







 本文详细探讨了字符集的起源与演变,包括ASCII、ISO-8859-1、GB2312/GBK和Unicode及UTF-8。接着分析了编码解码的原理,特别是在Java中的应用,以及URL的特殊编码解码规则。最后,讨论了Android中处理编码解码的注意事项,特别是Uri类的使用陷阱。
本文详细探讨了字符集的起源与演变,包括ASCII、ISO-8859-1、GB2312/GBK和Unicode及UTF-8。接着分析了编码解码的原理,特别是在Java中的应用,以及URL的特殊编码解码规则。最后,讨论了Android中处理编码解码的注意事项,特别是Uri类的使用陷阱。
Android 编码解码的原理解析
一.字符集
1.字符集的由来
-
计算机识别、处理、传递、存储数据,都是基于一个个的字节,一个字节有8为,每位都是0或1,即计算机是通过01字节流来处理数据的,而我们使用的各种字符,包括数字、符号、字母、中文等,都是需要通过字节来编码的,也就是用一些特定的字节标示一个唯一的字符。
-
计算机最早是按英语单字节字符设计的,即一个字节(8位能标示256个字符)就可以表示英文中所有的字符(包括字符、大小写字母、各种英文字符),也就是我们常说的ASCII字符集,该集合包括了上述的所有字符,并为每个字符指定唯一的号码,如:
i.数字0:十进制号码是48,对应的二进制编码就是0011 0000
ii.大写字母A:十进制号码是65,对应的二进制编码就是0100 0001
iii.字符+:十进制号码是43,对应的二进制编码就是0010 1011
这样一来,每一个英文字符,都会有唯一对应的二进制编码,无论数据(二进制流)传递到哪个系统上,它们都以ASCII字符集的编码来解码字节流,得到的就是正确的原始字符串数据;这也就是字符集的作用—包括一组字符,并为每个字符指定唯一的编码
-
如果全世界只有ASCII这一种字符集的话,其实编码解码这个概念就很简单了,但是全世界有很多很多语言,相应的就有很多很多的字符(远远大于256个),显然,这么多的字符,是一个字节无法表示全的,也就是说ASCII字符集不能涵盖全世界的字符,那么怎么办呢?扩展字符集呗,于是,就诞生了多种多样的字符集。。。
2.字符集的演变
(1)ISO-8859-1字符集
ISO-8859-1字符集采用单字节,能够表示256个字符,兼容ASCII,可以支持大多数国家语言
(2)GB2312/GBK字符集
这些字符集是为了支持中文而产生的,使用单双字节变长编码对字符进行编码,英文字符使用单字节编码,兼容ASCII编码,对于中文使用双字节编码
GBK是兼容GB2312的字符集,GB2312只支持简体中文,而GBK支持繁体中文
(3)Unicode字符集
ISO-8859-1不支持中文字符,GBK也不支持其他一些国家的字符,这就导致了使用GBK编码的程序到了其他一些国家系统上就出现乱码的情况,所以,世界需要一个通用完整的字符集来避免这些情况
Unicode为目前最统一最全的字符集,它收录了世界上所有的字符,并为其每个字符指定了一个编码,其编码与上述字符集不兼容,是自己的一套编码系统,该字符集也是目前使用最广泛的一个字符集
对于Unicode字符集来说,最重要的是它的编码实现方式:Unicode字符集只是容纳了所有字符并为其提供唯一的编码,但是不与其他编码兼容,而且对于英文也会占用多字节,对内存不友好,所以,Unicode有许多不同编码实现方式,所谓编码实现方式,就是将一些自定义的编码,能够映射到唯一的Unicode字符编码上,从而可以知道唯一的字符,而这些自定义的编码,可以想办法做成省内存的,兼容其他编码的;其中最常用的编码方式就是UTF-8了
(4)UTF-8编码方式
UTF(Unicode Transformation Format),顾名思义,UTF就是将Unicode编码转换成另一种编码的编码方式,常见的有UTF-8、UTF-7、UTF-16等,最常用的就是UTF-8了
UTF-8是一种可变长字节的编码方式,它使用1-6个字节来对所有Unicode字符进行编码:因为对于ASCII英文字符,只需要单字节即可,如果使用Unicode的话就会使用两个字节,对内存不太友好,所以UTF-8相比Unicode的编码方式来说,可以大大的节省内存开销;对于其他字符比如中文,UTF-8通常是3个字节就可以表示一个中文字符
UTF-8可变长字节的实现原理简介:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。

