







文章目录
1.seq2seq概述
1.1 是什么?
输入一个序列,输出另一个序列。哪一边的序列长度都是可变的。
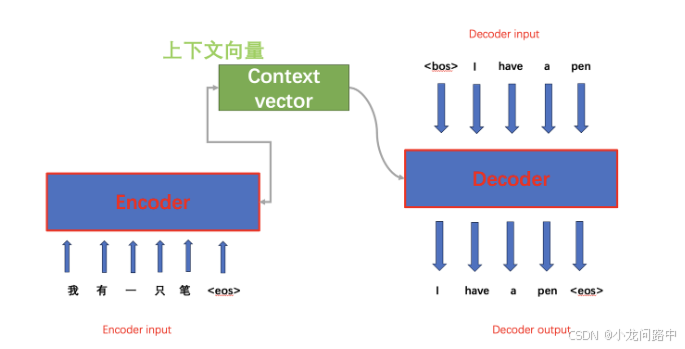
1.使用BOS和EOS能够减少对Padding的依赖(模型可以根据这些标记来识别序列的边界)。
2.与通信原理有一定相似性,尤其是编码-传输-解码过程来看
1.2 它的由来
在seq2seq出来之前,图像领域中的输入输出都是固定长度的向量,如果长度产生变化,会使用Padding来解决,目的转换成固定长度格式,方便输入到那些本来设定要固定输入长度的模型中。
弊端:一般来说,在计算损失时候,需要一些特殊操作来忽略这种padding带来影响。一般用mask方法。这点在强化学习环境中对无效动作的处理是相同的。但是,机器翻译、语音识别、对话系统等,这些场景是预先不知道长度,是一种局限性,这方面的研究自2013年成为了热点,seq2seq框架也就进入大家法眼了。
1.3 seq2seq的评价
- 优点
- 端到端学习。无需显式的特征提取
- 可变长序列的处理。适应不同长度的数据
- 信息压缩与表示。其实这点很像今年的新书‘揭秘大模型’开章提到大模型本质是信息的压缩,揭示了信息论中的信息压缩公式与GPT的损失函数是何其相似。
- 可扩展性。能够与CNN,RNNs等无缝结合,能够处理更复杂的场景和任务。
摘抄:
Seq2Seq的优势之一为高效的信息提炼。
想象一下把一大段文字浓缩成一个简短的摘要,编码器就是做这样的事情,它把整个输入序列压缩成一个精华的上下文向量。然后,解码器就像一个作家,根据这个摘要重新创作出一篇完整的文章。
- 缺点
- 信息丢失。由于输入的信息全部都压缩成一个固定维度的上下文向量,必定存在信息压缩的问题。
- 短期记忆限制。由于RNN有着鱼儿一般的记忆,难以获取更早之前的关键信息,限制了跨度比较长的信息保存能力。
- 暴漏偏差。训练时候解码器的每一个字符的输出是使用答案来作为解码器的输入,这就导致模型在推理的自回归生成模式存在不一致,导致模型在真正测试时候无法很好适应其错误输出。
其实我也遇过类似场景,这里很像强化学习里面一个场景,一个小白什么都不懂,试图让专家手把手地教,结果小白还是没怎么学好,这就是模仿学习存在的问题。
2.Encoder-Decoder模型
2.1 “Seq2Seq”和“Encoder-Decoder”的关系
- Seq2Seq模型(着重输入序列,输出序列这样的过程)是Encoder-Decoder架构的一种具体应用。
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法。
Encoder-Decoder将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。 Encoder 又称作编码器。它的作用就是“将现实问题转化为数学问题”。 Decoder 又称作解码器,作用是“求解数学问题,并转化为现实世界的解决方案”。
2.2 Encoder-Decoder 的工作流程
2.2.1 编码器(Encoder)
Encoder是个RNN类型网络,里面由LSTM或者GRU类型循环单元堆叠起来。它们按照序列的先后顺序处理里面每一个元素,然后生成上下文向量,这个上下文向量毫无疑问是用来保存当前输入序列的所有信息,包括理解当前序列的含义。
工作流程:
- 词序列转换:先把每一个词,转成一个高维空间的稠密向量,这个转换是通过一个叫word embedding层得到。这个高维是指这个词在多个维度包含的语义信息,可以预训练得到,也可以跟随当前任务一起训练。
- 序列处理。这个是动态的概念,因为这类模型是一个字一个字地输入的过程,因为有了RNN类型结构参与,这个Encoder的输入整体就是除了输入一个当前字符,还要包含之前RNN类型结构对历史输入过所有字符的信息理解。如果学术点地描述就是结合了当前的隐藏状态信息(其实就是RNN类型对过去信息的记忆理解)
- 生成上下文向量。上下文向量是一个固定长度的向量,它通过汇总和压缩整个序列的信息,有效地编码了输入文本的整体语义内容。这个向量随后将作为Decoder端的重要输入,用于生成目标序列。
2.2.2 解码器(Decoder)
解码器采用RNN架构,输入是上述的上下文向量。并以此合成目标序列的各个元素。
工作流程:
- 初始化参数。具体是Xavier初始化(适用于Sigmoid或Tanh激活函数)和He初始化(通常用于ReLU激活函数),这两种方法旨在维持各层激活值和梯度的大致稳定性,从而优化训练过程。
- 编码器输出。得出上下文向量
- 解码器输入。
- 初始化隐藏状态
- 标记开始符号(bos:begin of sequence)
- 输入序列。训练过程中,可能是模型预测的一个词,也可能答案的一个词。
- 上下文向量。这个向量汇总了所有输入信息。如果是带有注意力机制,上下文向量则是动态变化,反映当前解码为位置对原序列不同部分的关注程度。
- 注意力权重。如果模型采用了注意力模型,那么每个字符输出的解码器还会接受一组注意力权重。
2.2.3 seq2seq训练过程
1.准备数据。分词,编码,分段。
2.初始化模型参数。这里指初始化解码器
3.编码器处理。通过RNN处理,得到上下文向量。
4.解码器训练过程。初始化隐藏状态,输入,解码器RNN运作,输出,损失函数计算。
5.反向传播和参数更新。
6.循环训练。
7.评估和调优。这里提到的(Teacher Forcing)其实我理解为某种模仿学习,存在的问题可以通过梯度裁剪来防止参数更新偏离。
2.3 Encoder-Decoder的应用
- (文本 – 文本)
- 机器翻译
- 对话机器人
- 诗词生成
- 代码补全
- 文章摘要
- (音频 – 文本)
- 语音识别
- (图片 – 文本)
- 图像描述生成
2.4 Encoder-Decoder的缺陷
Encoder-Decoder 就是面临类似的问题:当输入信息太长时,会丢失掉一些信息。
3. Attention的提出与影响
3.1 发展历程
2014年,Seq2Seq模型特出,由编码器-解码器组成。
2015年,注意力提出的Seq2Seq模型
2017年,自注意力与Transformer模型
2018年,多头注意力与BERT
3.2 类型

3.3 Attention解决信息丢失的问题
Attention模型特点是Encoder不再将整个输入序列编码为固定长度的向量,就是编码成多个向量这样的序列,解决信息过长,信息丢失的问题。
3.4 Attention 的核心工作
Attention 的核心工作就是“关注重点”。在特定场景下,解决特定问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









