 Java核心技术精讲
Java核心技术精讲




 本文深入讲解Java基础,包括多线程、线程池、JVM内存管理、数据库连接池、MySQL事务隔离级别、索引优化、分布式锁、Redis持久化等关键知识点,以及Spring框架中的有状态与无状态bean的区别。
本文深入讲解Java基础,包括多线程、线程池、JVM内存管理、数据库连接池、MySQL事务隔离级别、索引优化、分布式锁、Redis持久化等关键知识点,以及Spring框架中的有状态与无状态bean的区别。
待持续更新。
--------------------------------------------------------------------------------------------------------------------------
Java基础
基础面试题
https://www.cnblogs.com/roucheng/p/javatimu.html
https://www.cnblogs.com/rese-t/p/8018696.html
https://blog.youkuaiyun.com/u013305864/article/details/79383225
1. map
concurrenthashmap https://www.cnblogs.com/ITtangtang/p/3948786.html
HashTable容器使用synchronized来保证线程安全,HashMap可以允许插入null key和null value,HashTable和ConcurrentHashMap都不可以插入null key和null value
MultiValueMap: 一个Key存多个Value,一个键对应多个值,Spring的内部实现是LinkedMultiValueMap
2. volatile与synchronized的区别 https://www.cnblogs.com/tf-Y/p/5266710.html
volatile告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
3. java的对象锁和类锁:
对象锁是用于对象实例方法,或者一个对象实例上的,类锁是用于类的静态方法或者一个类的class对象上的。我们知道,类的对象实例可以有很多个,但是每个类只有一个class对象,所以不同对象实例的对象锁是互不干扰的,但是每个类只有一个类锁。必须注意的是,其实类锁只是一个概念上的东西,并不是真实存在的,它只是用来帮助我们理解锁定实例方法和静态方法的区别的。
4. HTTP长连接、短连接
长连接短连接操作过程
短连接的操作步骤是:
建立连接——数据传输——关闭连接...建立连接——数据传输——关闭连接
长连接的操作步骤是:
建立连接——数据传输...(保持连接)...数据传输——关闭连接
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是资源浪费。
而像WEB网站的http服务一般都用短连接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连接好。
5. Java同步调用,异步调用,回调机制 http://www.cnblogs.com/xrq730/p/6424471.html
模块间调用
在一个应用系统中,无论使用何种语言开发,必然存在模块之间的调用,调用的方式分为几种:
(1)同步调用
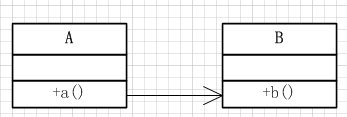
同步调用是最基本并且最简单的一种调用方式,类A的方法a()调用类B的方法b(),一直等待b()方法执行完毕,a()方法继续往下走。这种调用方式适用于方法b()执行时间不长的情况,因为b()方法执行时间一长或者直接阻塞的话,a()方法的余下代码是无法执行下去的,这样会造成整个流程的阻塞。
(2)异步调用
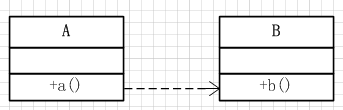
异步调用是为了解决同步调用可能出现阻塞,导致整个流程卡住而产生的一种调用方式。类A的方法方法a()通过新起线程的方式调用类B的方法b(),代码接着直接往下执行,这样无论方法b()执行时间多久,都不会阻塞住方法a()的执行。但是这种方式,由于方法a()不等待方法b()的执行完成,在方法a()需要方法b()执行结果的情况下(视具体业务而定,有些业务比如启异步线程发个微信通知、刷新一个缓存这种就没必要),必须通过一定的方式对方法b()的执行结果进行监听。在Java中,可以使用Future+Callable的方式做到这一点,具体做法可以参见我的这篇文章Java多线程21:多线程下其他组件之CyclicBarrier、Callable、Future和FutureTask。
(3)回调

最后是回调,回调的思想是:
- 类A的a()方法调用类B的b()方法
- 类B的b()方法执行完毕主动调用类A的callback()方法
