






前言
在应用运行中,有时候出现OOM异常,通常是因为同时查询或者导出大量数据导致的,而我今天主要想谈谈查询数据占用内存的问题,先看一段简单的单表查询代码,如下
@RestController
@RequestMapping(value = "/test")
public class TestController {
@Autowired
TestMapper testMapper;
@GetMapping(value = "/initData")
public void initData() {
IntStream.range(0, 20000).forEach(x -> {
testMapper.insert(RandomStringUtils.randomAlphanumeric(5000));
});
}
@GetMapping(value = "/list")
public List<Test> list(Integer num) {
List<Test> testList = testMapper.list(num);
return testList;
}
}
public class Test {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
我们先调用initData初始化数据,总共往数据库插入了20000*5000=100,000,000字节的英文数字数据,前端调用list方法获取了大概95.65m的数据,而我们通过VisualVM可以观察到jvm堆中已使用内存由99,198,864个字节增加到551,051,112个字节,总共增加约450,000,000字节的数据,也就是说使用了约实际数据4.5倍的内存.
为什么用了这么多内存, 从代码角度来看,TestMapper实例是Mybaits封装的动态代理,里面调用JDBC的读取数据方法,再反射生成testList列表,最后由ObjectMapper反序列化到响应流,我把整个流程整理关键代码封装在一个方法里面,实际效果基本一样的,如下
@GetMapping(value = "/list2")
public void list2(HttpServletResponse response) throws Exception {
//内存采样1
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, username, password);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT content from test_order limit 20000");
//内存采样2
List<Object> testList = new ArrayList<>();
DefaultObjectFactory defaultObjectFactory = new DefaultObjectFactory();
DefaultObjectWrapperFactory defaultObjectWrapperFactory = new DefaultObjectWrapperFactory();
DefaultReflectorFactory defaultReflectorFactory = new DefaultReflectorFactory();
String id="com.example.memory.mapper.TestMapper.list-Inline";
while (resultSet.next()) {
ResultLoaderMap lazyLoader = new ResultLoaderMap();
final List<Class<?>> constructorArgTypes = new ArrayList<>();
final List<Object> constructorArgs = new ArrayList<>();
String mapKey = id + ":" + null;
String str1 = id + ":" ;
for (Object constructorArg : constructorArgs) {
}
for (Object constructorArg : constructorArgs) {
}
for (Object constructorArg : constructorArgs) {
}
Constructor constructor = Test.class.getDeclaredConstructor();
Object obj = constructor.newInstance();
MetaObject metaObject = MetaObject.forObject(obj, defaultObjectFactory, defaultObjectWrapperFactory, defaultReflectorFactory);
String value = resultSet.getString("content");
metaObject.setValue("content", value);
testList.add(obj);
}
//内存采样3
MappingJackson2HttpMessageConverter mappingJackson2HttpMessageConverter = new MappingJackson2HttpMessageConverter();
Type type = GenericTypeResolver.resolveType(List.class, Test.class);
mappingJackson2HttpMessageConverter.write(testList, type, MediaType.APPLICATION_JSON, new ServletServerHttpResponse(response));
}
JDBC读取数据
在这方法执行过程中,分别用VisualVM工具进行三次内存采样,其中采样1和采样2之间是JDBC读取数据的过程,采样1和采样2对比如下

