




1.HBase介绍
HBase是一种Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、 实时读写的分布式数据库。利用Hadoop HDFS存储HBase的数据文件,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为HBase分布式协同服务。主要用来存储非结构化和半结构化的松散数据。
2.HBase数据模型
| RowKey | TimeStamp | Column Family01 | Column Family02 | ||
| name | age | job1 | job2 | ||
| 10001 | t1 | tom | 25 | enginer | manager |
| 10002 | t2 | lily | 22 | dancer | dancer |
Row Key:
- 决定一行数据的唯一标识
- RowKey是按照字典顺序排序的
- Row key最多只能存储64k的字节数据
Column Family列族 & qualifier列:
- HBase表中每列都归属于某个列族,列族必须作为表模式(schema) 定义的一部分预先给出。如create 'test','course'
- 列名以列族作为前缀,每个列族都可以有多个列成员。如CF1:q1,CF2:qw
- 权限控制、存储以及调优都是在列族层面进行
- HBase把同一列族里面的数据存储在同一目录下,由几个文件保存
Timestamp时间戳:
- HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
- 时间戳的类型是64位整型。
- 时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。
- 时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突, 就必须自己生成具有唯一性的时间戳。
Cell单元格:
- 由行和列的坐标交叉决定;
- 单元格是有版本的(由时间戳来作为版本)
- 单元格的内容是未解析的字节数组Byte[],cell中的数据是没有类型的,全部是字节码形式存储。
- 由{row key,column(=<family> +<qualifier>),version}唯一确定的单元。
3.HBase架构
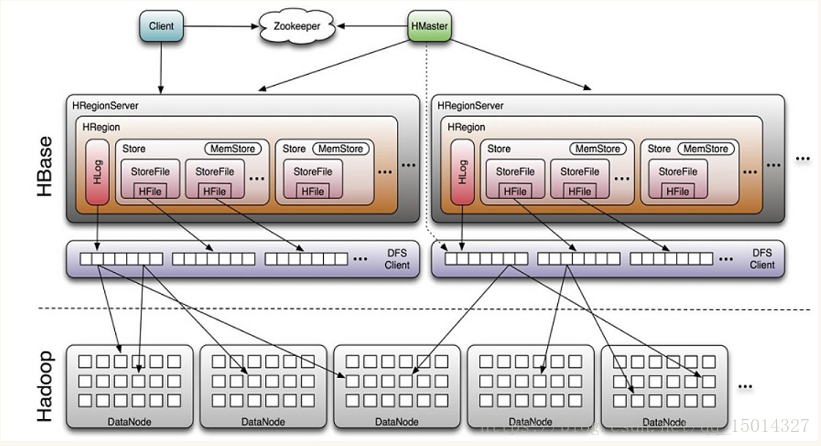
Client
- 包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
- 保证任何时候,集群中只有一个master
- 存贮所有Region的寻址入口。
- 实时监控Region server的上线和下线信息。并实时通知Master
- 存储HBase的schema和table元数据
Master
- 为Region Server分配Region
- 负责Region Server的负载均衡
- 发现失效的Region Server并重新分配其上的Region
- 管理用户对Table的增删改操作
RegionServer
- Region server维护Region,处理对这些Region的IO请求
- Region server负责切分在运行过程中变得过大的Region
HLog(WAL log)
- HLog文件就是一个普通的Hadoop Sequence File,Sequence File的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了Table和Region名字外,同时还包括Sequence Number和TimeStamp,TimeStamp是"写入时间",Sequence Number的起始值为0,或者是最近一次存入文件系统中Sequence Number。
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
Region
- Table中所有的行都按照Row Key的字典序进行排列
- Table在行的方向上分割为多个Region
- Region是按大小分割的,每个表开始只有一个Region,随着数据增多,Region不但增大。当增大到一个阈值时,Region就会等分两个新的Region,之后会有越来越多的Region。
- Region是HBase中分布式存储和负载均衡的最小单元,不同Region分布到不同RegionServer上。
- 一个HRegionServer管理多个HRegion。
- 我们通过"Table + StartRowKey + RegionId"来确定HRegion。
Storefile
- 一个Region由一个或多个Store组成,一个Store对应一个Column Family。
- Store包括内存中的Memstore和HDFS上的Storefile。写操作先写入Memstore,当Memstore中的数据达到某个阈值,HRegionServer会启动FlashCache进程写入Storefile,每次写入形成单独的一个Storefile。
- 当Storefile文件的数量增长到一定阈值后,系统会进行合并。在合并过程中进行版本合并和删除工作(majar),形成更大的Storefile。
- 当一个HRegion中所有Storefile的文件大小加起来超过一定阈值后,会把当前HRegion分割为两个,并由HMaster分配到相应的HRegionServer服务器,实现负载均衡。
- 客户端检索数据,先在MemStore找,找不到再找Storefile。
- HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元表示不同HRegion可以分布在不同的HRegion Server上。
- HRegion由一个或者多个Store组成,每个Store保存一个Column Family。
- 每个Strore又由一个MemStore和0至多个StoreFile组成。
4.HBase安装与配置
Apache HBase官网提供了默认配置说明、参考的配置实例。我们安装方式为完全分布式,且使用独立的ZooKeeper协同服务保持HA。在安装HBase之前确保已经安装好了ZooKeeper。
(1) 下载Apache HBase
从官网上面下载最新的二进制版本:hbase-1.2.6-bin.tar.gz,然后解压。
# 解压命令
tar -zxvf hbase-1.2.6-bin.tar.gz
# 配置环境变量
vi ~/.bash_profile
export HBASE_HOME=/home/hbase/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
# 使用环境变量生效
source ~/.bash_profile(2) 配置hbase-site.xml
