







Task02目录
这次任务分两大块,Transformer机制和词向量生成过程。
一 Transformer机制
1. Attention机制
1.1 产生背景
- 拿翻译模型举例,在过去基于RNN类的Encoder-Decoder模型,都是编码器先处理源句子的整个输入,生成一个上下文向量(代表模型对输入句子的理解),最后传到解码器里面作为初始状态,一个字一个字地一次输出要翻译的意思。
- 问题来了,如果要输入日常包含二三十个词,勉强能对付,但如果一篇文章呢?如果是一本书呢?上下文向量(固定大小的权重)对这种原来的信息理解是不是会存在精度丢失问题,甚至说会不会忘记很早之前的重要信息。这就是长程依赖问题(梯度消失),除此之外,抓不住文章的重点,也就是某些关键词很重要,它无法保留在上下文向量里。
- 有个团队在2015年提出,在生成上下文向量时候,把所有输入过的词都考虑进来,在这个基础上把每个词赋予它们在整个输入中所对应的重要性。
1.2 怎么发挥作用?
步骤(举例翻译)
- 1.先把原文内容输入计算机,得到一个初始向量C。
- 2.目前任务是生成下一个词,问题就是生成下一个词应该往哪个方向生成?结合原文产生的词向量和当前已经翻译的译文,构建出一个方向向量Q(这个是随着不断生成而动态变化)
-
- 那么生成下一个词这个任务有个方向为Q,要综合原文内容来理解,就拿这个Q来匹配原文内容看看原文里哪个词是与Q相关的,越相关的分数就越高,不重要的就越低,组成向量叫QKV
- 4.通过QKV,我们就可以让计算机在理解生成下一词的时候应该往哪个方向给投入多点精力。
- 5.具体表现就是加权求和,哪个部分重要,权重就大,反之亦然
害,我惨不忍睹
1.3 全局注意力与局部注意力
- 全局注意力:考虑所有隐藏状态,将它们连接成一个矩阵,并与正确维度的权重矩阵相乘。问题是随着输入大小增加,矩阵大小也在增加,计算量超级大
PS:软注意力,是全局注意力,在视觉任务中,所有图像块都有其一定的权重;而硬注意力,指一次只考虑一个图像块
- 局部注意力:它不考虑所有输入,只考虑一部分
PS:如何实现?预测对齐位置(预测原文中哪个位置对于现在要生成的位置最重要),定义注意力窗口(在生成位置的附近框起一个大小固定的窗口),计算上下文向量(窗口内输入序列的加权平均值)