JDBC读取表行数是20000,与这数量强相关的实例有HeapByteBuffer,TextBufferRow,NativePacketPayload,NativePacketHeader,byte[],行数据都是以byte[5000]的实例存放在TextBufferRow,总共大概占100,000,000字节,再加上读取数据产生的字节缓存,本体数据大概要占用200,000,000字节,其他额外对象占用内存大概合计为9,000,000字节
Mybaits生成对象
采样2和采样3之间是Mybaits处理ResultSet转成List的过程,采样对比如下
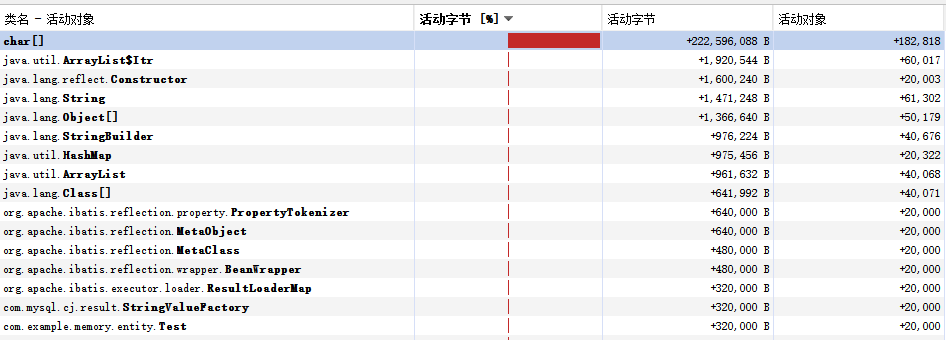
数据行数是20000,与这数量强相关的实例有char[],ArrayList$Itr,Constructor,String,Object[],java.lang.StringBuilder,HashMap,ArrayList,Class,PropertyTokenizer,MetaObject,MetaClass,BeanWrapper,Test,StringValueFactory,ResultLoaderMap,
行数据是以byte[5000]转成String的形式存放Test上,每个String里面有char[5000]数组,而char占用2字节,所以本体数据大概是占用2*5000*20000=200,000,000字节,其他额外占用大概合计36,000,000字节,以上结果都是基于字符都是ascii字符表的,如果一个String里面有一个非ascii字符,那么在byte[]转成String会占用多一倍以上的内存,例如5000个汉字,会占用byte[15000]字符,在new String(byte[15000],0,0)的过程中,产生两个数组char[15000]和char[5000],也就是会占用800,000,000字节
ObjectMapper反序列化
最终前端拿到的是95.65m的json数据,但服务端这里没有增加多少内存,因为ObjectMapper没有将整个对象序列化成String,而是将String里的Char[]写进一个byte[8000],再写进响应流中,源码如下
public class UTF8JsonGenerator
extends JsonGeneratorImpl
{
@Override
public void writeString(String text) throws IOException
{
_verifyValueWrite(WRITE_STRING);
if (text == null) {
_writeNull();
return;
}
// First: if we can't guarantee it all fits, quoted, within output, offline
final int len = text.length();
if (len > _outputMaxContiguous) { // nope: off-line handling
_writeStringSegments(text, true);
return;
}
if ((_outputTail + len) >= _outputEnd) {
_flushBuffer();
}
_outputBuffer[_outputTail++] = _quoteChar;
_writeStringSegment(text, 0, len); // we checked space already above
if (_outputTail >= _outputEnd) {
_flushBuffer();
}
_outputBuffer[_outputTail++] = _quoteChar;
}
protected final void _flushBuffer() throws IOException
{
int len = _outputTail;
if (len > 0) {
_outputTail = 0;
_outputStream.write(_outputBuffer, 0, len);
}
}
}
内存占用公式
- 在JDBC产生的内存中,每条数据产生的额外内存大概是9,000,000/20000=450,而每条数据占用两倍的字节,假设数据大小为X字节,行数为y,那么JDBC占用内存公式为 (x*2+450)*y
- 在mybaits产生的内存中,每条数据产生的额外内存大概是36,000,000/20000=1800字节,而每条数据的每个字符等于两字节,假设数据大小为m字符,行数为y,那么mybaits占用内存公式为 (x*2+m*2+1800)*y,如果数据全是ascii字符表的,那么占用内存公式为(m*2+1800)*y
- 总的占用内存大概是(x*2+450)*y+(m*2+1800)*y,x和m的值可以用mysql的函数计算得出,x=OCTET_LENGTH(字段),m=CHAR_LENGTH(字段),如果x的值小于2048,JDBC改用ByteArrayRow封装行数据,而ByteArrayRow会复制多一次byte[]数组,所以当x<2048时,占用内存公式为(x*3+450)*y+(x*2+m*2+1800)*y
所以最终公式如下
(x*2+450)*y+(m*2+1800)*y+(x<2048?x:0)*y+(x==m?0:x*2)*y
拓展
- 查询差不多100m的英文数字数据,产生了超过450m内存数据,那么问题来了,如果堆内存设置小于450m会不会出现OOM,答案是不一定.对于超出作用域的变量,就可以垃圾回收,只要在一个方法栈里变量数总大小不超过堆内存就行,当然了,如果多线程同时请求,那肯定OOM了.事实上,当我将堆内存调到400M时,执行查询后youngGC增加了9次,fullGC增加了1次
- 内存占用公式的局限性,在jvm中,对象占用的内存不只有数据部分,还有对象头和填充数据,上面的公式为了方便体现查询数据导致数据放大的问题,特意采用超长字符串做例子,如果是其他小字段,例如int等就不适用了,而且计算int等其他类型,换算比例又有所不一样
- 查询对象内存布局可以用
ClassLayout.parseInstance(testList).toPrintable(),查看对象总占用内存可以用RamUsageEstimator.sizeOf(testList)

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









