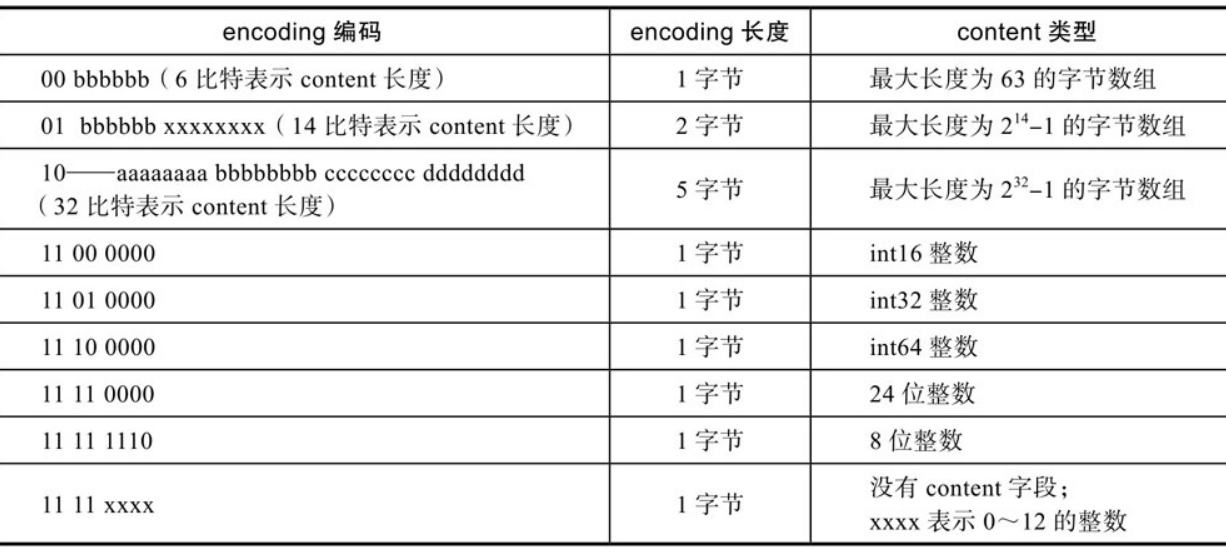
可以看出,根据encoding字段第1个字节的前2位,可以判断content字段存储的是整数或者字节数组(及其最大长度)。当content存储的是字节数组时,后续字节标识字节数组的实际长度;当content存储的是整数时,可根据第3、第4位判断整数的具体类型。而当encoding字段标识当前元素存储的是0~12的立即数时,数据直接存储在encoding字段的最后4位,此时没有content字段。参照encoding字段的编码表格,Redis预定义了以下常量对应encoding字段的各编码类型:
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe结构体
我们发现对于压缩列表的任意元素,获取前一个元素的长度、判断存储的数据类型、获取数据内容都需要经过复杂的解码运算。解码后的结果应该被缓存起来,为此定义了结构体zlentry,用于表示解码后的压缩列表元素。
/* 我们使用这个函数来获取ziplist实体信息。
* 注意,数据实际上并不是这样编码的,这只是我们通过一个函数填充的信息,以便更轻松地操作。 */
typedef struct zlentry {
unsigned int prevrawlensize; /* 编码前一个条目长度所使用的字节数*/
unsigned int prevrawlen; /* 前一个条目长度。 */
unsigned int lensize; /* 编码该条目类型/长度所使用的字节数。
例如字符串具有1、2或5个字节的头部。整数始终使用一个字节。*/
unsigned int len; /* 用于表示实际条目的字节数。
对于字符串,这只是字符串长度,而对于整数,则取决于数字范围,可以是1、2、3、4、8或0(对于4位立即数)。 */
unsigned int headersize; /* prevrawlensize + lensize。 */
unsigned char encoding; /* 根据条目的编码方式,设置为ZIP_STR_*或ZIP_INT_*。
然而,对于4位立即数,它可以假设一系列值并需要进行范围检查。 */
unsigned char *p; /* 指向条目的起始位置的指针,即指向prev-entry-len字段。 */
} zlentry;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