太难,不懂讲啥
2. Transformer概述
2.1 Transformer模型
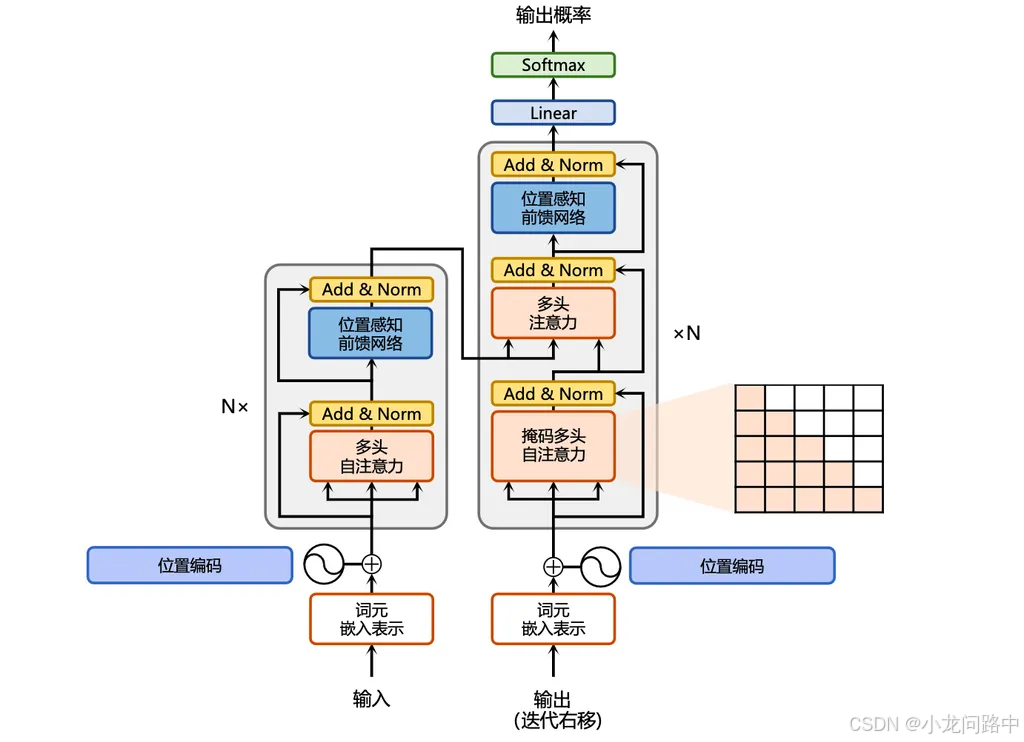
- Encoder-Decoder架构。可以看到左右两边都有N层,每一层都相同的子层(有自注意力机制与前馈网络),这样有助于全面理解原文。也能够生成上下文丰富的输出序列。
- 位置编码:这是Transformer特有的地方,虽然注意力很强大,但是它没有考虑原文内容的顺序,例如"他打我"和"我打他",这两句话的意思区别很大。
- 多头注意力。这个能够同时关注原文的不同部分,多个QKV各自进行自注意力计算,这就是多样化上下文信息的来由。
- 前馈网络:可以看到每一层都包含这种网络,能捕捉序列元素之间复杂关系。
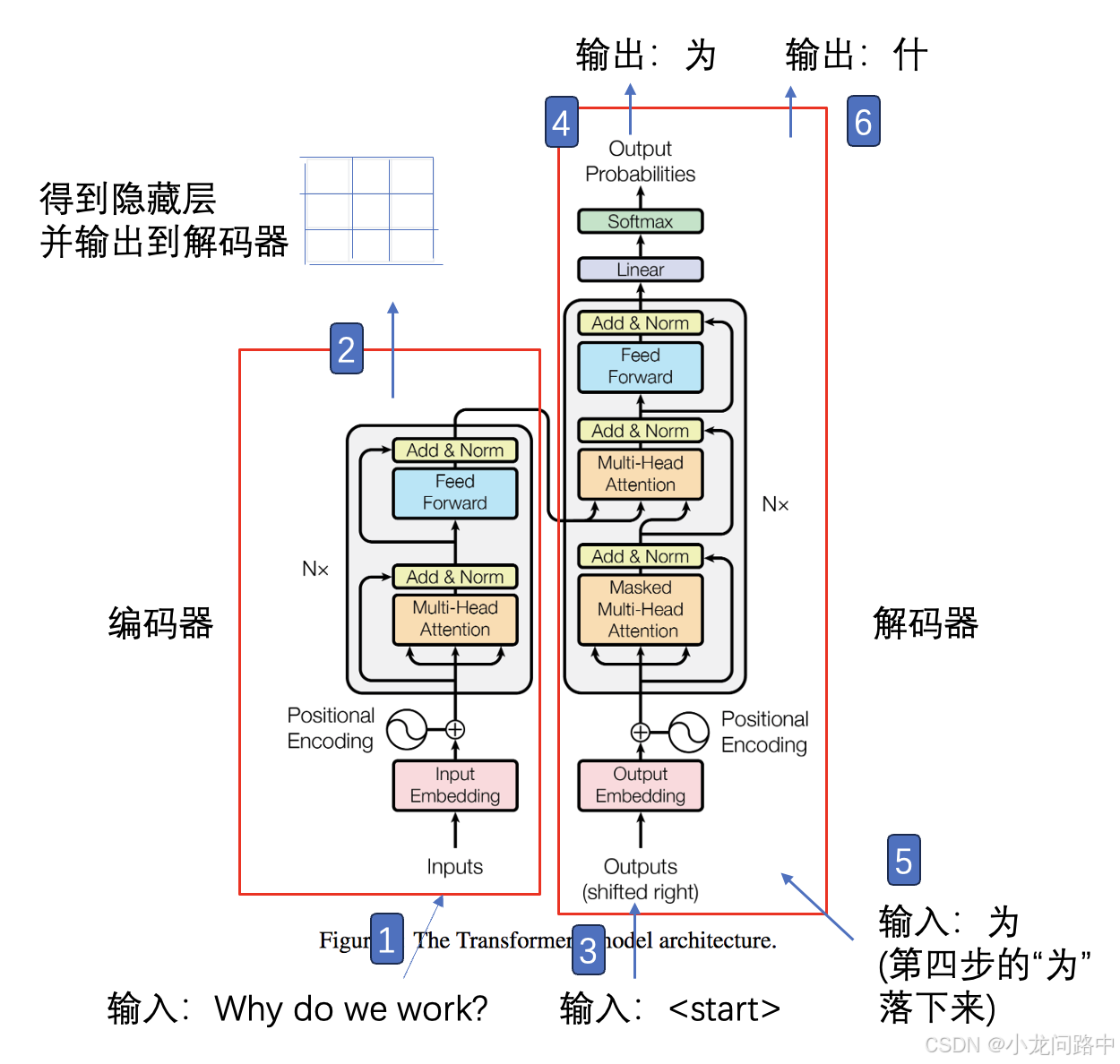
从这张图我们可以看到,本质上就是Encoder-Decoder模型。
2.2 Transformer工作流程
举例两句话在transformers中是怎么理解的:
- The cat drank the milk because it was hungry。
- The cat drank the milk because it was sweet。
显然,第一句的it是指猫,第二句的it指的是牛奶。
第一句在理解it时候,会给原文所有单词进行打分来决定后面理解的侧重点在哪里,在这里会给cat这个单词打的分数会变高。相应地第二个句子在理解it时候,就会给milk这个单词打分会打得高。
前面说的是一个打分,也就是一个注意力,那么多个注意力就会打多个分,这里举第一句的例子,那么它打第二个分数时候,就会在hungry这个单词打得分相对更高。这么下来,第一个分数cat,第二个分数hungry,两个分数突出的单词结合到翻译的单词上,是有助于正确翻译原文的。
2.3 Transformer对seq2seq模型的影响
- 1.RNN结构的摒弃:从而使用self-attention机制来处理序列数据。
- 2.引入self-attention。允许模型在处理每个序列元素时候考虑其他元素的信息,从而有效建立全局依赖关系。
