






全网最详细使用Sglang部署DeepSeek-R1-671B满血版4机32卡
第一章 配置和检查InfiniBand网络
InfiniBand 是一种高性能网络技术,专为高带宽、低延迟的数据传输设计。它广泛应用于高性能计算(HPC)、数据中心和云计算环境中,支持大规模并行计算、存储网络和机器学习等任务。InfiniBand 提供极高的吞吐量(可达数百Gbps)和极低的延迟(微秒级),同时支持远程直接内存访问(RDMA),允许数据直接在节点间传输,无需CPU干预,从而大幅提升效率。
1.1. 启用InfiniBand设备
首先,我们需要启用InfiniBand设备。假设您有两个InfiniBand设备 ibs948 和 ibs844,您可以使用以下命令将它们启用:
sudo ip link set dev ibs948 up
sudo ip link set dev ibs844 up
ip link set dev <设备名> up:这个命令用于启用指定的网络设备。up参数表示启用设备。
1.2. 查看InfiniBand设备与网络设备的映射
启用设备后,您可以使用 ibdev2netdev 命令来查看InfiniBand设备与网络设备之间的映射关系:
ibdev2netdev
ibdev2netdev:这个命令会列出所有InfiniBand设备及其对应的网络接口名称。这对于确认InfiniBand设备是否正确映射到网络接口非常有用。
1.3. 查看网络接口的IP地址
接下来,您可以使用 ip addr 命令来查看所有网络接口的IP地址信息:
ip addr
ip addr:这个命令会显示所有网络接口的详细信息,包括IP地址、子网掩码、MAC地址等。您可以在这里确认InfiniBand设备是否已经分配了正确的IP地址。
1.4. 检查InfiniBand设备的状态
最后,您可以使用 ibstatus 命令来检查InfiniBand设备的状态:
ibstatus
ibstatus:这个命令会显示InfiniBand设备的详细状态信息,包括设备名称、端口状态、链路速度、MTU等。通过这个命令,您可以确认InfiniBand设备是否正常工作。
第二章 安装、查看和管理OpenSM(InfiniBand子网管理器)
OpenSM 是 InfiniBand 网络的子网管理器,负责管理 InfiniBand 子网的拓扑结构、路由和通信。
2.1. 卸载OpenSM(可选)
如果当前安装的 OpenSM 版本不正确或存在问题,可以先卸载它:
sudo apt-get remove opensm -y
- 说明:
remove opensm -y:卸载 OpenSM 软件包,-y参数表示自动确认卸载操作。
2.2. 安装OpenSM
使用以下命令安装 OpenSM:
sudo apt-get install opensm -y
- 说明:
install opensm -y:安装 OpenSM 软件包,-y参数表示自动确认安装操作。
2.3.检查OpenSM服务状态
安装完成后,检查 OpenSM 服务的运行状态:
systemctl status opensm
- 说明:
- 输出会显示 OpenSM 服务的状态:
Active: active (running)表示服务正在运行。Active: inactive (dead)表示服务未运行。
- 如果服务未运行,可以使用以下命令启动它:
sudo systemctl start opensm
- 输出会显示 OpenSM 服务的状态:
2.4. 检查OpenIBD服务状态
OpenIBD 是 InfiniBand 设备的守护进程,负责初始化和管理 InfiniBand 设备。检查其状态:
systemctl status openibd
- 说明:
- 输出会显示 OpenIBD 服务的状态:
Active: active (exited)表示服务已成功完成初始化。Active: inactive (dead)表示服务未运行。
- 如果服务未运行,可以使用以下命令启动它:
sudo systemctl start openibd
- 输出会显示 OpenIBD 服务的状态:
2.5. 检查InfiniBand设备状态
使用 ibstatus 命令查看 InfiniBand 设备的状态:
ibstatus
- 说明:
