




 博客提出基于期望最大化的强化学习算法PoWER,用于改进TSM机器人逆运动学模型,提升追踪精度。该算法无需学习率参数,便于利用经验。还使用高斯噪声模拟干扰,搜索参数空间改进模型。此外,介绍了Web of Science检索达芬奇手术机器人运动控制相关内容,包括医疗机器人综述和一种增强学习算法。
博客提出基于期望最大化的强化学习算法PoWER,用于改进TSM机器人逆运动学模型,提升追踪精度。该算法无需学习率参数,便于利用经验。还使用高斯噪声模拟干扰,搜索参数空间改进模型。此外,介绍了Web of Science检索达芬奇手术机器人运动控制相关内容,包括医疗机器人综述和一种增强学习算法。
一、Towards Transferring Skills to Flexible Surgical Robots with Programming by Demonstration and Reinforcement Learning
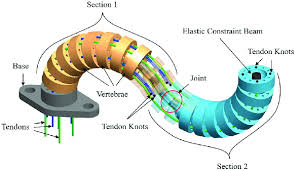

Tendon-driven flexible serpentine manipulators(TSM,肌腱驱动蛇形机器人) 算法
提出一种基于期望最大化的强化学习算法PoWER,改进TSM机器人逆运动学模型提升追踪精度。与策略梯度法相比,PoWER不需要学习率参数(learning rate parameter),采样合并( sampling incorporated)便于利用经验,使快速易于实现。
使用高斯噪声模拟模型不确定性和干扰。PoWER搜索参数空间改进干扰模型并在线最大化奖励函数(maximize the reward function on line ),使收敛到标准逆运动学模型。
二、Web of Science 检索 Da Vinci surgical robot + motion control
1、Review of emerging surgical robotic technology
医疗机器人综述
2、A sequential windowed inverse reinforcement learning algorithm for robot tasks with delayed rewards
一种增强学习算法,以达芬奇为例
3、五页加


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