- 3.位置编码。由于其不包含递归关系,故本身无法捕捉元素的位置信息。为了解决这个问题,引入了position encoding机制,为每一个元素提供一个位置向量。该向量与元素的嵌入向量相加,就能得到带位置信息的元素表示。
- 4.是对Encoder-Decoder模型的改进。它在编码器和解码器端,搞了很多层,每层都包含self-attention和前馈网络子层,提高模型表达能力
- 5.训练效率提升。注意是跟自注意力机制相关,能够并行化处理,提高训练过程的计算效率。
- 6.NLP领域的应用推广。机器翻译,文本摘要,问答系统的应用中得到性能显著提升
- 7.促进预训练发展。例如BERT这种预训练模型。
2.4 迁移学习
1.预训练概念:从头开始训练模型的方式,没有任何先验知识加持。代价就是时间和经济成本极高。
2.迁移学习:大部分情况下,我们不会从头开始训练,都是把别人训练好的模型移植到我们自己的模型,再进行二次训练,例如通过我们自己构建的任务语料库,来让其适应新的任务。
- 预训练模型的流行:Transformer这种架构使得预训练阶段中能够把大量未标注文本学习出丰富的语言表示。
- 语言表示的学习:Transformer主要通过掩码语言模型MLM与下一句预测NSP 来学习语言表示。MLM通过随机掩码输入序列中某个词来预测这些词;NSP主要是判断两个句子是否在原始文本中是连续的。这些任务有效帮助模型学习深层的语言规律和语义信息。
- 迁移学习的推动。得到预训练模型,就可以在下游任务中进行微调,无须从头训练
- 模型规模扩大。模型参数增加,模型能力也会提升
- 多语言和多模态的扩展。Transformer这种结构易于扩展多语言和多模态任务。
3.Transformer vs CNN vs RNN

假设,输入序列长度和输出长度都为n,每个元素维度都是d。可以看到Transformer的计算效率很高。
- Q、K、V概念引入
Q就是query,你想要查询的关键字
K就是key,所有的关键字
V就是value,所有关键字对应的实体内容。
对于Q中某个向量q,将其与某个key向量进行点积相乘,得到的就是相关程度或者相似程度,这样的计算复杂效率为O(d),由于你有n个key向量,那就是所有点乘操作复杂度为O(nd)。然后考虑下你的Q也有n个那么多,整个计算下来复杂度为O(nn*d)
4. Input嵌入