这样一种调用方式组成了上图,也就是一种双向的调用方式。
6. 抽象类和接口的区别
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
7. nginx和tomcat的区别,动静资源的区别
https://blog.youkuaiyun.com/qq805934132/article/details/83305135
线程
1. 多线程: https://www.cnblogs.com/lwbqqyumidi/p/3804883.html
sleep和wait的区别:sleep方法没有释放锁:不让出资源,wait方法释放了锁:使得其他线程可以使用同步控制块或者方法
2. 线程池中的线程是重复使用的,即一次使用完后,会被重新放回线程池,可被重新分配使用。因此,ThreadLocal线程变量,如果保存的信息只是针对一次请求的,放回线程池之前需要清空这些Threadlocal变量的值(或者取得线程之后,首先清空这些Threadlocal变量的值)
线程池
https://www.cnblogs.com/superfj/p/7544971.html
https://www.cnblogs.com/zedosu/p/6665306.html
1. Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2. ThreadPoolExecutor线程池参数设置技巧: https://www.cnblogs.com/waytobestcoder/p/5323130.html
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满
- 若线程数小于最大线程数,创建线程
- 若线程数等于最大线程数,抛出异常,拒绝任务
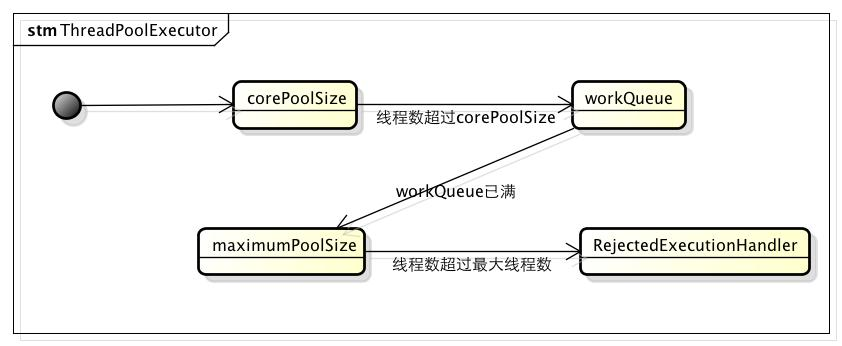
3. 线程池threadpoolexecutor的RejectedExecutionHandler(拒绝策略)
AbortPolicy
该策略是线程池的默认策略。使用该策略时,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。
DiscardPolicy
这个策略和AbortPolicy的slient版本,如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常。
DiscardOldestPolicy
这个策略从字面上也很好理解,丢弃最老的。也就是说如果队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列。
因为队列是队尾进,队头出,所以队头元素是最老的,因此每次都是移除对头元素后再尝试入队。
CallerRunsPolicy
使用此策略,如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行。就像是个急脾气的人,我等不到别人来做这件事就干脆自己干。
自定义
如果以上策略都不符合业务场景,那么可以自己定义一个拒绝策略,只要实现RejectedExecutionHandler接口,并且实现rejectedExecution方法就可以了。具体的逻辑就在rejectedExecution方法里去定义就OK了。
JVM
1. jvm内存划分
https://www.cnblogs.com/dingyingsi/p/3760447.html
https://www.cnblogs.com/dolphin0520/p/3613043.html
2. jvm回收算法
https://www.cnblogs.com/cielosun/p/6674431.html
3. Java中堆和栈的区别
堆因为是不连续的,所以分配的内存是在运行期确认的,因此大小不固定。
栈是连续的,所以分配的内存大小要在编译期就确认,大小是固定的。
堆存放的是对象的实例和数组。因此该区更关注的是数据的存储,堆放的是对象。
栈存放:局部变量,操作数栈,返回结果。栈放的是对象的引用。
PS:静态变量放在方法区,静态的对象还是放在堆。
堆对于整个应用程序都是共享、可见的。
栈只对于线程是可见的。所以也是线程私有。他的生命周期和线程相同。
程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题,不会直接传递对象本身
4. 元空间和永久代都是对jvm规范中方法区的实现,他们的区别在于:元空间并不在虚拟机中,而是使用本地内存。
5. JVM 类加载机制详解 http://www.importnew.com/25295.html
6. 双亲委派模型: https://www.cnblogs.com/wxd0108/p/6681618.html
双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载.