- 输出会显示 InfiniBand 设备的详细信息,包括:
- 设备名称(如
mlx5_0)。 - 端口状态(
PORT_ACTIVE表示端口已激活)。 - 链路速度(如
100 Gb/sec)。 - MTU 大小(如
4096)。
- 设备名称(如
- 如果设备未正常工作,请检查 OpenSM 和 OpenIBD 服务是否已正确启动。
- 输出会显示 InfiniBand 设备的详细信息,包括:
第三章 防火墙和清理规则
为了避免4台机器之间出现端口不通导致的网络不通问题,所以关闭了所有防火墙,详细操作步骤如下:
3.1. 设置iptables默认策略为允许所有流量
在关闭防火墙之前,确保 iptables 的默认策略为允许所有流量,以避免意外中断网络连接。
sudo iptables -P INPUT ACCEPT
sudo iptables -P OUTPUT ACCEPT
sudo iptables -P FORWARD ACCEPT
- 说明:
-P INPUT ACCEPT:允许所有传入流量。-P OUTPUT ACCEPT:允许所有传出流量。-P FORWARD ACCEPT:允许所有转发流量。
3.2. 清空iptables规则
清空所有现有的 iptables 规则,确保没有残留的规则影响网络。
sudo iptables -F
- 说明:
-F:清空所有链中的规则。
3.3. 检查UFW状态
UFW(Uncomplicated Firewall)是Ubuntu等Linux发行版中常用的防火墙管理工具。首先检查UFW的状态。
sudo ufw status
- 说明:
- 如果UFW已启用,输出会显示当前规则和状态(
Status: active)。 - 如果UFW未启用,输出会显示
Status: inactive。
- 如果UFW已启用,输出会显示当前规则和状态(
3.4. 禁用UFW
如果UFW已启用,使用以下命令禁用它:
sudo ufw disable
- 说明:
- 该命令会关闭UFW防火墙,并停止其服务。
- 输出会显示
Firewall stopped and disabled on system startup。
3.5. 再次检查UFW状态
确认UFW已成功禁用。
sudo ufw status
- 说明:
- 输出应显示
Status: inactive,表示UFW已关闭。
- 输出应显示
第四章 使用 netcat 检查端口连通性
netcat(简称 nc)是一个强大的网络工具,常用于测试端口连通性、传输数据等。
4.1. 更新软件包列表
在安装 netcat 之前,建议先更新系统的软件包列表:
sudo apt-get update
- 说明:
apt-get update:从软件源获取最新的软件包列表。
4.2. 安装 netcat
使用以下命令安装 netcat:
sudo apt-get install -y netcat
- 说明:
-y:自动确认安装,无需手动输入yes。
4.3. 使用 netcat 检查端口连通性
安装完成后,可以使用 netcat 检查目标机器的端口是否开放和可达。
基本语法:
nc -zv <目标IP> <端口号>
- 参数说明:
-z:扫描模式,不发送任何数据。-v:详细输出模式,显示更多信息。<目标IP>:目标机器的 IP 地址。<端口号>:要检查的端口号。
示例:
假设目标机器的 IP 地址是 172.17.13.11,端口号是 8000,运行以下命令:
nc -zv 172.17.13.11 8000
- 输出示例:
- 如果端口开放且可达,输出类似:
Connection to 172.17.13.11 8000 port [tcp/*] succeeded! - 如果端口不可达,输出类似:
nc: connect to 172.17.13.11 port 8000 (tcp) failed: Connection refused
- 如果端口开放且可达,输出类似:
4.4. 自动化脚本
编写一个自动化脚本来检测端口:
#!/bin/bash
TARGET_IP="172.17.13.11"
PORTS=(8000 8001 8002 )
for port in "${PORTS[@]}"; do
echo "Checking port $port on $TARGET_IP..."
