






 本文详细介绍了关系型数据库的设计原理,包括必要的模块如文件系统、存储管理、缓存机制、SQL解析、日志管理、权限划分及容灾机制。深入探讨了索引模块,分析了二叉查找树、B树、B+树、Hash索引和位图索引的数据结构及其优缺点。
本文详细介绍了关系型数据库的设计原理,包括必要的模块如文件系统、存储管理、缓存机制、SQL解析、日志管理、权限划分及容灾机制。深入探讨了索引模块,分析了二叉查找树、B树、B+树、Hash索引和位图索引的数据结构及其优缺点。
1、如何设计一个关系型数据库
关系型数据库的模块

- 首先需要用于 存储 的文件系统;
- 单纯有物理结构的存储是肯定不行的,就需要逻辑结构的程序实例;
- 将逻辑结构映射到物理结构,管理存储信息的 存储管理 模块;
- 为优化执行效率,方便快速查询,需要 缓存机制 ;
- 方便外界指令控制操作数据库,需要 SQL解析 ;
- 记录对数据库的操作等,以便查看数据库信息,需要 日志管理 ;
- 对数据库操作的权限问题,就需要有 权限划分;
- 除了有正常功能,还需要能应付异常情况,就有了 容灾机制;
- 最后为了提高数据库的查询效率和支持并发,就需要 索引管理 和 锁管理;
2、索引模块
2.1、索引的数据结构
2.1.1、二叉查找树
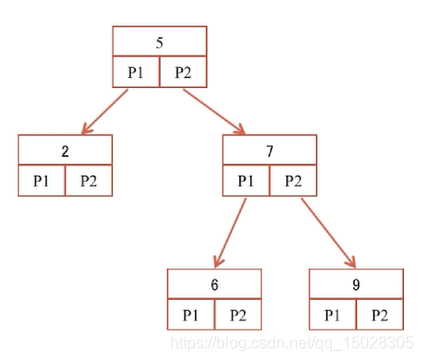
每个节点有一个关键字,大于当前关键字向右子树方向寻找,小于则向左查找。
上图所示二叉树,既是二叉查找树,还是平衡二叉树(左右子树高度差值不超过一)。时间复杂度为O(logn);
缺点:每个节点都是一个关键字,会发生一次读写(IO),由于二叉树最多只能有两个孩子,这样数据量大之后,就会导致查找一个数据深度过深,频繁发生IO,效率不比全表扫描高。
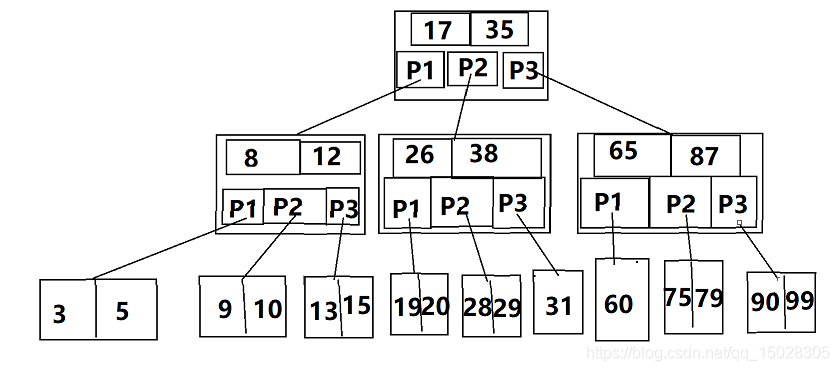
2.1.2、B树(B - Tree)
为了减少磁盘的IO次数,就出现了多叉树——m阶B树。
m阶B树定义:
- 根节点至少有两个孩子
- 每个节点最多m个孩子 【m>=2】
- 除了根和叶子的其他节点至少有ceil(m/2)个孩子【ceil向上取整】