如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器完成。每个类加载器都是如此,只有当父加载器在自己的搜索范围内找不到指定的类时(即ClassNotFoundException),子加载器才会尝试自己去加载。
基础知识
fastjson JSON.toJSONString时保留null值
如无设置,null对应的key会被过滤掉;可以使用 fastjson 的 SerializerFeature 序列化属性
Fastjson的SerializerFeature序列化属性
QuoteFieldNames———-输出key时是否使用双引号,默认为true
WriteMapNullValue——–是否输出值为null的字段,默认为false
WriteNullNumberAsZero—-数值字段如果为null,输出为0,而非null
WriteNullListAsEmpty—–List字段如果为null,输出为[],而非null
WriteNullStringAsEmpty—字符类型字段如果为null,输出为”“,而非null
WriteNullBooleanAsFalse–Boolean字段如果为null,输出为false,而非null
分布式,高并发
待更新。
Spring
对有状态bean和无状态bean的理解
根据经验,对有状态的bean使用prototype作用域,而对无状态的bean使用singleton作用域。每次通过Spring容器获取prototype定义的bean时,容器都将创建一个新的Bean实例,每个Bean实例都有自己的属性和状态,而singleton全局只有一个对象。1、有状态就是有数据存储功能。有状态对象(Stateful Bean),就是有实例变量的对象,可以保存数据,是非线程安全的。在不同方法调用间不保留任何状态。
2、无状态就是一次操作,不能保存数据。无状态对象(Stateless Bean),就是没有实例变量的对象.不能保存数据,是不变类,是线程安全的。
有状态会话bean :每个用户有自己特有的一个实例,在用户的生存期内,bean保持了用户的信息,即“有状态”;一旦用户灭亡(调用结束或实例结束),bean的生命期也告结束。即每个用户最初都会得到一个初始的bean。
无状态会话bean :bean一旦实例化就被加进会话池中,各个用户都可以共用。即使用户已经消亡,bean 的生命期也不一定结束,它可能依然存在于会话池中,供其他用户调用。由于没有特定的用户,那么也就不能保持某一用户的状态,所以叫无状态bean。但无状态会话bean 并非没有状态,如果它有自己的属性(变量),那么这些变量就会受到所有调用它的用户的影响,这是在实际应用中必须注意的。
1.无状态会话Bean
从字面意思来理解,无状态会话Bean是没有能够标识它的目前状态的属性的Bean。例如:
public class A {
public A() {}
public String hello() {
return "Hello 谁?";
}
}
public class Client {
public Client() {
A a = new A();
System.out.println(a.hello());
A b = new A();
System.out.println(b.hello());
}
}
在Client中生成了两个A的实例,不管是对象a还是b,它们是没有状态的。对于Client来说a和b是没有差别的(但a != b)。所以同一个无状态会话Bean的实例都是相同的,可以被不同的客户端重复使用。
2.状态会话Bean
至于状态会话Bean,可以这样理解:它是有存储能力的。也就是说至少有一个属性来标识它目前的状态。例如:
public class B {
private String name;
public B(String arg) {
this.name = arg;
}
public String hello() {
return "Hello" + this.name;
}
}
public class Client {
public Client() {
B a = new B("中国");
System.out.println(a.hello());
B b = new B("世界");
System.out.println(b.hello());
}
}
Mysql
1. mysql乐观锁、悲观锁、共享锁、排它锁、行锁、表锁概念
乐观锁不是数据库自带的,需要我们自己去实现。乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。
通常实现是这样的:在表中的数据进行操作时(更新),先给数据表加一个版本(version)字段,每操作一次,将那条记录版本号加1。也就是先查询出那条记录,获取出version字段,如果要对那条记录进行操作(更新),则先判断此刻version的值是否与刚刚查询出来时的version的值相等,如果相等,则说明这段期间,没有其他程序对其进行操作,则可以执行更新,将version字段的值加1;如果更新时发现此刻的version值与刚刚获取出来的version的值不相等,则说明这段期间已经有其他程序对其进行操作了,则不进行更新操作。
悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作,这点跟java中的synchronized很相似,所以悲观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我们直接调用数据库的相关语句就可以了。
共享锁和排它锁是悲观锁的不同的实现,它俩都属于悲观锁的范畴。
共享锁指的就是对于多个不同的事务,对同一个资源共享同一个锁。相当于对于同一把门,它拥有多个钥匙一样。就像这样,你家有一个大门,大门的钥匙有好几把,你有一把,你女朋友有一把,你们都可能通过这把钥匙进入你们家,这就是共享锁。
在执行语句后面加上lock in share mode就代表对某些资源加上共享锁了。
共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
排它锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁。与共享锁类型,在需要执行的语句后面加上for update就可以了。
行锁,由字面意思理解,就是给某一行加上锁,也就是一条记录加上锁。
比如共享锁语句 SELECT * from city where id = "1" lock in share mode;
由于对于city表中,id字段为主键,就也相当于索引。执行加锁时,会将id这个索引为1的记录加上锁,那么这个锁就是行锁。
2. Mysql for update行级锁、表级锁
由于InnoDB 预设是Row-Level Lock,所以只有「明确」的指定主键,MySQL 才会执行Row lock (只锁住被选取的数据) ,否则MySQL 将会执行Table Lock (将整个数据表单给锁住)。
举个例子:
假设有个表单products ,里面有id 跟name 二个栏位,id 是主键。
例1: (明确指定主键,并且有此数据,row lock)
SELECT * FROM products WHERE id='3' FOR UPDATE;
例2: (明确指定主键,若查无此数据,无lock)
SELECT * FROM products WHERE id='-1' FOR UPDATE;
例2: (无主键,table lock)
SELECT * FROM products WHERE name='Mouse' FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>'3' FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE '3' FOR UPDATE;
3. 间隙锁(Next-Key锁)
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,...,100,101,下面的SQL:
|
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。
4. MySQL的四种事务隔离级别
参考链接:https://blog.youkuaiyun.com/qq805934132/article/details/83080646
5. exists, in
无论哪个表大,用not exists都比not in 要快。IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
6. MySQL 数据表的时候一般都有一列为自增 ID,这样设计原因是什么,有什么好处
MyISAM/InnoDB默认用B-Tree索引(可理解为"排好序的快速查找结构")。
InnoDB中,主索引文件上直接存放该行数据,称为聚簇索引。次索引指向对主键的引用;
MyISAM中,主索引和次索引,都指向物理行(磁盘位置);
注意: 对InnoDB来说
1: 主键索引既存储索引值,又在叶子中存储行的数据;
2: 如果没有定义主键,则会使用非空的UNIQUE键做主键 ; 如果没有非空的UNIQUE键,则系统生成一个6字节的rowid做主键;
聚簇索引中,N行形成一个页。如果碰到不规则数据插入时,会造成频繁的页分裂(因为索引要排好序),插入速度比较慢。所以聚簇索引的主键值应尽量是连续增长的值,而不是随机值(不要用随机字符串或UUID),否则会造成大量的页分裂与页移动。
故对于InnoDB的主键,尽量用整型,而且是递增的整型。这样在存储/查询上都是非常高效的。
数据库表一般使用 B+树索引, B+树的叶子节点存放所有指向关键字的指针,节点内部关键字记录和节点之间都根据关键字的大小排列。当顺序递增插入的时候,只有最后一个节点会在满掉的时候引起索引分裂,此时无需移动记录,只需创建一个新的节点即可。而当非递增插入的时候,会使得旧的节点分裂,还可能伴随移动记录,以便使得新数据能够插入其中。
7. Sql优化
待更新。
https://www.cnblogs.com/exe19/p/5786806.html
https://blog.youkuaiyun.com/jie_liang/article/details/77340905