nc -zv $TARGET_IP $port
done
- 说明:
- 将
TARGET_IP替换为目标机器的 IP 地址。 - 在
PORTS数组中添加需要检查的端口号。 - 运行脚本后,会自动检查所有指定端口的连通性。
- 将
第五章 检查多机之间InfiniBand设备是否联通
检查四台机器之间的 InfiniBand (IB) 网络是否联通,以下是详细的检查方法:
5.1. 确保所有机器上的 InfiniBand 设备已启用
在每台机器上运行以下命令,确保 InfiniBand 设备已启用并处于活动状态:
ibstatus
- 检查点:
- 确认设备端口状态为
PORT_ACTIVE。 - 确认链路速度(如
100 Gb/sec)和 MTU 大小(如4096)正常。
- 确认设备端口状态为
如果设备未启用,可以使用以下命令启用设备(假设设备名为 ib0):
sudo ip link set dev ib0 up
5.2. 检查 InfiniBand 子网管理器 (OpenSM) 是否运行
确保至少有一台机器上运行了 InfiniBand 子网管理器(OpenSM),以管理 IB 子网的通信。
systemctl status opensm
- 如果 OpenSM 未运行,可以使用以下命令启动它:
sudo systemctl start opensm
5.3. 获取每台机器的 InfiniBand IP 地址
在每台机器上运行以下命令,查看 InfiniBand 接口的 IP 地址:
ip addr show ib0
- 注意:
- 确保每台机器的 InfiniBand 接口(如
ib0)已分配 IP 地址。 - 如果未分配 IP 地址,可以使用以下命令手动分配(例如,分配
192.168.1.1/24):
- 确保每台机器的 InfiniBand 接口(如
sudo ip addr add 192.168.1.1/24 dev ib0
5.4. 使用 ping 测试连通性
在每台机器上,使用 ping 命令测试与其他机器的 InfiniBand IP 地址的连通性。
例如,在机器 A 上测试与机器 B 的连通性:
ping <机器B的IB IP地址>
-
示例:
- 如果机器 B 的 IB IP 是
192.168.1.2,则在机器 A 上运行:ping 192.168.1.2 - 如果能够收到回复,说明两台机器之间的 IB 网络是联通的。
- 如果机器 B 的 IB IP 是
-
注意:
- 在每台机器上依次测试与其他所有机器的连通性。
5.5. 使用 ibping 测试 InfiniBand 层的连通性
ibping 是专门用于测试 InfiniBand 网络连通性的工具。它直接在 IB 层进行测试,不依赖 IP 地址。
-
安装
ibping(如果未安装):sudo apt-get install infiniband-diags -y -
在目标机器上启动
ibping服务:
在机器 B 上运行以下命令,启动ibping服务:ibping -S -
在源机器上测试连通性:
在机器 A 上运行以下命令,测试与机器 B 的连通性:ibping -c 10 <机器B的IB端口GUID>-
获取 IB 端口 GUID:
在每台机器上运行以下命令,查看 IB 端口的 GUID:ibstat找到
Port GUID字段的值。 -
示例:
如果机器 B 的 Port GUID 是0x0002c90300a1b2c3,则在机器 A 上运行:ibping -c 10 0x0002c90300a1b2c3 -
结果:
- 如果显示
10 packets transmitted, 10 received,说明 IB 层连通性正常。
- 如果显示
-
5.6. 检查路由和子网配置
确保所有机器在同一个 InfiniBand 子网中,并且路由配置正确。
-
使用以下命令查看路由表:
ip route show -
确保所有 IB 接口的 IP 地址在同一个子网中(例如
192.168.1.0/24)。
5.7. 检查防火墙设置
确保防火墙未阻止 InfiniBand 通信。
-
检查 UFW 状态:
sudo ufw status -
如果防火墙已启用,确保允许 InfiniBand 相关端口(如 18515、5353 等)的通信。
第六章 使用 Docker 镜像拉取与容器启动
6.1. 镜像准备
镜像拉取可以从官方直接拉取:
sudo docker pull glang_latest.tar
或者如果镜像已打包为 .tar 文件,可以通过以下命令加载:
sudo docker load -i sglang_latest.tar
- 说明:
sglang_latest.tar是镜像文件的名称。- 加载后,可以使用
