







 本文深入探讨HBase的存储机制,解析其如何通过RowKey字典排序和横向切割技术,将大规模数据有效分散于集群中。揭示不同ColumnFamily数据独立存储的特性,以及HBase如何支持数据多版本管理。
本文深入探讨HBase的存储机制,解析其如何通过RowKey字典排序和横向切割技术,将大规模数据有效分散于集群中。揭示不同ColumnFamily数据独立存储的特性,以及HBase如何支持数据多版本管理。
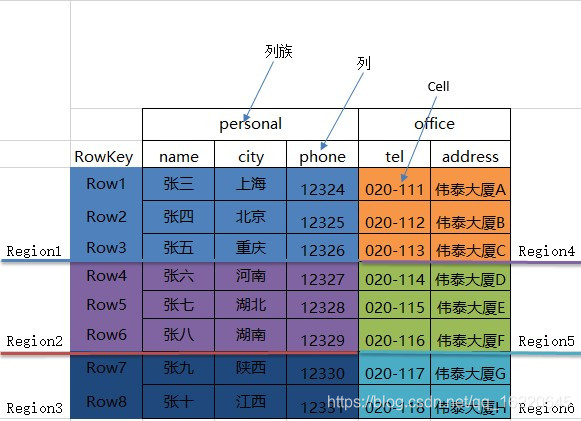
从上图可以明显看出,这张表有两个Column Family,分别为personal和office。而personal又有三列name、city以及phone;office有两列tel和address。由于存储在HBase里面的表一般有上亿行,所以HBase表会对整个数据按照RowKey进行字典排序,然后再对这张表进行横向切割。切割出来数据是存储在Region里边,而不同的Column Family虽然属于一行,但是其在底层存储是放在不同的Region中。也就是说,这张表的数据会被放在六个Region里边,尽可能的把数据分散到整个集群中。
总结来说:
- 数据是以kv形式存储
- 每个kv只存储一个cell里边的数据
- 不同CF的数据是存在不同的文件里边
HBase的KV结构其中K包括RowLength、Row Key、CF Length、CF、Column Qualifier、TimeStamp、Key Type;V包括Value

HBase其实是多版本的,如果我们修改了HBase表的一列,如果将上图中Row1的city列上海修改成广东、如果使用KV表示的话,我们可以看出其实底层存储了两条数据,这两条数据的版本是不一样的,最新的一条数据版本比之前的新。总结起来就是:
- HBase支持数据多版本特性,通过带有不同时间戳的多个KeyValue版本来实现的
- 每次put、delete都会产生一个新的cell,都拥有一个版本
- 默认只存放数据的三个版本,可以配置
- 查询默认返回最新版本的数据,可以通过制定版本号或者版本数来获取旧数据
参考出处微信公众号:过往记忆大数据
你的鼓励是我分享技术最大的动力!如有错误之处,请指正,不胜感激。

















 1403
1403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