二.编码解码
1.编码和解码
上面介绍了字符集的概念,知道字符集是用来唯一标识每个字符的二进制字节的, 那么为什么要这么做呢?其实上面也已经说过了,因为计算机处理的数据实质上都是01bit流,8个bits就是一个字节,即计算机处理的的数据本质上都是字节流,也就是说,无论是字符还是字符串还是,最终都会以二进制字节流的形式进行处理,了解了这个,也就明白为什么要编码解码了吧?因为每个字符最终都是一串字节(一串01bits),也就是说我们传递数据前,应该将数据转换成一个一个的字节,这就叫编码;而接收方接收到的数据也就是一个一个的字节,也需要将这一串字节,转换成相应的字符(毕竟字符才是我们真正想要的数据),这就叫解码;再结合上面说的字符集:不同的程序可能使用不同的字符集,不同的字符集对于字符的编码方式不同,所以,我们不光要编码解码,还要指定编码解码所用的字符集,还要保证其编码解码用的字符集一样,否则,不同解析字节的规则解析相同的字节流,结果当然就可能出错了呗,变成了我们未知的字符了,这也就是乱码的形成原因!
2.Java中的编码解码
说了这么多,有些人可能会想:"我写程序使用、传递数据的时候,并没有过多的涉及到编码解码这块的处理,好像也并没有提示过我要编码解码。"下面我们来看看java中,我们通常在哪些地方使用到了编码解码,以及如何使用的:

来看输出:

由代码可知,字符串数据最终传递时,都需要转换成byte字节数组,而转换时,需要指定字符集编码方式(否则使用系统默认的),我们的网络传输等等,最终在底层传递是都是这样的
-
从输出可以看出,“我是test"这6个字符被转化成了10个字节的字节数组,由UTF-8编码规则可知,中文字符通常被表示为三个字节,所以[-26,-130,-111]代表"我”,[-26,-104,-81]代表"是",而英文字符符ASCII编码,所以116代表"t",101代表"e",115代表"t"
-
从输出可以看出,解码时也是需要指定字符集编码方式的,即utf-8根据自己的规则(上面说过),确定前三个字节为一个字符,并通过计算规则映射到Unicode中"我"的编码,于是前三个字节就解码为"我"字符,后面同理
-
是不是有人要问,Java也可以使用字符流读取,即InputStreamReader,可以一次性读取n个字符,那它是怎么知道几个字节为一个字符的呢?我们来看一看

再来看输出:

可见,我们构造Reader时,会指定编码方式的,而每个编码方式可以通过自己的编码规则来确定哪几个字节作为一个字符,比如ISO-8859-1为定长单字节编码,那么它解码时每次获取一个字节进行解码即可;而UTF-8为可变长编码,但是有规则(上面有介绍):每个字符的第一个字节连续前n位为1,那么这个字符就占n个字节。据此规则也可以顺利解码 -
以上就是我们日常使用java时容易忽视的编码解码,有人会问:"那解码编码规则使用不一样时,真的会导致乱码么?"这里就举一个例子,来解释一下:
还是原来的输入"我是test"

再来看输出:

