







(本文为流风有光的博客原创,转载请注明出处。)
在同样的算法复杂度内,如何让你的代码更快?
以下为一道力扣算法题,从最开始的7ms运行时间,最终优化到了1ms。
速度,在细枝末节之间。
请看以下题目(力扣151题)
151. 反转字符串中的单词
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = " the sky is blue "
输出:“blue is sky the”
进阶:如果字符串在你使用的编程语言中是一种可变数据类型,请尝试使用 O(1) 额外空间复杂度的 原地 解法。
如果不考虑进阶解法,这实际上是一个简单题。
很快就能得出一个java解法:
public String reverseWords(String s) {
String[] split = s.trim().split("\\s+");
StringBuilder sb = new StringBuilder(s.length()+1);
for (int i = split.length - 1; i >= 0; i--) {
sb.append(split[i]).append(" ");
}
sb.setLength(sb.length() - 1);
return sb.toString();
}
easy!
代码优雅简洁,考虑到split的复杂度,此题为O(n)复杂度算法,从算法复杂度来说,这已经是最优解。
提交之后:
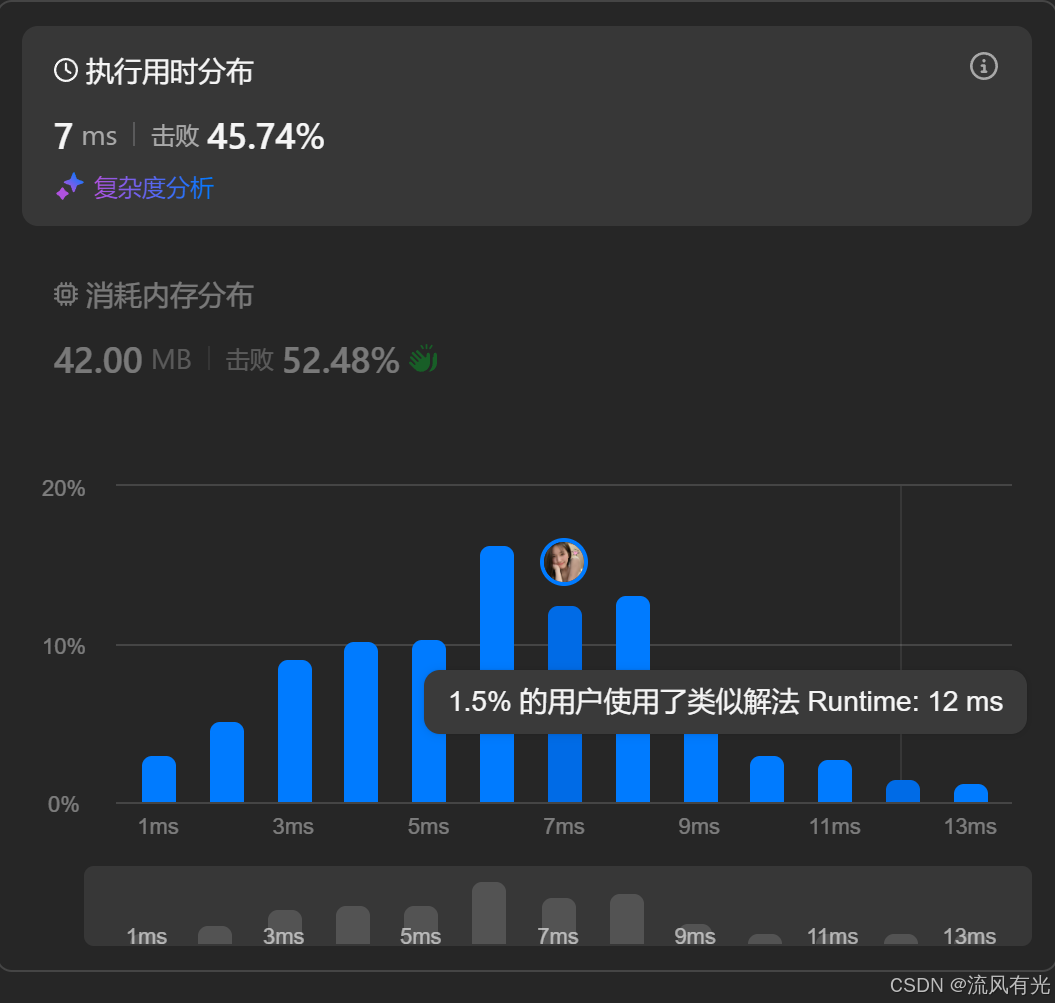
头顶上瞬间冒出了好几个问号,最快的runtime可以达到1ms,但以上的算法却耗时7ms。
很快,我就意识到了这是split分割算法的问题。
涉及到了正则表达式和生成新的字符串,这中间必定消耗了不少时间。
想要进一步优化算法,就必须替换掉split函数。
对于这题来说,并不太困难。
只需要检测空格并加以区分就可以了。
以下为优化之后的算法:
public String reverseWords(String s) {
int length = s.length();