8. 索引失效
待更新。
https://blog.youkuaiyun.com/wuseyukui/article/details/72312574
https://blog.youkuaiyun.com/hehexiaoxia/article/details/54312130
https://www.cnblogs.com/shynshyn/p/7887742.html
https://www.cnblogs.com/duanxz/p/5244703.html
联合索引生效情况
索引是key index (a,b,c). 可以支持a |a,b| a,b,c 3种组合进行查找
组合索引的生效原则是 从前往后依次使用生效,如果中间某个索引没有使用,那么断点前面的索引部分起作用,断点后面的索引没有起作用
9. 数据库连接池
数据库连接池的实现及原理 https://www.cnblogs.com/wym789/p/6374440.html
数据库连接池-常用参数配置及含义
maxActive 连接池支持的最大连接数,这里取值为20,表示同时最多有20个数据库连接。一般把maxActive设置成可能的并发量就行了设 0 为没有限制。
maxIdle 连接池中最多可空闲maxIdle个连接 ,这里取值为20,表示即使没有数据库连接时依然可以保持20空闲的连接,而不被清除,随时处于待命状态。设 0 为没有限制。
minIdle 连接池中最小空闲连接数,当连接数少于此值时,连接池会创建连接来补充到该值的数量
initialSize 初始化连接数目
maxWait 连接池中连接用完时,新的请求等待时间,毫秒,这里取值-1,表示无限等待,直到超时为止,也可取值9000,表示9秒后超时。超过时间会出错误信息
removeAbandoned 是否清除已经超过“removeAbandonedTimout”设置的无效连接。如果值为“true”则超过“removeAbandonedTimout”设置的无效连接将会被清除。设置此属性可以从那些没有合适关闭连接的程序中恢复数据库的连接。
removeAbandonedTimeout 活动连接的最大空闲时间,单位为秒 超过此时间的连接会被释放到连接池中,针对未被close的活动连接
minEvictableIdleTimeMillis 连接池中连接可空闲的时间,单位为毫秒 针对连接池中的连接对象
timeBetweenEvictionRunsMillis / minEvictableIdleTimeMillis 每timeBetweenEvictionRunsMillis毫秒秒检查一次连接池中空闲的连接,把空闲时间超过minEvictableIdleTimeMillis毫秒的连接断开,直到连接池中的连接数到minIdle为止.
10. 分库分表
待更新。
11. MySQL CURRENT_TIMESTAMP 和 ON UPDATE CURRENT_TIMESTAMP
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修
1> CURRENT_TIMESTAMP : 当要向数据库执行 insert操作时,如果有个 timestamp字段属性设为 CURRENT_TIMESTAMP,则无论这个字段有没有set值都插入当前系统时间
2> ON UPDATE CURRENT_TIMESTAMP : 使用 ON UPDATE CURRENT_TIMESTAMP 放在 TIMESTAMP 类型的字段后面,在数据发生更新是该字段将自动更新时间
Oracle
1. Oracle是怎样分页的?
Oracle中使用rownum来进行分页, 这个是效率最好的分页方法,hibernate也是使用rownum来进行oralce分页的
select * from
( select rownum r,a from tabName where rownum <= 20 )
where r > 10
2. Oracle中字符串用什么符号链接?
Oracle中使用 || 这个符号连接字符串 如 ‘abc’ || ‘d’
MYSQL中进行字符串的拼接要使用CONCAT函数
3. 说说oracle中的经常使用到得函数
Length 长度、 lower 小写、upper 大写, to_date 转化日期, to_char转化字符
Ltrim 去左边空格、 rtrim去右边空格,substr取字串,add_month增加或者减掉月份、to_number转变为数字
4. 怎样创建一个一个索引,索引使用的原则,有什么优点和缺点
创建标准索引:
CREATE INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建唯一索引:
CREATE unique INDEX 索引名 ON 表名 (列名) TABLESPACE 表空间名;
创建组合索引:
CREATE INDEX 索引名 ON 表名 (列名1,列名2) TABLESPACE 表空间名;
创建反向键索引:
CREATE INDEX 索引名 ON 表名 (列名) reverse TABLESPACE 表空间名;
5. 怎样创建一个视图,视图的好处, 视图可以控制权限吗?