这结果是为什么呢?其实很简单,以utf-8进行编码,解码时,以iso-8859-1进行解码,那么iso-8859-1是定长单字节编码,所以取每一个字节进行解码,这些由utf-8生成的码在iso-8859-1的字符集编码中找到的字符肯定和utf-8不一样啊;而对于英文字符来说,这些字符集都满足ASCII编码规则,所以即使是不同的字符集对于这些字符的编码都是一致的;所以最后的"test"四个字符是没有问题的,而前面的两个中文字符(6个字节)就被解码成iso-8859-1字符集里对应的6个字符了
3.URL的解码编码
对于这个概念,其实很多人都不是很清楚,认为URL的编码解码和字符的编码解码是一回事,或者说是字符集编码方式之一,其实并不是这样的,字符集编码是计算机对于数据传递的一种统一方式,而Url的编码解码是针对于Url这种特殊数据传递所定义的一种规则而已。
Url(统一资源定位符),大家都再熟悉不过了,是URI(统一资源标识符)的一种,有形如此类的格式:scheme://host:port/path?key1=value1&key2=value2,是用于干什么的呢?当然是定位到某个设备某个路径上的标识,再说通用点吧,就是我们请求后端的地址,并可以传递多个键值对参数的字符串,那么问题来了,它也是一个字符串,最终还是要编码成字节流传递到远端的,而这种格式中有些起着特殊作用的字符呢?比如/、?、=、&等等,这些字符也属于ASCII没问题,被编码成字节也没问题,但是,他们的作用是起分隔作用的,比如&分隔了每个键值对,=分隔了键和值,那如果我们的正常数据中(实际要传递的数据)有这些特殊字符呢,比如value1是“a=b”,value2是"a&b",那么这个Url的后半部分就变成了?key1=“a=b”&key2=“a&b”,如果按照原样进行编码解码,那么后端拿到的url字符串还是这样的,在取出参数和分隔键值对的时候就会有错了:按&分隔成的键值对就为key1=“a=b”,key2=“a,b”;再按=分隔成的键值就为<key1,"a>,<key2,"a>,这显然就酿成大祸了。。。
所以,为了使Url访问时,能够保留这些特殊字符,并且Url希望使用安全字符(即不会造成混乱的字符,也就是使用通用的ASCII字符集的符号),就为Url设置了一套"编码解码"规则来达到这些要求:
-
对于字母、数字、一些ASCII中的字符不做处理
-
对于空格,容易造成歧义,转换为+(+会做(3)处理,不会影响)
-
对于其他字符,都使用&hex1hex2来转义,hex1hex2是该字符在对应的字符集编码方式中的编码对应的16进制数
这样一来,整个Url就都是ASCII字符集里的安全字符,并且实际数据中的那些特殊字符都被转义了,我们来举个例子看的更明白些:
原始Url:?kw="a=b"&exp="a&b"
Url编码后的Url:?kw=%22a%3Db%22&exp=%22a%26b%22
服务端在拿到Url是,就是编码后的Url,此时可以通过=&来取出键值对(因为特殊字符没有被编码),取出后,将每个key-value再进行Url的解码,就生成这样的键值对:
<kw,"a=b">,<exp,"a&b">
所以,Url的编码解码只是因为Url的一些可能造成歧义和错误的字符,而定义的一套转义规则,并不是和utf-8一样的一种编码方式,只是将字符转换成另一种字符而已。
三.android中的编码解码
(1)在Android中,数据的编码解码和java中其实一样(毕竟用的java。。。),如果相对Url应用编码解码,可以使用提供的URLEncoder和URLDecoder的相关方法,流程就是和上述介绍的URL解码编码规则类似
URLEncoder
private void appendEncoded(StringBuilder builder, String s, Charset charset, boolean isPartiallyEncoded) {
int escapeStart = -1;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if ((c >= 'a' && c <= 'z')
|| (c >= 'A' && c <= 'Z')
|| (c >= '0' && c <= '9')
|| isRetained(c)
|| (c == '%' && isPartiallyEncoded)) {
if (escapeStart != -1) {
appendHex(builder, s.substring(escapeStart, i), charset); //转义
escapeStart = -1;
}
if (c == '%' && isPartiallyEncoded) {
// this is an encoded 3-character sequence like "%20"
builder.append(s, i, i + 3);