StringBuilder sb = new StringBuilder(length);
// 记录单词的最后一个字符
Integer end = null;
for (int i = length - 1; i > 0; i--) {
if (end == null && s.charAt(i) != ' ') {
end = i;
} else if (end != null && s.charAt(i) == ' ') {
// 单词读取完毕,将其切割放入StringBuilder
if (sb.length() > 0) {
sb.append(s, i, end + 1);
} else {
sb.append(s, i + 1, end + 1);
}
end = null;
}
}
if (s.charAt(0) != ' ') {
if (sb.length() > 0) {
sb.append(' ');
}
if (end == null) {
end = 0;
}
sb.append(s, 0, end + 1);
} else if (end != null) {
if (sb.length() > 0) {
sb.append(' ');
}
sb.append(s, 1, end + 1);
}
return sb.toString();
}
以上算法的复杂度同样是O(n),
区别就是自己实现了split并直接将结果记录在StringBuilder中,这样就不需要重新记录子串。
考虑到每次sb.append(s,start, end )方法都需要进行回溯。所以实际上相当于遍历了两遍字符串——但是从这题来说,这几乎是必须的。
以下为运行时间:
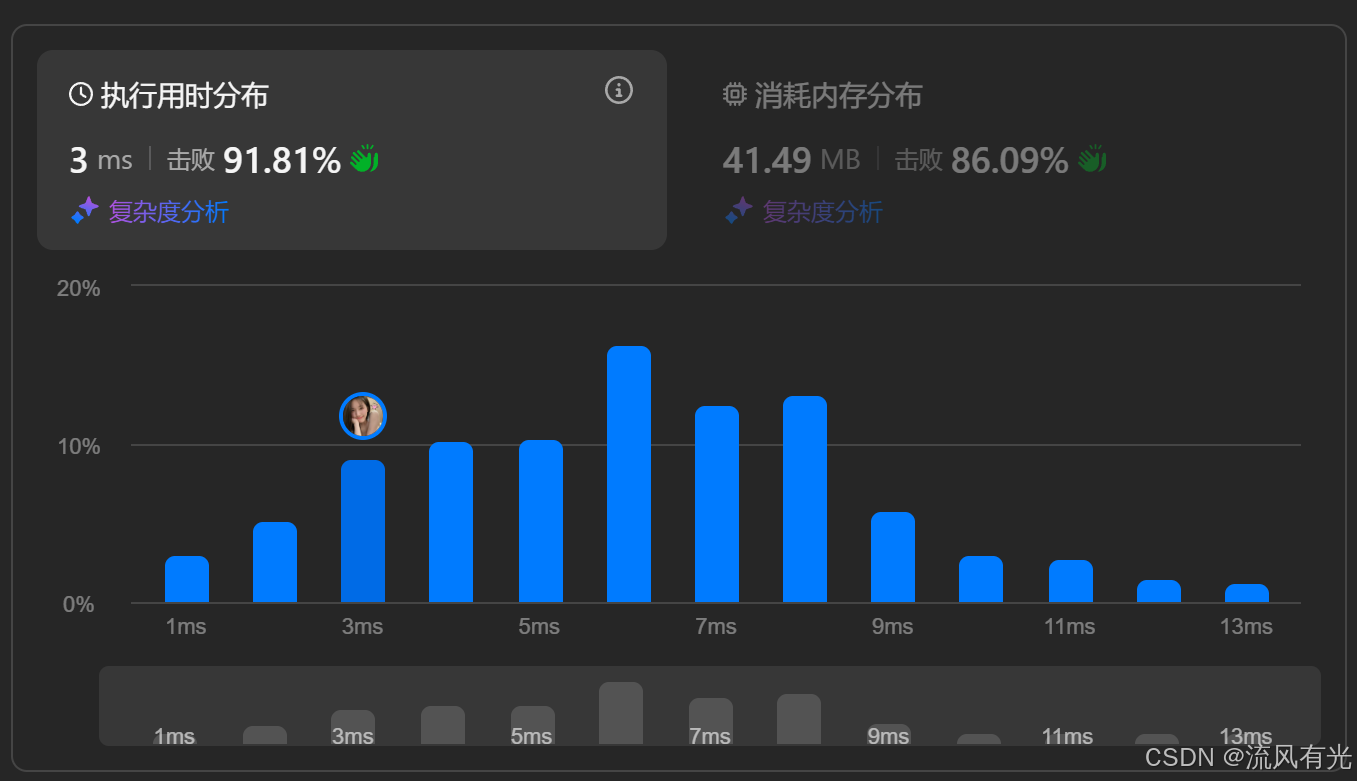
可喜可贺。
我们的优化生效了,从7ms的时间缩短至3ms,击败了91%的提交者。
降低时间消耗的关键就是我们识别了复杂度为O(n)的封装算法,用更高效的写法代替。
但是问题来了,已经优化至此,依旧花费了3ms,那1ms的家伙到底是怎么写的呢?