编辑 $HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>slave1,slave2,slave3</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hbase/zookeeper-data</value>
<description>
注意这里的zookeeper数据目录与hadoop ha的共用,也即要与zoo.cfg中配置的一致
</description>
</property>
<property>
<name>hbase.master</name>
<value>master:60000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name> #时间同步允许的时间差
<value>180000</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:8020/hbase</value>
<description>这是RegionServers共享的目录,官网多次强调这个目录不要预先创建,
hbase会自行创建,否则会做迁移操作,引发错误。
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>分布式集群配置,这里要设置为true,如果是单节点的,则设置为false
The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description>
</property>
</configuration>
(3)配置regionserver文件
编辑 $HBASE_HOME/conf/regionservers文件,输入要运行RegionServer的主机名
slave1
slave2
slave3(4)配置backup-masters文件 (master备用节点)
HBase支持运行多个master节点,因此不会出现单点故障问题,但只能有一个活动的管理节点(active master),其余为备用节点(backup master)。编辑$HBASE_HOME/conf/backup-masters文件进行配置备用管理节点的主机名
slave2(5) 配置hbase-env.sh文件
编辑$HBASE_HOME/conf/hbase-env.sh配置环境变量。我们单独配置的zookeeper,所以将配置文件中HBASE_MANAGES_ZK 设置为false
export HBASE_MANAGES_ZK=false(6) 启动HBase
使用$HBASE_HOME/bin/start-hbase.sh指令可以启动整个集群。为了更加深入了解HBase启动过程,我们对各个节点依次启动。经查看start-hbase.sh,里面的启动顺序如下:
if [ "$distMode" == 'false' ]
then
"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master $@
else
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" $commandToRun zookeeper
"$bin"/hbase-daemon.sh --config "${HBASE_CONF_DIR}" $commandToRun master
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \
--hosts "${HBASE_REGIONSERVERS}" $commandToRun regionserver
"$bin"/hbase-daemons.sh --config "${HBASE_CONF_DIR}" \
--hosts "${HBASE_BACKUP_MASTERS}" $commandToRun master-backup
fi即:使用hbase-daemon.sh命令依次启动zookeeper、master、regionserver、master-backup。
因此,我们也按照这个顺序,在各个节点进行启动(确保Hadoop HDFS运行)
- 启动zookeeper
zkServer.sh start &- 启动hadoop分布式集群
# 启动 journalnode(master,slave1,slave2,slave3)
hdfs journalnode &
# 启动 namenode active(master)
hdfs namenode &
# 启动 namenode standby(slave2)
hdfs namenode &
# 启动ZookeeperFailoverController(slave1,slave2)
hdfs zkfc &
# 启动 datanode(slave1,slave2,slave3)
hdfs datanode &- 启动hbase master(master)
hbase-daemon.sh start master &- 启动hbase regionserver(slave1,slave2,slave3)
hbase-daemon.sh start regionserver &- 启动hbase backup-master(slave2)
hbase-daemon.sh start master --backup &- HBase 测试使用
hbase shell
# 查看集群状态和节点数量
hbase(main):001:0> status
1 active master, 1 backup masters, 4 servers, 0 dead, 0.5000 average load
5.HBase优缺点
(1) Hbase的优点
- 半结构化或非结构化数据:对于数据结构字段不能确定的数据适合用HBase,因为HBase支持动态添加列。
- 记录很稀疏:RDBMS每行数据的列是固定的,出现某列值为null就会浪费空间。HBase中值为null的列不会被存储,这样既节省了空间又提高了读性能。
- 多版本号数据:依据Row key和Column key定位到的Value能够有随意数量的版本号值,因此对于需要存储变动历史记录的数据,用HBase是很方便的。
- 高可用支持瞬间高写入量: WAL(记录日志)解决高可用,支持PB级数据,put性能高。适用于插入比查询操作更频繁的情况。比如,对于历史记录表和日志文件。
- 业务场景简单: 不需要太复杂的操作,如:交叉列,交叉表,事务,连接等。
(2) Hbase的缺点
- 单一RowKey固有的局限性决定了它不可能有效地支持多条件查询
- 不适合于大范围扫描查询
- 不直接支持 SQL 的语句查询

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









