






现在系统登录页面的验证码一般都是图片形式,不论是UI测试还是接口测试,都要输入识别结果。图片里面有些是英文字母,有些是数字的四则运运算,不论是什么形式,本质的解决方法是对识别结果进行分割,然后提取。
1、Python的requests库响应方式content和text的区别
在Python的requests库中,当你发送一个HTTP请求并获取响应时,响应对象提供了多种方法来访问返回的数据,其中content和text是最常用的两种。它们的主要区别在于数据的类型和处理方式。
content
- 类型:字节字符串(
bytes) - 内容:原始的二进制响应内容。
- 使用场景:
- 当你需要处理非文本数据(如图片、视频、音频等)时。
- 当你需要对响应内容进行二进制操作时。
text
- 类型:字符串(
str) - 内容:响应内容的字符串表示,
requests会根据响应头中的Content-Type自动解码。 - 使用场景:
- 当你需要处理文本数据(如HTML、JSON、XML等)时。
- 当你需要对响应内容进行字符串操作时。
这里我们要处理的是图片,所以选择对response.content进行处理。
2、将响应字节字符串转化为图片,并进行识别
3、对识别结果进行处理
关键步骤:使用正则表达式匹配数字和运算符
4、查看图片及计算结果
试了很多次,识别成功率还是很高的,但是也会有失败的情况,所以在编写登录功能的地方要加上重试机制
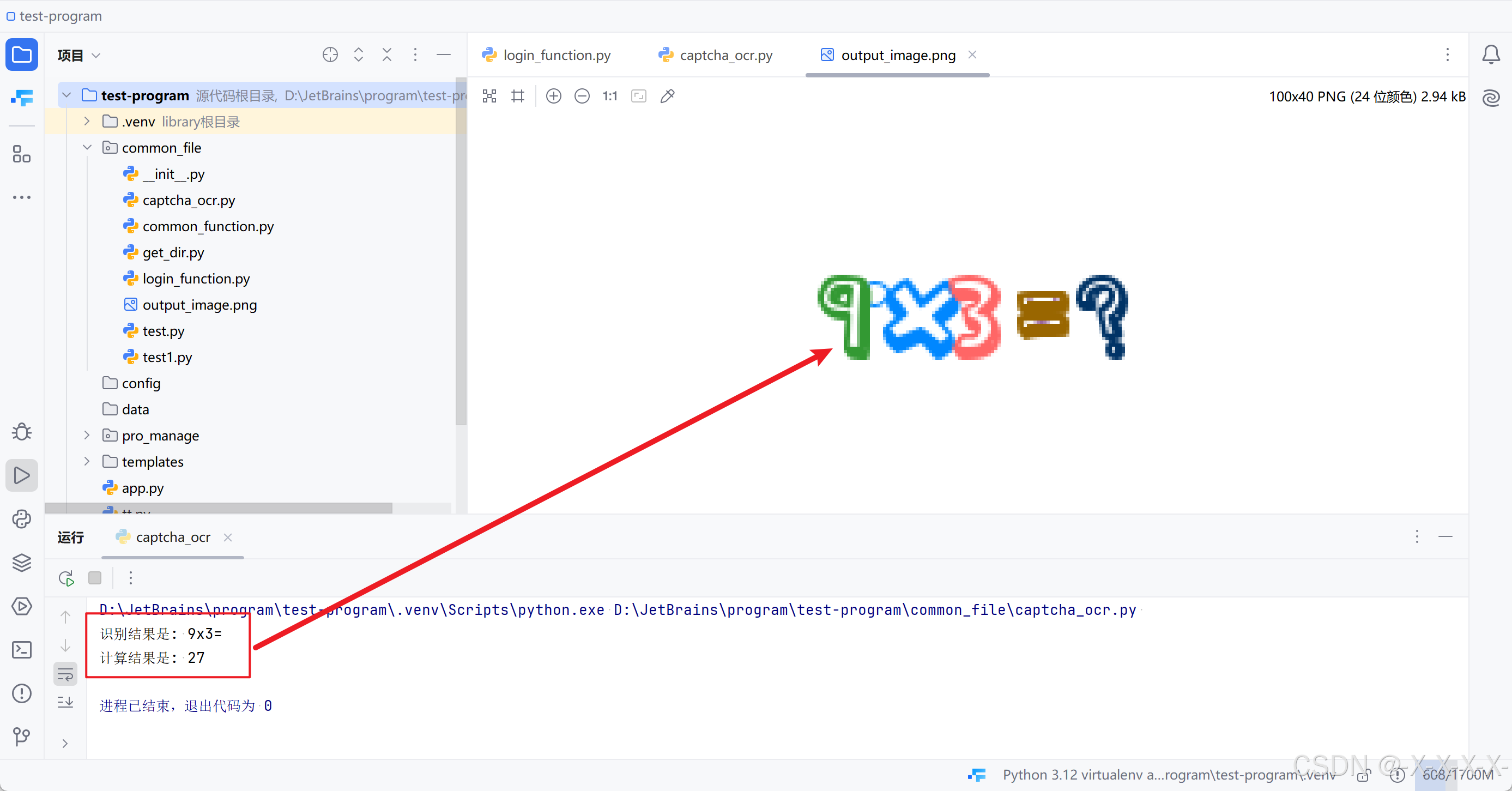
5、完整代码
import re
import uuid
import requests
import ddddocr
# print(randomStr)
class GetVerifyCode:
def __init__(self, url):
# print(url)
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
}
resp = requests.get(self.url, headers=self.headers)
image_data = resp.content
code = self.get_code(image_data)
# self.randomStr=randomStr
self.result = self.get_result(code)
# 将字节字符串转化为图片,并进行识别
def get_code(self, image_data):
# data=image_data
image_path = "output_image.png"
# 保存图片
try:
with open(image_path, 'wb') as f:
f.write(image_data)
except IOError:
print("Error: can not write data to file.")
ocr = ddddocr.DdddOcr(show_ad=False)
# 读取图片并进行识别
with open('output_image.png', 'rb') as f:
dd = f.read()
code = ocr.classification(dd)
print(f"识别结果是: {code}")
return code
# 获取识别结果
def get_result(self, code):
try:
# 使用正则表达式匹配数字和运算符
match = re.match(r"(\d+)\s*([+\-*/x/X])\s*(\d+)", code)
if match:
num1 = int(match.group(1)) # 第一个数字
operator = match.group(2) # 运算符
num2 = int(match.group(3)) # 第二个数字
# 根据运算符计算结果
if operator == '+':
result = num1 + num2
elif operator == '-' or operator == '——':
result = num1 - num2
elif operator == 'x' or operator == 'X' or operator == '*':