以下为runtime 1ms的代码:
public String reverseWords(String s) {
char[] oldArr = s.toCharArray();
int oldLen = oldArr.length;
char[] newArr = new char[oldLen + 1];
int newIndex = 0;
// 从后向前遍历
for (int i = oldLen - 1; i >= 0; i--) {
// 先找到数字字符位置
while (i >= 0 && oldArr[i] == ' ') {
i--;
}
// 将单词末尾记录下来
int index = i;
// 往前走到空格位置
while (i >= 0 && oldArr[i] != ' ') {
i--;
}
// 此时i指向空格, i的下一个是单词开始
// 将这个单词, 放入新数组
for (int j = i + 1; j <= index; j++) {
newArr[newIndex] = oldArr[j];
// 加完一个单词后, 在后面加个空格
if (j == index) {
newIndex++;
newArr[newIndex] = ' ';
}
newIndex++;
}
}
if (newIndex == 0) {
return "";
}
return new String(newArr, 0, newIndex - 1);
}
说实话。
当我看到程序的时候我是很不理解的,为什么这段代码的运行时间只需要1ms?
我不理解的原因有三个:
第一,这一段代码的思路跟我上一段3ms的代码几乎一致:倒序遍历,找到单词结尾和开头,然后将单词记录下来。
第二,这段代码开头用了s.toCharArray()方法,这是一个复杂度为O(n)的方法。且会造成额外的空间开销,
第三,这一段代码使用newArr 记录新字符串,我用StringBuilder sb = new StringBuilder(length);记录字符串,本质上没有区别,因为StringBuilder 的成员变量就包含了一个数组,而我为StringBuilder指定了初始容量,这代表不涉及扩容问题。
当我再次仔细思考之后,终于发现了问题:
1、由于同样是复杂度O(n)的算法,所以s.toCharArray()的O(n)复杂度相当于在循环里面多加了一条赋值语句,对性能影响没有想象中大。
2、1ms的算法用了while语句块快速跳过空格和单词部分,大大减少了判断所需要的时间。
3、String.chatAt()方法每次都会判断越界条件,造成了不必要的性能损耗。使用数组可以很好的规避这一点。
public char charAt(int index) {
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
现在,我们完全借鉴1ms算法的思路重写:
static class Solution {
public String reverseWords1(String s) {
int length = s.length();
char[] chars = s.toCharArray();
char[] ans = new char[length+1];
int end;
int size = 0;
for (int i = length - 1; i > -1; i--) {
//跳过空格获取结尾
while (i > -1 && chars[i] == ' ') {
i--;
}
if (i < 0) {
break;
}
end = i;
//跳过字母获取开头
while (i > -1 && chars[i] != ' ') {
i--;
}
// 将单词设值
for (int j = i+1; j <= end; j++) {
ans[size++] = chars[j];
}
// 单词后加上空格
ans[size++] = ' ';
}
if(size == 0) {
return "";
}
// 去掉最后的空格
return new String(ans,0,size-1);
}
public String reverseWords2(String s) {
int length = s.length();
char[] chars = s.toCharArray();
StringBuilder sb = new StringBuilder(length+1);
int end;
for (int i = length - 1; i > -1; i--) {
//跳过空格获取结尾
while (i > -1 && chars[i] == ' ') {
i--;
}
if (i < 0) {
break;
}
end = i;
//跳过字母获取开头
while (i > -1 && chars[i] != ' ') {
i--;
}
// 将单词设值并在后加上空格
sb.append(chars, i + 1, end - i).append(" ");
}
sb.setLength(sb.length() - 1);
return sb.toString();
}
}
reverseWords1几乎与1ms算法一致,
而reverseWords2则是使用了StringBuilder 代替数组,其他与reverseWords1方法一致。(由于为StringBuilder 设定了足够的初始容量,所以认为append过程中不会产生扩容问题)
提交力扣,
reverseWords1的时间消耗为1ms.
reverseWords2的时间消耗为2ms
对算法进行测试:
public static void main(String[] args) {
Solution s = new Solution();
String s1 = "a good example";
String s2 = " a good example";
String s3 = "a good example ";
String s4 = " a good example ";
long start = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
s.reverseWords1(s1);
s.reverseWords1(s2);
s.reverseWords1(s3);
s.reverseWords1(s4);
}
System.out.println(System.currentTimeMillis() - start);
}
| 测试序号 | 1 | 2 | 3 |
|---|---|---|---|
| reverseWords1 | 24ms | 23ms | 24ms |
| reverseWords2 | 39ms | 36ms | 43ms |
由此可见,调用StringBuilder.append()即使没有涉及扩容问题,但是由于额外的判断和方法调用开销,依旧造成了不小的性能损耗。
总结
1、相同的复杂度,实际性能差距仍然可能成倍数。
2、调用方法库中的方法,可能会导致额外的开销,性能敏感时需要额外小心。例如String的charAt和split方法。
3、方法调用和额外判断的开销会影响最终性能。
额外提醒:在项目中代码可读性同样重要,不必盲目追求性能优化。

















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