docker images查看已加载的镜像。
6.2. 容器启动
启动容器时,要指定通信网络,NCCL通信方式两种,一种是TCP普通网络,另外一种是高速IB网络,两种方式如下:
(1)使用 TCP 网络启动容器:
sudo docker run -it --gpus all \
--privileged \
--shm-size 32g \
--network=host \
-v /your/hosts/path/deepseek:/container/path/ \
--cap-add=IPC_LOCK \
--name container_name \
-e NCCL_DEBUG=INFO \
-e NCCL_IB_DISABLE=1 \
-e NCCL_SOCKET_IFNAME=your_net_card \
-e NCCL_P2P_LEVEL=NVL \
lmsysorg/sglang
- 参数说明:
--gpus all:启用所有 GPU。--privileged:赋予容器特权模式,允许访问主机设备。--shm-size 32g:设置共享内存大小为 32GB。--network=host:使用主机网络模式。-v:将主机目录挂载到容器内。--cap-add=IPC_LOCK:允许容器锁定内存。--name container_name:为容器指定名称。-e NCCL_DEBUG=INFO:启用 NCCL 调试信息。-e NCCL_IB_DISABLE=1:禁用 InfiniBand,强制使用 TCP。-e NCCL_SOCKET_IFNAME=your_net_card:指定网络接口为your_net_card。-e NCCL_P2P_LEVEL=NVL:设置 NCCL 的 P2P 通信级别为 NVLINK。
(2)使用 InfiniBand 网络启动容器:
sudo docker run -it --gpus all \
--privileged \
--shm-size 32g \
--network=host \
-v /your/hosts/path/deepseek:/container/path/ \
--device=/dev/infiniband:/dev/infiniband \
--cap-add=IPC_LOCK \
--name container_name \
-e NCCL_DEBUG=INFO \
-e NCCL_IB_DISABLE=0 \
-e NCCL_IB_HCA=mlx5_num1,mlx5_num2 \
-e NCCL_SOCKET_IFNAME=your_net_card \
lmsysorg/sglang
- 参数说明:
--device=/dev/infiniband:/dev/infiniband:将主机的 InfiniBand 设备挂载到容器内,--network=host后这个参数可以不用。-e NCCL_IB_DISABLE=0:启用 InfiniBand。-e NCCL_IB_HCA=mlx5_0,mlx5_1:指定使用的 InfiniBand 设备(如mlx5_0和mlx5_1,这个值根据实际情况需要修改)。
6.3. 验证容器运行状态
启动容器后,可以通过以下命令验证容器的运行状态:
docker ps -a
- 说明:
- 查看容器是否正常运行。
- 如果容器未运行,可以使用
docker logs ds671查看日志。
第七章 模型启动调用与并发测试
7.1 模型启动
模型启动列举两种方式,调式运行和后端运行两种
(1)调式运行
python3 -m sglang.launch_server --model-path DeepSeek-R1-bf16 \
--tp 32 \
--dist-init-addr ip:port \
--nnodes 4 \
--trust-remote-code \
--host 0.0.0.0 \
--port your-port \
--mem-fraction-static 0.86 \
--api-key yoursecret\
--node-rank 0
参数解释
1. python3 -m sglang.launch_server
- 这是启动
sglang框架中服务器模块的命令。 sglang是一个支持分布式推理的框架,launch_server是其启动服务器的子模块。
2. --model-path DeepSeek-R1-bf16
- 作用:指定要加载的模型路径。
- 说明:
DeepSeek-R1-bf16是模型的名称或路径。- 模型可以是本地路径,也可以是远程仓库(如 Hugging Face)中的模型名称。
- 该模型使用
bfloat16精度(bf16),适合在 GPU 上高效运行。
3. --tp 32
