




FacetField的使用
在使用FacetField创建的field后,后面使用它进行统计查询的时候,总是报出如下的异常信息:
java.lang.ArrayIndexOutOfBoundsException: 2
at org.apache.lucene.facet.taxonomy.IntTaxonomyFacets.increment(IntTaxonomyFacets.java:88)
at org.apache.lucene.facet.taxonomy.IntTaxonomyFacets.increment(IntTaxonomyFacets.java:80)
at org.apache.lucene.facet.taxonomy.FastTaxonomyFacetCounts.count(FastTaxonomyFacetCounts.java:88)
at org.apache.lucene.facet.taxonomy.FastTaxonomyFacetCounts.<init>(FastTaxonomyFacetCounts.java:54)
at org.apache.lucene.facet.taxonomy.FastTaxonomyFacetCounts.<init>(FastTaxonomyFacetCounts.java:44)
跟踪源代码发现是如下两个地方的值不一致导致的:
public abstract class IntTaxonomyFacets extends TaxonomyFacets {
/** Per-ordinal value. */
private final int[] values;
private final IntIntScatterMap sparseValues;
FastTaxonomyFacetCounts类中下面代码中计算出的ord值超出了上面代码中values的长度。
for (int doc = it.nextDoc(); doc != DocIdSetIterator.NO_MORE_DOCS; doc = it.nextDoc()) {
final BytesRef bytesRef = dv.binaryValue();
byte[] bytes = bytesRef.bytes;
int end = bytesRef.offset + bytesRef.length;
int ord = 0;
int offset = bytesRef.offset;
int prev = 0;
while (offset < end) {
byte b = bytes[offset++];
if (b >= 0) {
prev = ord = ((ord << 7) | b) + prev;
increment(ord);
ord = 0;
} else {
ord = (ord << 7) | (b & 0x7F);
}
}
}
为什么会超出呢,我们继续往下面分析。那么这个int[] values里面到底是存的是什么呢?我们继续看下面的代码:
protected IntTaxonomyFacets(String indexFieldName, TaxonomyReader taxoReader, FacetsConfig config, FacetsCollector fc) throws IOException {
super(indexFieldName, taxoReader, config);
if (useHashTable(fc, taxoReader)) {
sparseValues = new IntIntScatterMap();
values = null;
} else {
sparseValues = null;
values = new int[taxoReader.getSize()];
}
}
从上面的代码中我们可以看出它的值为new int[taxoReader.getSize()],是由taxoReader.getSize()决定大小的。再看TaxonomyReader中有如下的一个size
/**
* Returns the number of categories in the taxonomy. Note that the number of
* categories returned is often slightly higher than the number of categories
* inserted into the taxonomy; This is because when a category is added to the
* taxonomy, its ancestors are also added automatically (including the root,
* which always get ordinal 0).
*/
public abstract int getSize();
它的实现类DirectoryTaxonomyReader中的方法:
@Override
public int getSize() {
ensureOpen();
return indexReader.numDocs();
}
到这里大家应该能够看出这个values的长度就是当前reader下的文档数决定的。继续往下跟踪代码发现:
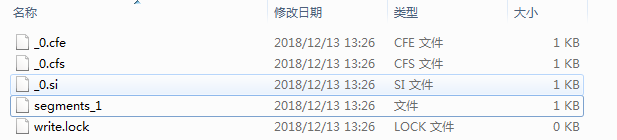
TaxonomyWriter生成的上面的文件异常,只有一个segments,而正常的像下面这样有两个segments:
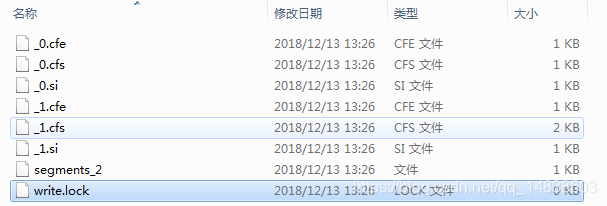
到这里才联想起来我在代码中的TaxonomyWriter可能没有提交,去检查,发现的确没有提交,加上commit之后问题解决。
后记
文中values的长度是由每个segments中的文档数之后决定的,本文中我明明只有一个文档,TaxonomyWriter为什么会有两个segment,一个segment里面的文档数是1个,还有一个里面的文档数是4个。这里就没有搞明白为什么会多出这4个出来。有知道的朋友可以指点下。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









