




 文章讲述了GPT3作为生成式模型的特性,如Zero-shot、One-shot和Few-shot学习模式,并指出其可能存在的问题。ChatGPT的出现是为了解决GPT3的局限性,通过有监督学习和强化学习进行优化,提高模型的对话理解和任务执行能力。强化学习在这里用于调整模型输出,使其更符合人类期望,而奖励模型则用来评估输出的质量。此外,文章还讨论了模型的泛化能力和不同训练策略的效果。
文章讲述了GPT3作为生成式模型的特性,如Zero-shot、One-shot和Few-shot学习模式,并指出其可能存在的问题。ChatGPT的出现是为了解决GPT3的局限性,通过有监督学习和强化学习进行优化,提高模型的对话理解和任务执行能力。强化学习在这里用于调整模型输出,使其更符合人类期望,而奖励模型则用来评估输出的质量。此外,文章还讨论了模型的泛化能力和不同训练策略的效果。
承接上文GPT前2代版本简介
GPT3的基本思想
GPT2没有引起多大轰动,真正改变NLP格局的是第三代版本。
GPT3训练的数据包罗万象,上通天文下知地理,所以它会胡说八道,会说的贼离谱,比如让你穿越到唐代跟李白对诗,不在一个频道上,他说的你理解不了,你说的他理解不了。
GPT3太泛了,把世界上所有的东西都给训练了,不受约束条件的、无法无天,给它发一个指令,它抗拒指令,按照自己的思维模式去做,比如我问一个问题,接下来你用python代码的方式来回答我,它可能不按照这个模式来,不受我的约束。
这就是GPT3,不按照我们自己的思维去做我们自己的事情,也是给后面的ChatGPT做了一个铺垫。
GPT3 三种模式对比
-
Zero-shot