位置编码 是Transformer中引入进来表示序列元素位置信息的一种机制,通常不是模型参数的一部分,并不会在模型训练中通过反向传播进行更新。
Encoder端包含词嵌入向量(Word Embedding)和位置向量(Positon encoding)
4.1 词嵌入
word embedding本质上是一个查找表lookup table,根据输入的索引,通常是单词的序号,来获取单词对应的向量表示。
在pytorch中,nn.Embedding层用于实现word embedding
对于nn.embedding层的权重,有两种使用
1)使用别人训练好的word embedding,并固化其参数。例如有Word2Vec,GloVe或者FastText等。加载它们后,可以设置这些参数不可训练,这样做有什么好处?利用本身包含的语义信息,在样本不足情况下,有助于提高模型性能。
2)随机初始化word embedding层参数,均匀分布或者高斯分布这样的初始化。在训练过程中,embedding也在不断地改进,这样做能够根据特定任务进行调整,捕捉到预训练的word embedding没有的信息。
4.2 位置编码
用来帮助Transformer考虑单词在序列中的位置因素来理解上下文意思。
4.2.1 具有位置信息的编码实现
选用公式构造的Position Embedding了,优点是不需要训练参数,而且即使在训练集中没有出现过的句子长度上也能用.
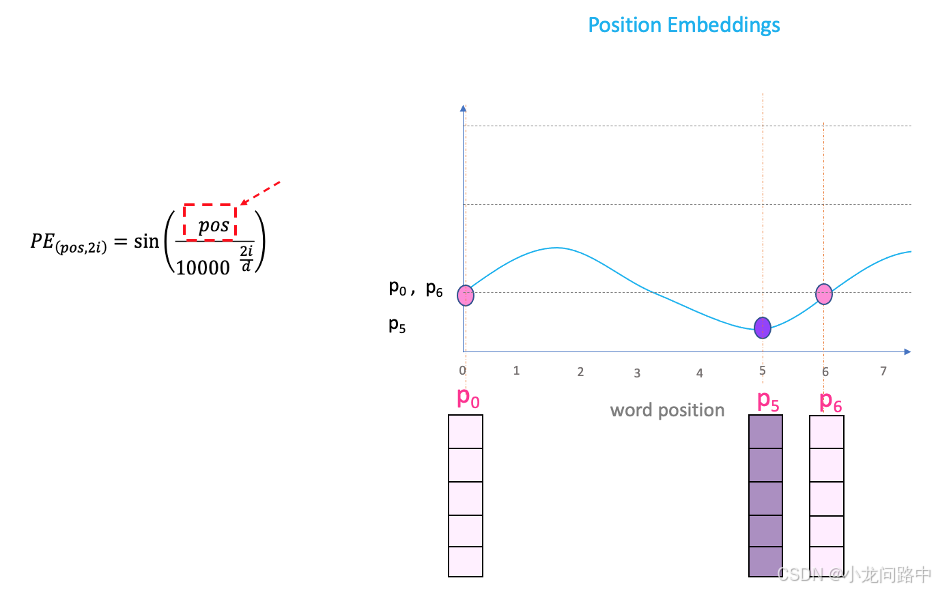
pos表示为d维的位置向量,这个PE(pos,i),pos表示一个d维的位置向量,i表示第i个元素。可以发现,第0个和第6个的值一样,虽然在不同的位置,这是i发挥的效果,如果i改变,将会读取不同频率的位置嵌入值,最终会为P0和P6在不同嵌入维度上提供不同的值。
4.2.2 为什么选用公式构造Position Encoding
Position Encoding本身是一个绝对位置的信息。但在语言中,相对位置信息也很重要。这里我们只说相关的内容。是由于一个三角恒等式起的作用。这种机制有利于捕捉序列中不同位置之间的相对位置关系。
4.2.3 相对位置信息
相对位置:周期性变化规律。