- 作用:设置张量并行(Tensor Parallelism, TP)的 GPU 数量。
- 说明:
32表示将模型切分到 32 个 GPU 上并行计算。- 张量并行是一种模型并行技术,将模型的权重和计算分布到多个 GPU 上,以加速推理。
4. --dist-init-addr ip:port
- 作用:指定分布式训练的初始化地址。
- 说明:
ip:port是主节点的 IP 地址和端口号。- 所有节点通过该地址进行通信和同步。
- 例如:
192.168.1.100:5000。
5. --nnodes 4
- 作用:指定参与分布式训练的节点数量。
- 说明:
4表示总共有 4 个节点参与训练或推理。- 每个节点可以是一个物理机器或容器。
6. --trust-remote-code
- 作用:允许加载远程代码(如自定义模型或脚本)。
- 说明:
- 如果模型包含自定义代码(如 Hugging Face 模型中的自定义层),需要启用此选项。
- 启用后,框架会信任并加载远程代码。
7. --host 0.0.0.0
- 作用:指定服务器监听的 IP 地址。
- 说明:
0.0.0.0表示服务器监听所有网络接口。- 允许从任何 IP 地址访问服务器。
8. --port your-port
- 作用:指定服务器监听的端口号。
- 说明:
your-port是具体的端口号,例如5000。- 客户端通过该端口与服务器通信。
9. --mem-fraction-static 0.86
- 作用:设置 GPU 内存的静态分配比例。
- 说明:
0.86表示将 GPU 内存的 86% 分配给模型推理。- 该参数用于控制 GPU 内存的使用,避免内存不足或浪费。
10. --api-key yoursecret
- 作用:设置 API 密钥,用于身份验证。
- 说明:
yoursecret是自定义的密钥字符串。- 客户端访问服务器时需要提供该密钥,以确保安全性。
11. --node-rank 0
- 作用:指定当前节点的排名(Rank)。
- 说明:
0表示当前节点是主节点(Rank 0)。- 在分布式训练或推理中,Rank 0 节点通常负责协调其他节点。
- 其他节点的 Rank 可以是
1、2、3等。
(2)后端运行
nohup python3 -m sglang.launch_server --model-path DeepSeek-R1-bf16 \
--tp 32 \
--dist-init-addr yourip:port\
--nnodes 4 \
--trust-remote-code \
--host 0.0.0.0 \
--port yourport\
--api-key yoursecret\
--node-rank 0 > logs.log 2>&1 &
7.2 模型调用
模型调用类似格式如下:
curl -X POST "http://ip:yourport/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer yoursecret" \
-d '{
"model": "DeepSeek-R1-bf16",
"messages": [{"role": "user", "content": "你可以帮我做什么"}],
"temperature": 0.6,
"max_tokens": 1024
}'
7.3 压力测试
压力测试工具采用sglang中的sglang.bench_serving测试,其参数即介绍如下:
以下是参数的翻译和解释:
options:
-
-h, --help显示帮助信息并退出。 -
--backend {sglang,sglang-native,sglang-oai,vllm,lmdeploy,trt,gserver,truss}必须指定一个后端,取决于所使用的LLM推理引擎。 -
--base-url BASE_URL如果不使用HTTP主机和端口,则指定服务器或API的基础URL。 -
--host HOST默认主机是0.0.0.0。 -
--port PORT如果未设置,默认端口将根据不同的LLM推理引擎的默认值进行配置。 -
--dataset-name {sharegpt,random,generated-shared-prefix}用于基准测试的数据集名称。 -
--dataset-path DATASET_PATH数据集的路径。 -
--model MODEL模型的名称或路径。如果未设置,默认模型将请求/v1/models以获取配置。 -
--tokenizer TOKENIZER分词器的名称或路径。如果未设置,则使用模型的配置。 -
--num-prompts NUM_PROMPTS要处理的提示数量。默认值为1000。 -