i += 2;
} else if (c == ' ') { //空格换成+
builder.append('+');
} else { //原样保留
builder.append(c);
}
} else if (escapeStart == -1) {
escapeStart = i;
}
}
}
private static void appendHex(StringBuilder builder, String s, Charset charset) {
for (byte b : s.getBytes(charset)) { //指定字符集编码
appendHex(builder, b);
}
}
private static void appendHex(StringBuilder sb, byte b) {
sb.append('%'); //转换为%hex1hex2
sb.append(Byte.toHexString(b, true));
}
URLDecoder
public static String decode(String s, boolean convertPlus, Charset charset, boolean throwOnFailure) {
if (s.indexOf('%') == -1 && (!convertPlus || s.indexOf('+') == -1)) {
return s;
}
StringBuilder result = new StringBuilder(s.length());
ByteArrayOutputStream out = new ByteArrayOutputStream();
for (int i = 0; i < s.length();) {
char c = s.charAt(i);
if (c == '%') {
do {
int d1, d2;
if (i + 2 < s.length()
&& (d1 = hexToInt(s.charAt(i + 1))) != -1
&& (d2 = hexToInt(s.charAt(i + 2))) != -1) {
out.write((byte) ((d1 << 4) + d2)); //%连同后两位16进制数字转换为字节写入字节数组(恢复)
} else if (throwOnFailure) {
throw new IllegalArgumentException("Invalid % sequence at " + i + ": " + s);
} else {
byte[] replacement = "\ufffd".getBytes(charset);
out.write(replacement, 0, replacement.length);
}
i += 3;
} while (i < s.length() && s.charAt(i) == '%');
result.append(new String(out.toByteArray(), charset)); //按指定字符集解码为字符
out.reset();
} else {
if (convertPlus && c == '+') { //+恢复为空格
c = ' ';
}
result.append(c);
i++;
}
}
return result.toString();
}
(2)Android中另一种处理Url的方式就是使用Uri类,这也是重点要说的类
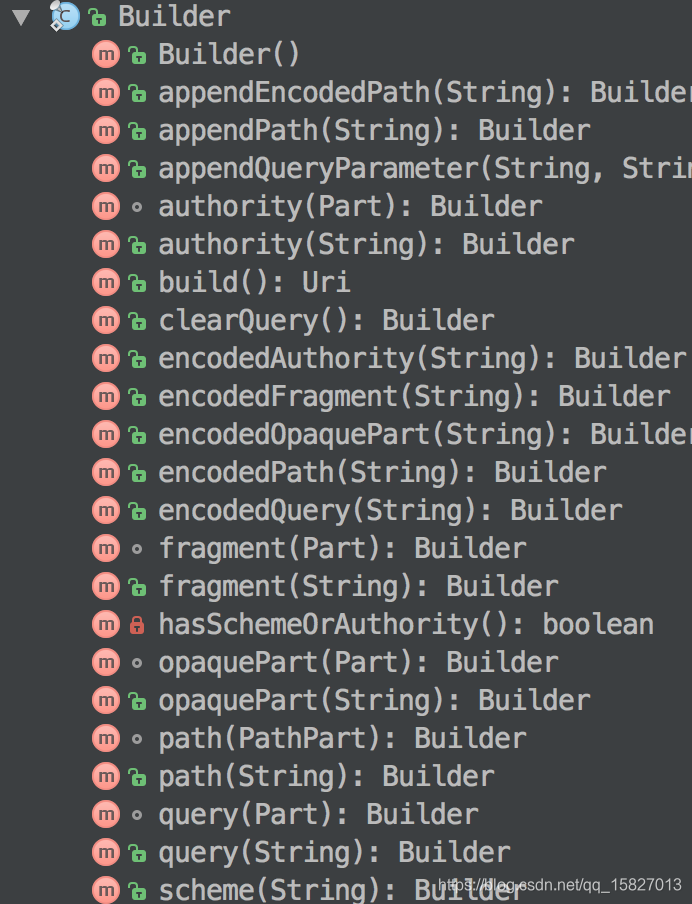
这是构建Uri的Builder类,我们可以看到,可以设置Uri的scheme,authority,path和query,而且这些属性大多都提供了两种方法,一种是encodedXxx,一种是xxx,顾名思义,前者是设置已经编码过得值,后者就是未编码过的值,而appendQueryParameter方法最常用,它设置的就是未编码过得值,那么为什么要区分呢?是基于Uri的实现机制的,Uri内部几乎所有的值都有编码未编码状态,即encoded和decoded状态,在使用时,也有两种方法,一种是getXxx,一种是getEncodedXxx,前者就是获取到decoded的相应属性,后者是获取encoded的相应属性
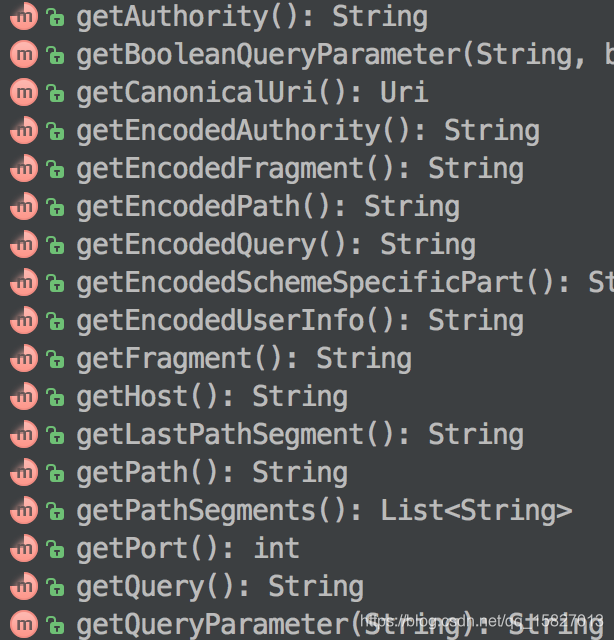
也就是说,Uri内部的属性,要么是编码过的,要么是未编码过的,取出时,也会进行相应的编码和解码,清楚这个很重要,否则可能会导致编码过的再编码,解码过的再解码的情况
(3)下面就举一个容易掉进坑里的例子吧:
i.隐式Uri跳转到一个页面,url为:mypro://www.mypro.com/mainAct?name=“鲜果100%店”,只需要使用Uri.parse(url)即可构建Uri