Positional Encoding 公式通过结合周期性、位置差异、维度特定编码和平滑变化,为序列中的每个单词提供了一个独特的编码,这反映了单词的相对位置信息,并允许 Transformer 模型在处理序列数据时考虑到这些位置信息。
更直观的理解:
通过交替使用正弦和余弦,模型能够捕捉到不同维度的“方向”,因为正弦和余弦的波形虽然有相似之处,但它们有不同的“起始点”和“相位”。这类似于人类在日常生活中,通过不同的参照点来判断一个物体的方位——例如,通过东和北两个方向来确定方位,而不是仅依赖于一个方向。
二 词向量生成过程
1. 引言
- 什么是词向量,就是把文字转化为计算机可理解的语言,转化为向量形式的数字信息。
- 主流的词向量方法有两种:独热编码和分布式表征。
分布式表征:简单来说就是让相关或者相似的词在距离上更加相近。
Word2Vec 模型是生成分布式表征词向量模型的方式之一。
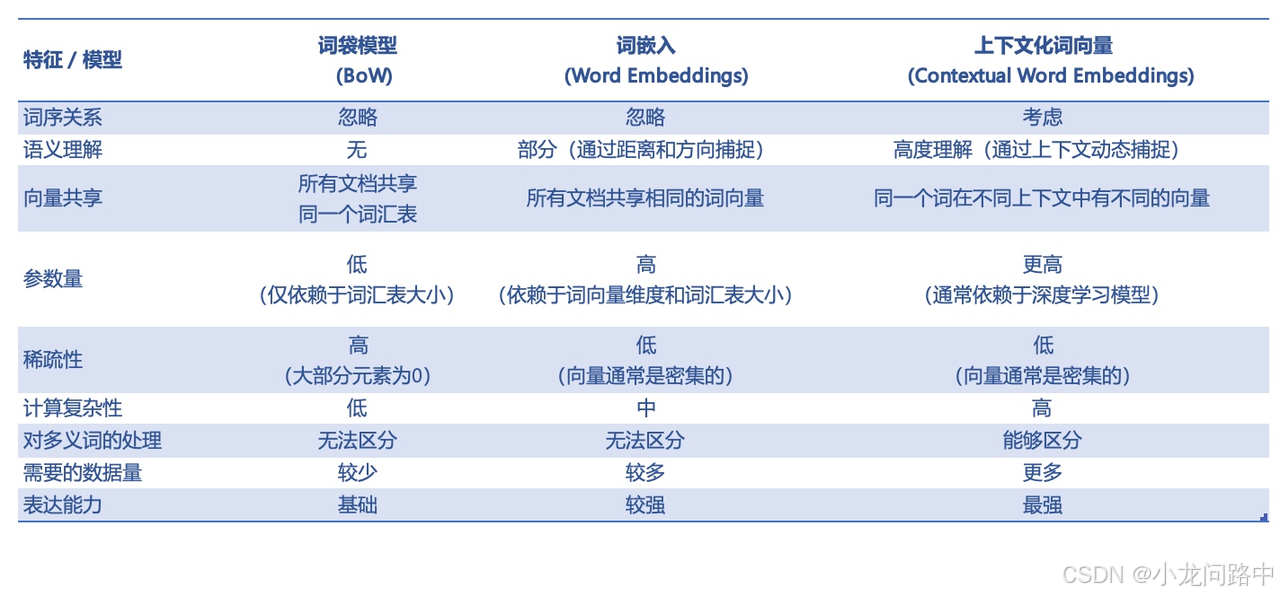
一般有三种,分别是词袋模型,词嵌入,上下文词嵌入
 ## 2.基于统计的词向量
## 2.基于统计的词向量
2.1 词袋模型,bag of words, BoW
忽略词语顺序和语法结构,单纯把文本看作是词的集合。例如"我打你"和"你打我"的意思是一样的。当然可以用二元词袋模型来区分,但是当上下文长度变化,是不是n元词袋规模就不太现实了
2.2 TF - IDF(词频 - 逆文档频率)
TF-IDF是在词袋模型基础上,考虑了词频(TF)在一个文本中出现的频率,而IDF是表示一个单词在整个语料库中的稀有程度。通常TF与IDF相乘,可以得到一个单词在特定文中的重要性。
虽然一定程度上突出单词在文本中的重要性,对分类任务有帮助。但是还是没考虑单词的语义信息。
3.基于神经网络的词向量
3.1 Word2Vec
Word2Vec一般有两种,CBOW 和 Skip-Gram
CBOW:根据上下文预测中心词。
Skip-Gram:刚好相反,它是依靠中心词预测上下文。
优点:能够学习到单词的语义信息。
3.2 GloVe(Global Vectors for Word Representation)
GloVe基于统计的方法和神经网络的方法。基于单词的共现矩阵来学习词向量。
共现矩阵记录了单词在语料库中的共现次数。例如,在一个语料库中,“苹果”和“水果”共现的次数可能会比较多,而“苹果”和“汽车”共现的次数会比较少。