create view 视图名 as select 列名 [别名] … from 表 [unio [all] select … ] ]
1. 可以简单的将视图理解为sql查询语句,视图最大的好处是不占系统空间
2. 一些安全性很高的系统,不会公布系统的表结构,可能会使用视图将一些敏感信息过虑或者重命名后公布结构
3. 简化查询
可以控制权限的,在使用的时候需要将视图的使用权限grant给用户
Linux
1. su命令和su -命令最大的本质区别就是:
前者只是切换了root身份,但Shell环境仍然是普通用户的Shell;而后者连用户和Shell环境一起切换成root身份了。只有切换了Shell环境才不会出现PATH环境变量错误,报command not found的错误。su切换成root用户以后,pwd一下,发现工作目录仍然是普通用户的工作目录;而用su -命令切换以后,工作目录变成root的工作目录了。用echo $PATH命令看一下su和su - 后的环境变量已经变了。
2. 如何以非root用户(指定用户)开机启动服务:
su - mycount -c "/home/sun/startXX.sh"
3. linux创建删除用户、设置密码、添加用户组
添加用户:useradd -m 用户名 然后设置密码 passwd 用户名
删除用户:userdel -r 用户名
在root权限下,useradd只是创建了一个用户名,如 (useradd +用户名 ),它并没有在/home目录下创建同名文件夹,也没有创建密码,因此利用这个用户登录系统,是登录不了的,为了避免这样的情况出现,可以用 (useradd -m +用户名)的方式创建,它会在/home目录下创建同名文件夹,然后利用( passwd + 用户名)为指定的用户名设置密码。
可以直接利用adduser创建新用户(adduser +用户名)这样在/home目录下会自动创建同名文件夹
删除用户,只需使用一个简单的命令“userdel 用户名”即可。不过最好将它留在系统上的文件也删除掉,你可以使用“userdel -r 用户名”来实现这一目的。
useradd testuser 创建用户testuser
passwd testuser 给已创建的用户testuser设置密码
说明:新创建的用户会在/home下创建一个用户目录testuser
usermod --help 修改用户这个命令的相关参数
userdel testuser 删除用户testuser rm -rf testuser 删除用户testuser所在目录
创建新用户后,同时会在etc目录下的passwd文件中添加这个新用户的相关信息
命令行窗口下用户的相互切换:
su 用户名
说明:su是switch user的缩写,表示用户切换
用户组的添加和删除:
groupadd testgroup 组的添加
groupdel testgroup 组的删除
说明:组的增加和删除信息会在etc目录的group文件中体现出来。
(find locate命令查找文件,可使用正则表达式) (grep ag命令在文件中查找文本, grep pattern file) (which whereis命令)
4. linux查看所有的用户和组信息
cat /etc/passwd查看所有的用户信息
cat /etc/passwd|grep 用户名,用于查找某个用户
cat /etc/group查看所有组信息
cat /etc/group|grep 组名,用于查找某个用户组
groups 查看当前登录用户的组内成员
groups test 查看test用户所在的组,以及组内成员
whoami 查看当前登录用户名
5. kill, killall, pkill
kill [参数] [进程id]
killall [参数] [进程名]
pkill 正在运行的程式名
killall和pkill是相似的,不过如果给出的进程名不完整,killall会报错。pkill或者pgrep只要给出进程名的一部分就可以终止进程。
6. ps aux排序 (查看进程占用内存和cpu) ,top也可以。
按内存升序排列 ps aux --sort=+rss
按内存降序排列 ps aux --sort=-rss
按cpu升序排列 ps aux --sort=+%cpu
按cpu降序排列 ps aux --sort=-%cpu
Docker
Redis
1. Redis分布式锁
思路很简单,主要用到的redis函数是setnx()。首先是将某一任务标识名(这里用Lock:order作为标识名的例子)作为键存到redis里,并为其设个过期时间,如果是还有Lock:order请求过来,先是通过setnx()看看是否能将Lock:order插入到redis里,可以的话就返回true,不可以就返回false。
使用redis的setNX命令实现分布式锁:
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写
返回值:
设置成功,返回 1 。
设置失败,返回 0 。
例子:
redis> EXISTS job # job 不存在
(integer) 0
redis> SETNX job "programmer" # job 设置成功
(integer) 1
redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败
(integer) 0
redis> GET job # 没有被覆盖
"programmer"所以我们使用执行下面的命令
SETNX lock.foo <current Unix time + lock timeout + 1> -
如返回1,则该客户端获得锁,把lock.foo的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
-
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
2 .Redis 总结精讲:https://blog.youkuaiyun.com/hjm4702192/article/details/80518856#commentBox
3. 缓存穿透和缓存雪崩
缓存穿透:请求很多缓存中不存在的数据,由于缓存中都没有,导致这些请求短时间内直接落在了数据库上,导致数据库异常。
缓存雪崩:缓存在同一时间内大量键过期(失效),接着来的一大波请求都落在了数据库中,给后端系统(比如DB)带来很大压力。
4. Redis持久化
持久化之全量写入:RDB,RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入
而RDB持久化也分两种:SAVE和BGSAVE
SAVE是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。
BGSAVE属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
持久化之增量写入:AOF
与RDB的保存整个redis数据库状态不同,AOF是通过保存对redis服务端的写命令(如set、sadd、rpush)来记录数据库状态的,即保存你对redis数据库的写操作
5. Redis有哪些数据结构:字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
6. Redis集群
ActiveMq
1. Activemq 的作用就是系统之间进行通信。 当然可以使用其他方式进行系统间通信, 如果使用 Activemq 的话可以对系统之间的调用进行解耦, 实现系统间的异步通信。 原理就是生产者生产消息, 把消息发送给activemq。 Activemq 接收到消息, 然后查看有多少个消费者, 然后把消息转发给消费者, 此过程中生产者无需参与。 消费者接收到消息后做相应的处理和生产者没有关系
2. 通信方式:publish(发布)-subscribe(订阅)(发布-订阅方式),p2p(point-to-point)(点对点)
3. ActiveMQ提供了插件式的消息存储,主要有有如下几种:
1.AMQ消息存储-基于文件的存储方式,是以前的默认消息存储
2.KahaDB消息存储-提供了容量的提升和恢复能力,是现在的默认存储方式
3.JDBC消息存储-消息基于JDBC存储的
4.Memory消息存储-基于内存的消息存储

Zookeeper
开发框架
Spring
1. PropertyUtils.copyProperties和BeanUtils.copyProperties使用区别
说说实际开发中BeanUtils和PropertyUtils的区别:
当遇到dest中参数是java.util.Date类型,orig参数类型是java.lang.String类型时,使用PropertyUtils会报错,发现PropertyUtils有自动类型转换功能,而java.util.Date恰恰是其不支持的类型;
也就是说,在自动转换类型时,报错了。
查了一些解决办法,大概就是重写PropertyUtils的copy方法,使其支持java.util.Date,不过我觉得日期转换有多种格式需求,不能仅仅转成一个yyyy-MM-dd格式,所以我认为这种方法复杂并且有缺陷。
而BeanUtils没有自动转换功能,遇到参数名相同,类型不同的参数不会进行赋值。所以在使用完BeanUtils的copy方法后,手工再把类型不同的参数处理下就行了。
项目业务流程
架构设计

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