--sharegpt-output-len SHAREGPT_OUTPUT_LEN每个请求的输出长度。覆盖ShareGPT数据集中的输出长度。 -
--sharegpt-context-len SHAREGPT_CONTEXT_LENShareGPT数据集的模型上下文长度。超过上下文长度的请求将被丢弃。 -
--random-input-len RANDOM_INPUT_LEN每个请求的输入令牌数量,仅用于随机数据集。 -
--random-output-len RANDOM_OUTPUT_LEN
每个请求的输出令牌数量,仅用于随机数据集。 -
--random-range-ratio RANDOM_RANGE_RATIO输入/输出长度的采样比例范围,仅用于随机数据集。 -
--request-rate REQUEST_RATE每秒请求数。如果设置为inf,则所有请求将在时间0发送。否则,使用泊松过程合成请求到达时间。默认值为inf。 -
--max-concurrency MAX_CONCURRENCY最大并发请求数。这可以用于模拟一个环境,其中高层组件强制执行最大并发请求数。虽然--request-rate参数控制请求的发起速率,但此参数将控制实际允许同时执行的请求数。这意味着当结合使用时,如果服务器处理请求的速度不够快,实际请求速率可能低于--request-rate指定的值。 -
--multi使用请求速率范围而不是单一值。 -
--request-rate-range REQUEST_RATE_RANGE请求速率范围,格式为start,stop,step。默认值为2,34,2。它还支持请求速率列表,要求参数不等于三个。 -
--output-file OUTPUT_FILE输出JSONL文件名。 -
--disable-tqdm指定禁用tqdm进度条。 -
--disable-stream禁用流模式。 -
--return-logprob返回对数概率。 -
--seed SEED随机种子。 -
--disable-ignore-eos禁用忽略EOS(结束符)。 -
--extra-request-body {"key1": "value1", "key2": "value2"}将给定的JSON对象附加到请求负载中。您可以使用此参数指定额外的生成参数,如采样参数。 -
--apply-chat-template应用聊天模板。 -
--profile使用Torch Profiler。端点必须使用SGLANG_TORCH_PROFILER_DIR启动以启用分析器。 -
--lora-name LORA_NAMELoRA适配器的名称。
generated-shared-prefix dataset arguments: -
--gsp-num-groups GSP_NUM_GROUPS生成共享前缀数据集的系统提示组数量。 -
--gsp-prompts-per-group GSP_PROMPTS_PER_GROUP生成共享前缀数据集的每个系统提示组的提示数量。 -
--gsp-system-prompt-len GSP_SYSTEM_PROMPT_LEN生成共享前缀数据集的系统提示的目标令牌长度。 -
--gsp-question-len GSP_QUESTION_LEN生成共享前缀数据集的问题的目标令牌长度。 -
--gsp-output-len GSP_OUTPUT_LEN生成共享前缀数据集的输出的目标令牌长度。
压力测试步骤如下:
第一步: 启动模型 模型启动时不要设置密钥
nohup python3 -m sglang.launch_server --model-path DeepSeek-R1-bf16 \
--tp 32 \
--dist-init-addr ip:port\
--nnodes 4 \
--trust-remote-code \
--host 0.0.0.0 \
--port yourport\
--node-rank 0 > log.log 2>&1 &
第二步: 数据集准备
先把数据集下载好,不然测试时,会自动从huggingface上下载,网络无法访问,使用如下镜像地址即可下载好。
wget https://hf-mirror.com/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
第三步:并发脚本启动
可以根据自己的情况修改参数,--dataset-path改为自己的数据集的下载路径
python3 -m sglang.bench_serving \
--backend sglang \
--host ip \
--port port\
--model DeepSeek-R1-bf16 \
--random-input-len 1024 \
