




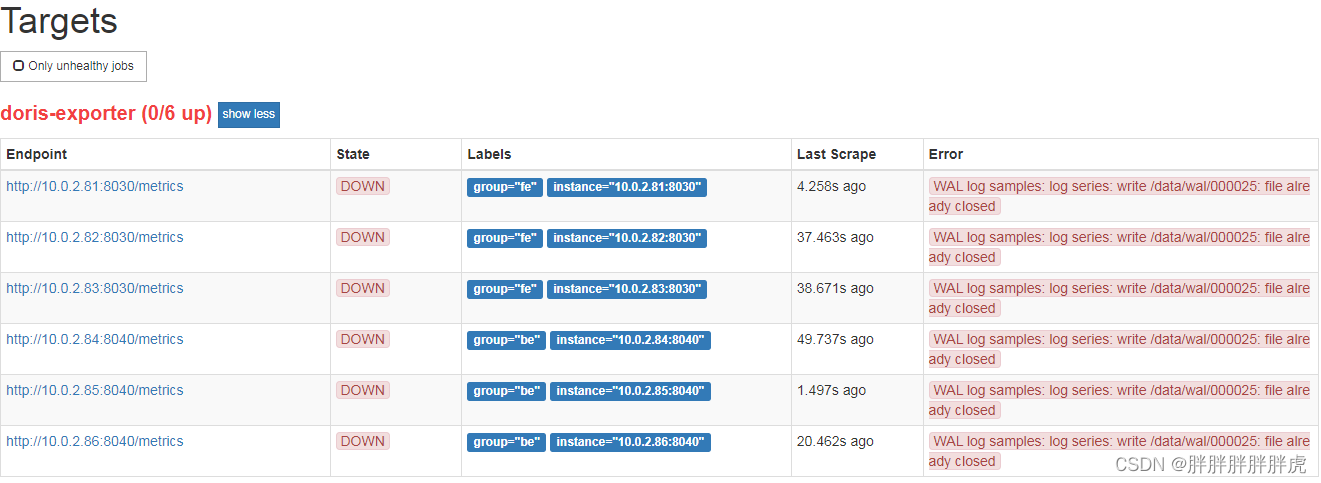
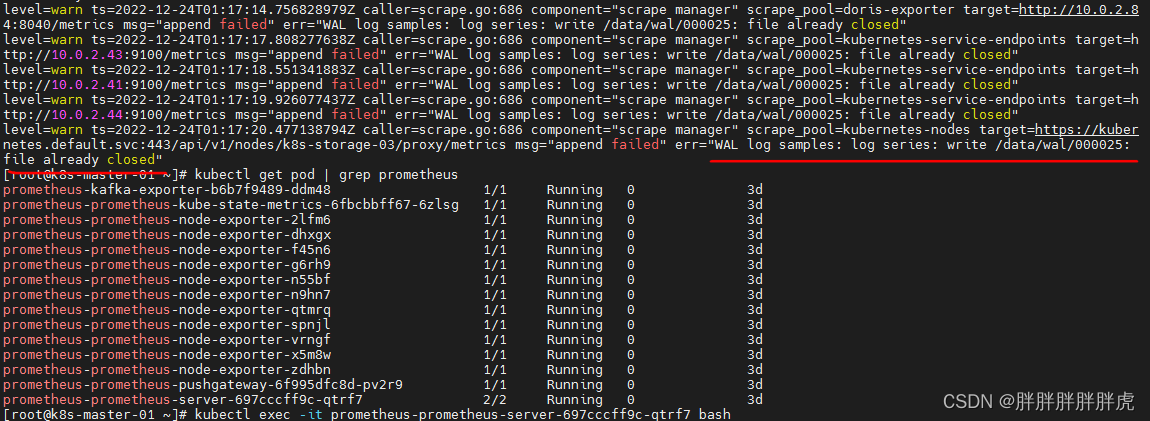
 在Kubernetes(K8s)环境中使用Helm部署Prometheus后,发现所有监控状态为down。检查Prometheus服务器的数据目录,发现数据文件占用大量空间,但配置的retention参数似乎无效,无法按预期调整数据保留时间。根据Red Hat的文档,探讨了如何修改监控数据的保留时间和大小,并引用了GitHub上的相关问题讨论。
在Kubernetes(K8s)环境中使用Helm部署Prometheus后,发现所有监控状态为down。检查Prometheus服务器的数据目录,发现数据文件占用大量空间,但配置的retention参数似乎无效,无法按预期调整数据保留时间。根据Red Hat的文档,探讨了如何修改监控数据的保留时间和大小,并引用了GitHub上的相关问题讨论。
k8s helm 部署 prometheus,各个监控都处于 down 的状态
[root@k8s-master-01 ~]# kubectl exec -it prometheus-prometheus-server-697cccff9c-qtrf7 -c prometheus-server sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/prometheus $ cd /data/
/data $ ls -l
total 1
drwxr-sr-x 3 nobody nogroup 68 Dec 21 19:00 01GMV0XA1DFQWDT1FJ07QEM55J
drwxr-sr-x 3 nobody nogroup 68 Dec 22 13:00 01GMWYPT7WXCFBSRPYYDXS0K2X
drwxr-sr-x 3 nobody nogroup 68 Dec 23 07:00 01GMYWGDDA8EG7T8K7FP9C7WD0
drwxr-sr-x 3 nobody nogroup  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