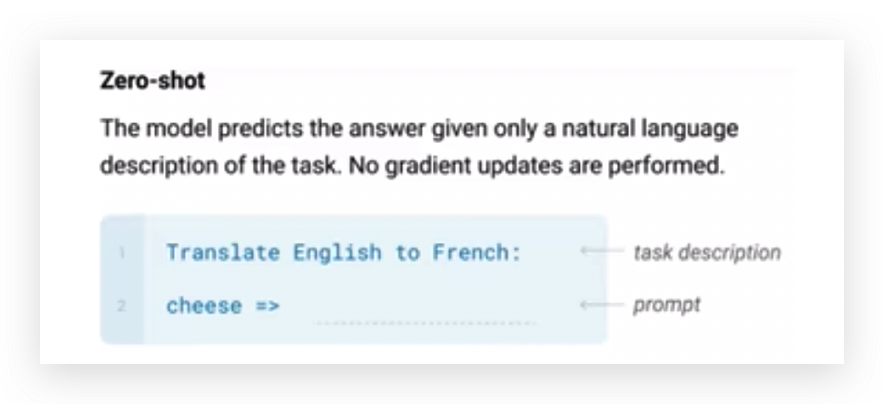
不管我输入什么,后面都会加上提示,比如把英文转换成法语,接下来就输出了法语。
-
One-shot

为了让它更好的理解我说的意思,我给它举了一个例子。
举一个例子,这个例子作为输入,我让你干什么,我给你举一个例子,你回答的时候可以参考这个例子。
这些例子都是我写到输入对话框中,一起给到模型,模型基于我写的例子,再往下输出。
-
Few-shot
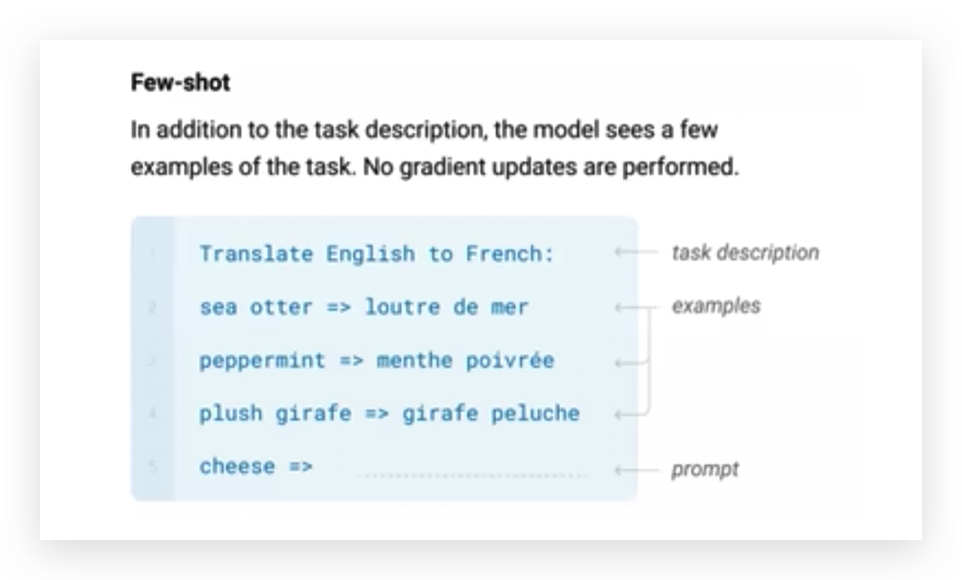
Few-shot是举多个例子。
这就是GPT3的基本思想。
Few-shot像在下游任务中又做了个简单的训练,比如举了三个例子,即三条数据,相当于把下游任务融入到了这个任务当中。
GPT3本质上还是一个生成式模型,它不需要下游任务,下游任务可以放到Few-shot或放到One-shot中。
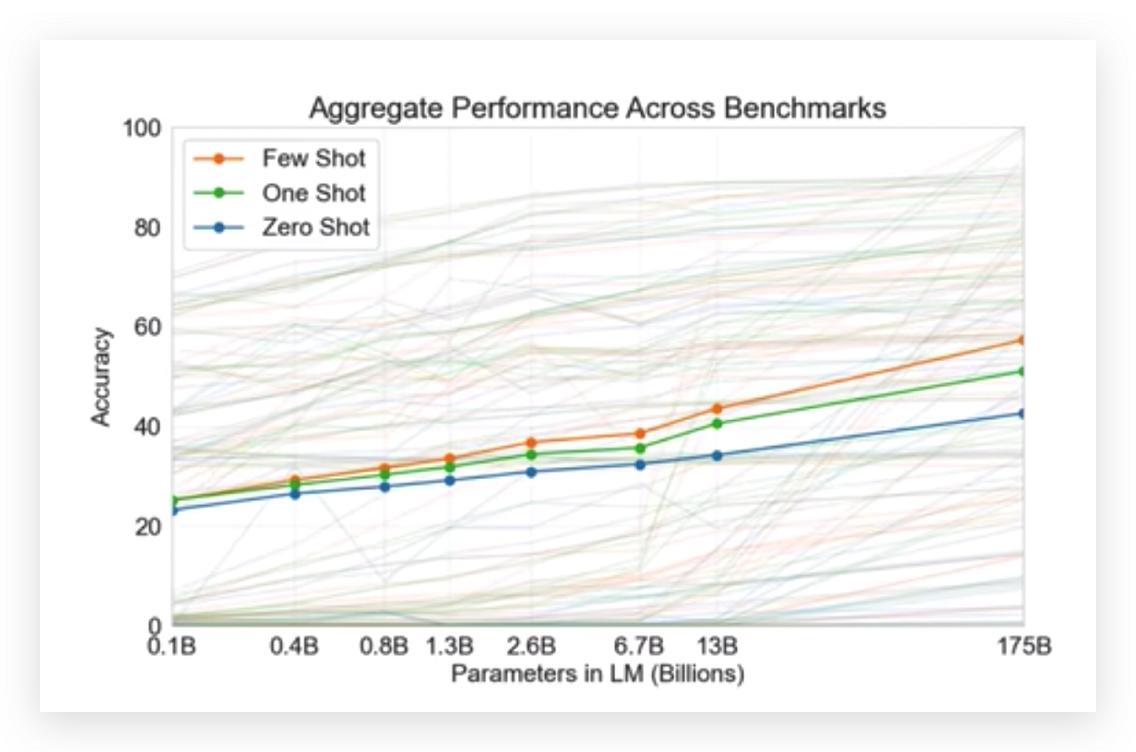
横轴表示语言模型的大小, One-shot和Few-shot之间还是存在差异的,尤其是模型越大的时候,差异越明显,Few-shot效果更好一些。
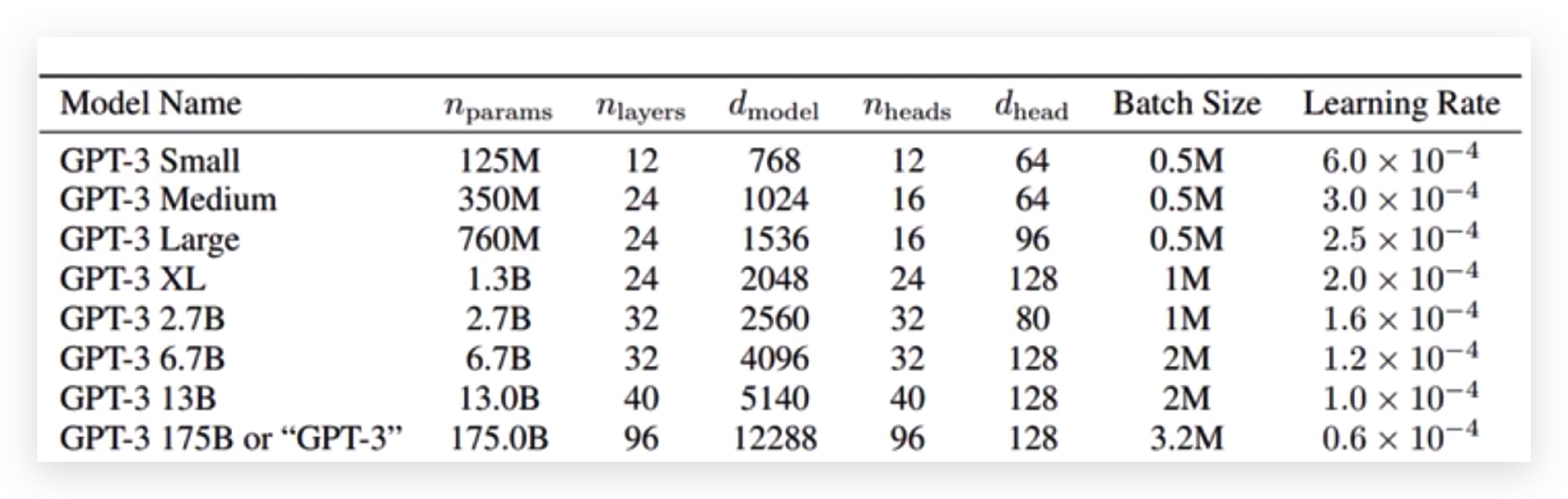
GPT3网络结构没有什么亮眼的,就是把Transformer做的更大了。
NLP哪家强,就看谁的模型更大,谁的数据更多。
OpenAI训练的GPT-3 1750亿个权重参数,每批次的训练数据大小是3.2M,这么大的量级,目前只有OpenAI大型GPU集群才能玩的转。<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