--random-output-len 2048 \
--max-concurrency 64 \
--num-prompts 128 \
--dataset-path ./ShareGPT_V3_unfiltered_cleaned_split.json \
第四步:输出内容参数解释
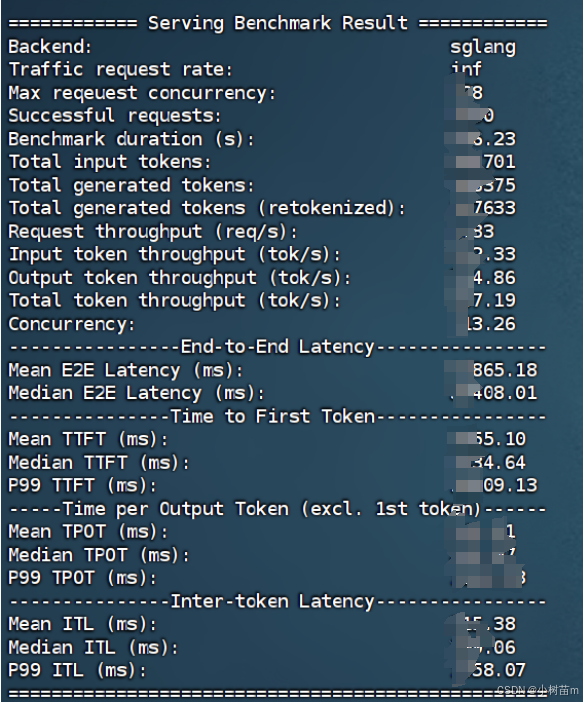
基本信息
- Backend:
sglang
表示测试的后端系统是sglang。 - Traffic request rate:
inf
请求速率是无限的(inf表示无限),意味着系统在测试中没有限制请求的速率。 - Max request concurrency:
32
最大请求并发数为 32,表示系统同时处理的最大请求数量。 - Successful requests:
128
成功处理的请求数量为 128。 - Benchmark duration (s):
110.27
基准测试的总时长为 110.27 秒。
Token 相关数据
- Total input tokens:
47831
总共处理的输入 token 数量为 47,831。 - Total generated tokens:
27256
总共生成的输出 token 数量为 27,256。 - Total generated tokens (retokenized):
27154
重新 tokenize 后的生成 token 数量为 27,154(与生成的 token 数量接近,说明 tokenize 过程基本一致)。 - Request throughput (req/s):
0.87
请求吞吐量为每秒 0.87 个请求。 - Input token throughput (tok/s):
324.79
输入 token 的吞吐量为每秒 324.79 个 token。 - Output token throughput (tok/s):
185.08
输出 token 的吞吐量为每秒 185.08 个 token。 - Total token throughput (tok/s):
509.87
总 token 吞吐量为每秒 509.87 个 token(输入 + 输出)。 - Concurrency:
31.07
平均并发数为 31.07,表示系统在测试期间平均同时处理的请求数量。
端到端延迟(End-to-End Latency)
- Mean E2E Latency (ms):
35749.98
平均端到端延迟为 35,749.98 毫秒(约 35.75 秒),表示从请求发出到收到完整响应的平均时间。 - Median E2E Latency (ms):
34638.49
中位数端到端延迟为 34,638.49 毫秒(约 34.64 秒),表示 50% 的请求延迟低于此值。
首 Token 时间(Time to First Token, TTFT)
- Mean TTFT (ms):
5288.02
平均首 Token 时间为 5,288.02 毫秒(约 5.29 秒),表示从请求发出到收到第一个 token 的平均时间。 - Median TTFT (ms):
2466.67
中位数首 Token 时间为 2,466.67 毫秒(约 2.47 秒),表示 50% 的请求首 Token 时间低于此值。 - P99 TTFT (ms):
10532.42
99% 的请求首 Token 时间低于 10,532.42 毫秒(约 10.53 秒)。
每个输出 Token 的时间(Time per Output Token, TPOT)
- Mean TPOT (ms):
209.77
平均每个输出 Token 的时间为 209.77 毫秒(不包括第一个 Token)。 - Median TPOT (ms):
180.90
中位数每个输出 Token 的时间为 180.90 毫秒。 - P99 TPOT (ms):
465.34
99% 的请求每个输出 Token 的时间低于 465.34 毫秒。
Token 间延迟(Inter-token Latency, ITL)
- Mean ITL (ms):
144.11
平均 Token 间延迟为 144.11 毫秒,表示生成两个相邻 Token 之间的平均时间。 - Median ITL (ms):
111.89
中位数 Token 间延迟为 111.89 毫秒。 - P99 ITL (ms):
1040.50
99% 的请求 Token 间延迟低于 1,040.50 毫秒。



















 2584
2584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