- 所有叶子位于同一层
- 节点中:
①关键字K升序排序
②关键字个数n满足:[ceil(m/2)-1]<=n<=m-1;
③非叶子节点的孩子指针P必须满足:P[i]∈(K[i-1],k(i))
如图,三阶B树(因为课件中的图,和他讲的定义3不符合,就没用课件中的图)
2.1.3、B+树(B+ - Tree)
PS:MySQL的索引是基于B+树的结构进行查询
2.1.3.1、B树和B+树的区别:
- 非叶子节点的子树指针与关键字个数相同
- 非叶子节点的子树指针P,P[i]指向关键字范围为[K[i],K[i+1]]的子树
- B+树的非叶子节点仅用来索引,并不存储数据,叶子结点存储数据
- 叶子结点均有一个链指针指向下一个叶子结点(多项查询时不必重新从根节点开始,而是通过链指针继续向下查找)
如图:
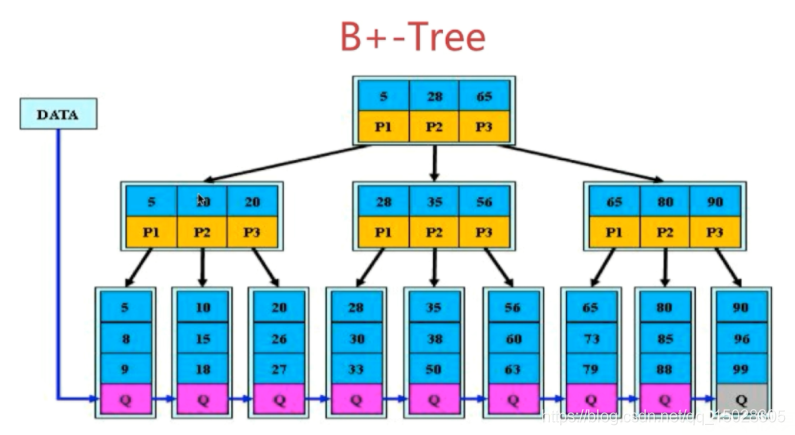
2.1.3.2、B+树更适合用来做存储索引
- 磁盘IO次数减少,读写代价更低【因为只有叶子结点存储数据】
- 不论是范围查询还是单点查询,查询效率都更加稳定【因为链指针和树的高度更低,且数据一次性写入】
- 更有利于对数据库的扫描【链指针】
2.1.4、Hash索引
计算Hash值,进行查找,查询效率更高。定点查询。(结构类似于HashMap)
结构如图:
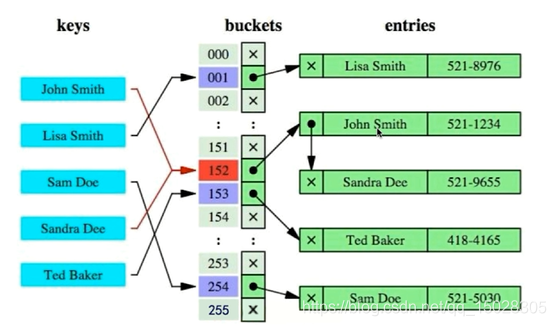
缺点:
- 仅能满足“IN”和“=”,不能范围查询【因为计算Hash值,定点查询】
- 对于数据排序、部分索引键查询、表扫描无法实现
- 遇到大量数据Hash值相同情况,性能不一定比B-Tree索引高
2.1.5、位图(BitMap)索引
Oracle支持位图索引,非主流索引
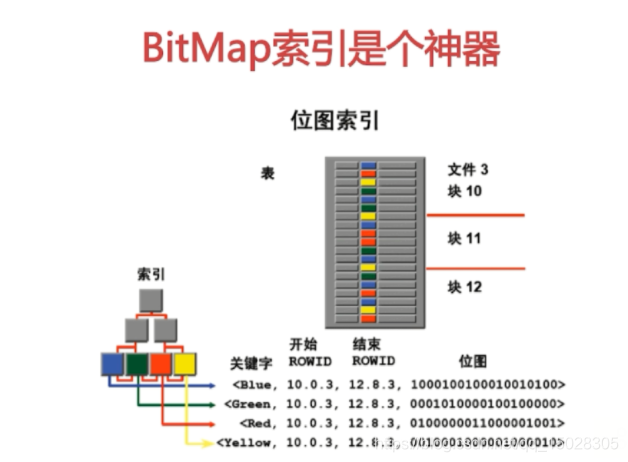
如图,看关键字Blue,开始位置和结束位置之间的位图中,1代表true,看表中蓝色位于[0,4,7,…,],所以位图中的0位置的值为1,4位置为1……

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