result = num1 * num2
elif operator == '/':
result = num1 / num2
else:
result = None
print(f"计算结果是: {result}")
return result
else:
# print("未能识别到有效的四则运算表达式")
return None
except Exception as e:
print(f"计算失败: {e}")
return None
if __name__ == '__main__':
randomStr = str(uuid.uuid4())
url = 'https://www.xxx.com/xxx/code?randomStr=' + randomStr
obj = GetVerifyCode(url)
code = obj.result
# print(code)
6、登录功能
此处配合验证码识别附上登录功能
import requests
from common_file import captcha_ocr
import uuid
base_url = 'https://www.xxx.com/xxx/auth/xxx/token?'
username = '133xxxxxxxxxxx'
password = 'Yexxxxxxxxxxxxxx%3D'
class DoLogin:
def __init__(self, username, password):
i=1
while i<=3:
self.randomStr = str(uuid.uuid4())
# print(self.randomStr)
code_url = 'https://www.xxx.com/xxx/code?randomStr=' + self.randomStr
obj = captcha_ocr.GetVerifyCode(code_url)
self.code = obj.result
self.username = username
self.password = password
url=base_url+'username={}&randomStr={}&code={}&grant_type=password&scope=server'.format(self.username, self.randomStr, self.code)
# print(url)
# 表单数据
data ='password={}'.format(self.password)
headers = {
"Accept": "application/json, text/plain, */*",
"Authorization": "Basic xxxxxxxxxxxxxxxxxxxx", # 根据你提供的值,确保正确
"Content-Type": "application/x-www-form-urlencoded"
}
try:
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200:
# print(response.text)
self.token = response.json()['access_token']
break
else:
print('第{}次尝试登录失败,错误信息:{}'.format(i,response.text))
self.token = None
i=i+1
except requests.exceptions.RequestException as e:
print('第{}次尝试登录失败,错误信息:{}'.format(i,e))
self.token = None
i=i+1
if self.token is None:
print('三次尝试登录失败,退出测试!')
else:
print('登录成功,token为:{}'.format(self.token))
if __name__ == '__main__':
obj = DoLogin(username, password)

















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









