







 Light-Head R-CNN是一种两阶段目标检测器,它结合了Faster R-CNN和RFCN的优点,通过减少通道数来降低内存消耗并保持高效处理。该模型通过采用轻量级头部结构显著减少了显存占用,同时通过改进如large separable convolution等提升了检测精度。
Light-Head R-CNN是一种两阶段目标检测器,它结合了Faster R-CNN和RFCN的优点,通过减少通道数来降低内存消耗并保持高效处理。该模型通过采用轻量级头部结构显著减少了显存占用,同时通过改进如large separable convolution等提升了检测精度。
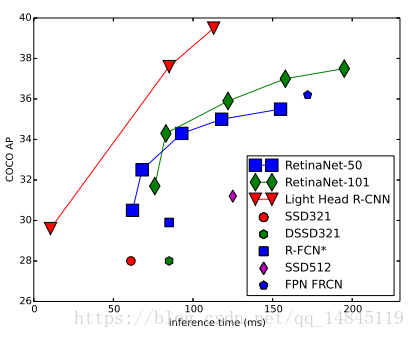
Face++ 2017年的作品。主要基于RFCN的改进,基于2种基础框架backbone得出2种模型。以ResNet101为基础网络的大模型,具有比faster RCNN更高的精度,以类似Xception为基础网络的小模型,比SSD,YOLO更快。
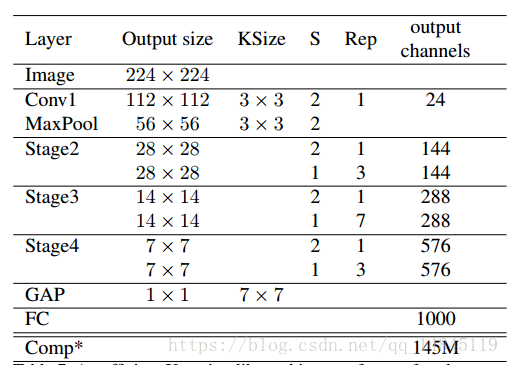
类似Xception的网络结构如下图所示。
下图分析了faster RCNN,RFCN,Light-Head R-CNN,三个检测框架的区别。
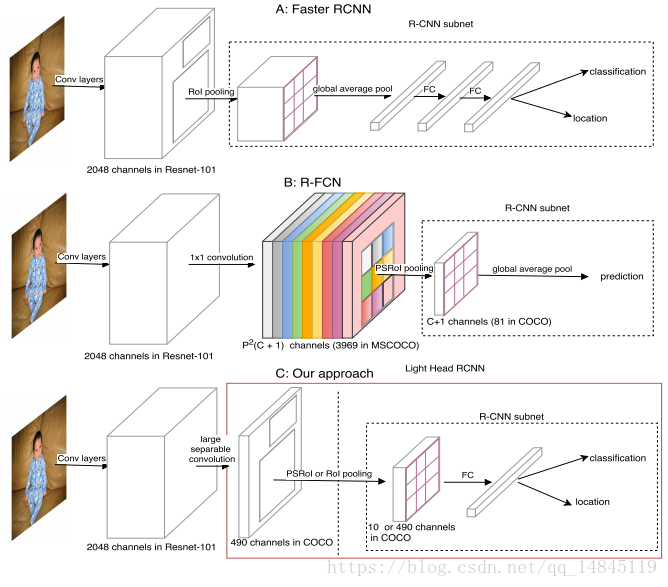
三个框架都是由3个部分组成,RPN(左),ROI warping(中),RCNN subnet(右)。而本文的标题,Light-Head 所指的就是ROI warping(中),RCNN subnet(右)这两部分的轻量化。
Faster RCNN对于ROI区域是通过循环处理的,这样的话,时间上就会有较大的浪费。
RFCN则对这点做了改进,在RPN模块后,首先通过1*1卷积,将feature map的维度扩大到P*P*(c+1),然后通过PSROI pooling(position-sensitive pooling)实现了对所有ROI的基于batch的提取,可以有效的减少运行时间。引入的缺点就是P*P*(c+1)和(c+1)这样通道的feature map是很费显存的,尤其是当分类的类别较大时,例如coco中c=80。
Light-Head R-CNN则吸收了Faster RCNN和RFCN的共同的优点。首先,Light-Head R-CNN为了达到节省显存消耗,还能基于batch将所有ROI一起处理,因此做了一个操作。首先保证了结构还是RFCN的结构,然后将ROI warping中的channel数目大大减少。在RFCN中P*P*(c+1)=7*7*(80+1)=3969,而在Light-Head R-CNN中P*P*(c+1)=7*7*(9+1)=490,channel数目大大减少,大大的减少显存的开销。然后在RCNN subnet中可以有2种选择,如果经过
PSROI pooling可以得到10 channels的featuremap,如果经过ROI pooling可以得到490 channels的featuremap。作者的测试发现ROI pooling在这个模块中要比PSROI pooling准确性高点。
同时引入的需要做的另外一个结构的变动就是,在RFCN中,C=80为需要分类的类别数目,而在Light-Head R-CNN中C=9,是为了减少显存的消耗而设置的一个数字,和分类的类别数目没关系。因此,在RFCN的RCNN subnet模块中,可以直接通过global average pooling,然后进行类别的分类和框的回归。而在Light-Head R-CNN却不可以这样操作。为了达到可以进行分类和回归的目的,作者这里又借鉴了Faster RCNN的思想,通过一个全连接来实现分类和回归。
网络的另外一个改进地方就是RPN后面,Light-Head R-CNN进行了large separable convolution操作,提升0.7%个点。本质目的就是为了增大感受野。
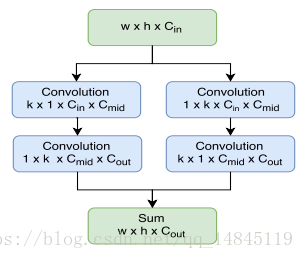
具体的实现就是上图所示的1*k和k*1的2个卷积的使用。思想借鉴的Inception的思想。论文中k=15。
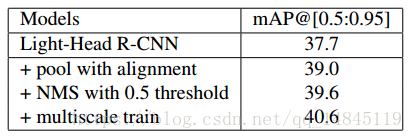
后续提升精度的操作:
(1)引入mask RCNN中ROI align,提升1.3%个点
(2)将NMS阈值由0.3改为0.5,提升0.6%个点
(3)多尺度训练,提升1.0%个点
(4)OHEM难例挖掘
references:
Light-Head R-CNN: In Defense of Two-Stage Object Detector

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