特点:能够有效地利用语料库中的统计信息,学习到单词之间的语义和语法关系。
训练速度相对较快,并且在一些大规模的语料库上能够取得很好的性能。
4.词向量的完整生成过程
4.1 数据收集与预处理阶段
- 收集语料库:更大、更多样化的语料库能够让词向量更好地捕捉语言的各种语义和语法特征。
- 文本清洗:例如清除HTML中的标签信息
- 分词:中文或者日语,都需要分词;而英文基本上靠空格来分割。
- 构建词汇表:统计语料库中出现的所有不重复单词,形成词汇表。为每个单词分配一个唯一的索引。
4.2 模型选择与架构设计阶段
- 词袋模型(BoW):单词的集合,忽略单词的顺序和语法结构。它的架构相对简单,通过统计每个单词在文本中的出现次数来构建文本的向量表示。
- TF - IDF模型:在词袋模型的基础上,考虑了单词的重要性。它通过计算词频(TF)和逆文档频率(IDF)的乘积来衡量一个单词在特定文本中的重要性。
- Word2Vec模型:有CBOW(Continuous Bag - of - Words)和Skip - Gram两种主要架构,这两种架构都包含输入层、隐藏层和输出层。输入层接收单词的表示(如one - hot编码),经过隐藏层的转换,在输出层输出预测结果,通过反向传播算法不断调整模型的权重,以优化预测效果。
- GloVe模型:基于单词的共现矩阵来学习词向量。它通过统计单词在语料库中的共现次数构建共现矩阵,然后利用这个矩阵来学习单词之间的语义关系。
词向量模型的目标函数:
对于基于统计的模型,目标函数可能是最小化文本表示与实际统计特征之间的差异。例如,在TF - IDF模型中,要使得计算得到的TF - IDF值能够准确反映单词在文本中的重要性。
对于基于神经网络的模型,目标函数通常是最小化预测结果与真实标签之间的误差。
在Word2Vec的CBOW架构中,目标是最小化预测的中心词概率分布与真实中心词之间的交叉熵损失;
在Skip - Gram架构中,是最小化根据中心词预测上下文单词的概率分布与真实上下文单词之间的交叉熵损失;
在GloVe模型中,目标函数是最小化预测的共现概率与实际共现概率之间的差异。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