public static Intent buildIntent(Context context, String url) {
Intent intent = new Intent();
Uri uri = Uri.parse(url);
...
return intent;//后续startActivity(intent)即可
}
ii.我们来看Uri.parse方法
public static Uri parse(String uriString) {
return new StringUri(uriString);
}
private StringUri(String uriString) {
this.uriString = uriString;//直接保存在stringUri变量中
}
iii.再来看我们如果使用uri.getQueryParameter(key)方法会发生什么
public String getQueryParameter(String key) {
...
final String query = getEncodedQuery();//获取的是encodedQuery
...
final String encodedKey = encode(key, null);
final int length = query.length();
int start = 0;
do {
int nextAmpersand = query.indexOf('&', start);
int end = nextAmpersand != -1 ? nextAmpersand : length;
int separator = query.indexOf('=', start);
if (separator > end || separator == -1) {
separator = end;
}
if (separator - start == encodedKey.length()
&& query.regionMatches(start, encodedKey, 0, encodedKey.length())) {
if (separator == end) {
return "";
} else {
String encodedValue = query.substring(separator + 1, end);//value现在是鲜果100%店,被当做了encoded状态了
return UriCodec.decode(encodedValue, true, StandardCharsets.UTF_8, false);//所以要decode:%hex1hex2解码,而100%后面不是16进制数,所以错误(崩溃与否看参数)
}
}
// Move start to end of name.
if (nextAmpersand != -1) {
start = nextAmpersand + 1;
} else {
break;
}
} while (true);
return null;
}
public String getEncodedQuery() {
return getQueryPart().getEncoded();//获取queryPart对象
}
private Part getQueryPart() {
return query == null
? query = Part.fromEncoded(parseQuery()) : query;//由url直接parse构建,queryPart为null,所以根据stringUri(传入的url)创建
}
private String parseQuery() {
int qsi = uriString.indexOf('?', findSchemeSeparator());
if (qsi == NOT_FOUND) {
return null;
}
...
return uriString.substring(qsi + 1, fsi);//找到?后面的返回
}
static Part fromEncoded(String encoded) {
return from(encoded, NOT_CACHED);//!!!将此queryString当成了encoded的
}
如上所述,问题就在于Uri.parse传入的url参数,被Uri默认当成的是encoded的了,而我们通常用于构建Uri的url,是decoded的;
当getQueryParameter()时,Uri是拿到encoded的queryString然后进行decode解码,这就造成了对"鲜果100%店"这个已经decode过的字符串再度decode了,就导致了错误,所以在使用Uri的时候,要注意这点。

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









